








1. Hive是什么
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
这是来自官方的解释。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
先上一张经典的Hive架构图:
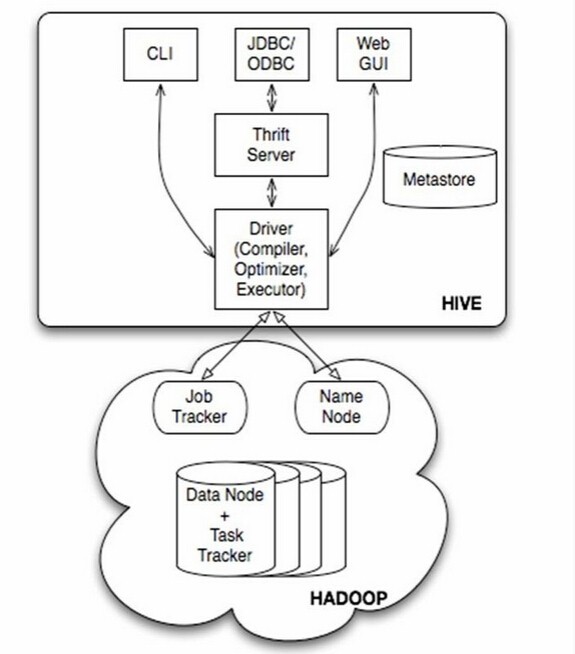
Hive架构图
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
在使用过程中,至需要将Hive看做是一个数据库就行,本身Hive也具备了数据库的很多特性和功能。
2. Hive擅长什么
Hive可以使用HQL(Hive SQL)很方便的完成对海量数据的统计汇总,即席查询和分析,除了很多内置的函数,还支持开发人员使用其他编程语言和脚本语言来自定义函数。
但是,由于Hadoop本身是一个批处理,高延迟的计算框架,Hive使用Hadoop作为执行引擎,自然也就有了批处理,高延迟的特点,在数据量很小的时候,Hive执行也需要消耗较长时间来完成,这时候,就显示不出它与Oracle,Mysql等传统数据库的优势。
此外,Hive对事物的支持不够好,原因是HDFS本身就设计为一次写入,多次读取的分布式存储系统,因此,不能使用Hive来完成诸如DELETE、UPDATE等在线事务处理的需求。
因此,Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
3. Hive的数据单元
- Databases:数据库。概念等同于关系型数据库的Schema,不多解释;
- Tables:表。概念等同于关系型数据库的表,不多解释;
- Partitions:分区。概念类似于关系型数据库的表分区,没有那么多分区类型,只支持固定分区,将同一组数据存放至一个固定的分区中。
- Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
4. Hive的数据类型
既然是被当做数据库来使用,除了数据单元,Hive当然也得有一些列的数据类型。这里先简单描述下,后续章节会有详细的介绍。
4.1 原始数据类型
- 整型
- TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。
- SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。
- INT– 整型,占用4个字节,存储范围-2147483648到2147483647。
- BIGINT– 长整型,占用8个字节,存储范围-2^63到2^63-1。
- 布尔型
- BOOLEAN — TRUE/FALSE
- 浮点型
- FLOAT– 单精度浮点数。
- DOUBLE– 双精度浮点数。
- 字符串型
- STRING– 不设定长度。
4.2 复合数据类型
- Structs:一组由任意数据类型组成的结构。比如,定义一个字段C的类型为STRUCT {a INT; b STRING},则可以使用a和C.b来获取其中的元素值;
- Maps:和Java中的Map没什么区别,就是存储K-V对的;
- Arrays:就是数组而已;
5、Hive常见函数
Hive自带的UDF函数非常多,整理出来有40多页,但是根据八二法则我们只需要掌握其中少数即可满足日常的统计分析需求,其它的需要的时候 Google 或者查询官网即可。
- 5.1、关系运算:
1. 等值比较: =
2. 等值比较:<=>
3. 不等值比较: <>和!=
4. 小于比较: <
5. 小于等于比较: <=
6. 大于比较: >
7. 大于等于比较: >=
8. 区间比较
9. 空值判断: IS NULL
10. 非空判断: IS NOT NULL
10. LIKE比较: LIKE
11. JAVA的LIKE操作: RLIKE
12. REGEXP操作: REGEXP
- 5.2、数学运算:
1. 加法操作: +
2. 减法操作: –
3. 乘法操作: *
4. 除法操作: /
5. 取余操作: %
- 5.3、逻辑运算:
1. 逻辑与操作: AND 、&&
2. 逻辑或操作: OR 、||
3. 逻辑非操作: NOT、!
- 5.4、复合类型构造函数
1. map结构
2. struct结构
3. array结构
- 5.5、复合类型操作符
1. 获取array中的元素
2. 获取map中的元素
3. 获取struct中的元素
- 5.6、集合操作函数
1. map类型大小:size
2. array类型大小:size
3. 判断元素数组是否包含元素:array_contains
4. 获取map中所有value集合
5. 获取map中所有key集合
6. 数组排序
- 5.7、类型转换函数
1. 二进制转换:binary
2. 基础类型之间强制转换:cast
- 5.8、日期函数
1. UNIX时间戳转日期函数: from_unixtime
2. 获取当前UNIX时间戳函数: unix_timestamp
3. 日期转UNIX时间戳函数: unix_timestamp
4. 指定格式日期转UNIX时间戳函数: unix_timestamp
5. 日期时间转日期函数: to_date
6. 日期转年函数: year
7. 日期转月函数: month
8. 日期转天函数: day
9. 日期转小时函数: hour
10. 日期转分钟函数: minute
11. 日期转秒函数: second
12. 日期转周函数: weekofyear
13. 日期比较函数: datediff
14. 日期增加函数: date_add
15. 日期减少函数: date_sub
- 5.9、条件函数
1. If函数: if
2. 非空查找函数: COALESCE
3. 条件判断函数:CASE...WHEN
- 5.10、字符串函数
1. 字符ascii码函数:ascii
2. base64字符串
3. 字符串连接函数:concat
4. 带分隔符字符串连接函数:concat_ws
5. 数组转换成字符串的函数:concat_ws
6. 小数位格式化成字符串函数:format_number
7. 字符串截取函数:substr,substring
9. 字符串查找函数:instr
10. 字符串长度函数:length
11. 字符串查找函数:locate
12. 字符串格式化函数:printf
13. 字符串转换成map函数:str_to_map
14. base64解码函数:unbase64(string str)
15. 字符串转大写函数:upper,ucase
16. 字符串转小写函数:lower,lcase
17. 去空格函数:trim
18. 左边去空格函数:ltrim
19. 右边去空格函数:rtrim
20. 正则表达式替换函数:regexp_replace
21. 正则表达式解析函数:regexp_extract
22. URL解析函数:parse_url
23. json解析函数:get_json_object
24. 空格字符串函数:space
25. 重复字符串函数:repeat
26. 左补足函数:lpad
27. 右补足函数:rpad
28. 分割字符串函数: split
29. 集合查找函数: find_in_set
30. 分词函数:sentences
31. 分词后统计一起出现频次最高的TOP-K
32. 分词后统计与指定单词一起出现频次最高的TOP-K
- 5.11、汇总统计函数(UDAF)
1. 个数统计函数: count
2. 总和统计函数: sum
3. 平均值统计函数: avg
4. 最小值统计函数: min
5. 最大值统计函数: max
10.中位数函数: percentile
12. 近似中位数函数: percentile_approx
15. 集合去重数:collect_set
16. 集合不去重函数:collect_list
- 5.12、表格生成函数Table-Generating Functions (UDTF)
1. 数组拆分成多行:explode
2. Map拆分成多行:explode
6、Hive 的查询语句 SELECT
在所有的数据库系统中,SELECT语句是使用最多,也最复杂的一块,Hive中的查询语句SELECT支持的语法当然也比较复杂,本文只能尽力去介绍。
6.1 基础查询语法
Hive中的SELECT基础语法和标准SQL语法基本一致,支持WHERE、DISTINCT、GROUP BY、ORDER BY、HAVING、LIMIT、子查询等;
语法如下:
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]下面介绍Hive中比较特殊的一些查询语法。
6.2 ORDER BY
ORDER BY用于全局排序,就是对指定的所有排序键进行全局排序,使用ORDER BY的查询语句,最后会用一个Reduce Task来完成全局排序。
SORT BY用于分区内排序,即每个Reduce任务内排序。
看下面的例子:
原表数据为:
hive> select * from lxw1234_com;
OK
5
3
6
2
9
8
1
使用ORDER BY
hive> select * from lxw1234_com order by id;
1
2
3
5
6
8
9
6.3 子查询
子查询和标准SQL中的子查询语法和用法基本一致,需要注意的是,Hive中如果是从一个子查询进行SELECT查询,那么子查询必须设置一个别名。
SELECT col
FROM (
SELECT a+b AS col
FROM t1
) t2另外,从Hive0.13开始,在WHERE子句中也支持子查询,比如:
SELECT *
FROM A
WHERE A.a IN (SELECT foo FROM B);
SELECT A
FROM T1
WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y)还有一种将子查询作为一个表的语法,叫做Common Table Expression(CTE)
with q1 as (select * from src where key= '5'),
q2 as (select * from src s2 where key = '4')
select * from q1 union all select * from q2;
with q1 as ( select key, value from src where key = '5')
from q1
insert table s1
select *;6.4 常见 SQL 查询语句总结
SQL 查询的 6 种常见子句:
where(条件)、having(筛选)、group by(分组)、order by(排序)、limit(限制)、join(关联)
--查询单列或者多列
select user_birthday from user;
--查看行以及行数
select * from your_table limit 3;
--计数:
select count(*) from your_table;
--排序
-- 1.只排一列
select user_birthday from user order by user_birthday;
select user_birthday from user order by user_birthday DESC;
-- 2.多列排序,升序ASC是默认的
select * from user order by user_id,user_birthday;
select * from user order by user_id DESC,user_birthday;
select * from user order by user_id ,user_birthday DESC;
--筛选以及过滤
--过滤行以及查找 where in not like
select user_birthday from user where id>3;
select user_birthday from user where id like '3%';
--去重
select distinct user_birthday from user;
--字符串和数值操作
求和:select sum(field1) as sumvalue from tableA;
平均:select avg(field1) as avgvalue from tableA;
最大:select max(field1) as maxvalue from tableA;
最小:select min(field1) as minvalue from tableA;
--分组和汇总
select count(*) from tableA group by sex;
select id,count(*) from tableA group by sex;
--过滤分组
select id,count(*) from tableA group by sex having count(*)>2;
--嵌套查询
select name,sex,id from tableA where id in (select id from tableB where id >3);
--去重查询,Hive上一个典型表内除重的写法
select ad ,sum(plus),count(distinct name,id) from invites;
--分组和汇总
SELECT a.bar, count(*) WHERE a.foo > 0 GROUP BY a.bar;
SELECT year(ymd), avg(price_close) FROM stocks WHERE exchange = 'NASDAQ' AND symbol = 'AAPL' GROUP BY year(ymd) HAVING avg(price_close) > 50.0;
--多表关联查询:join
SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);
SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id);
--组合查询--以行位单位对表进行操作
select name,sex,id from tableA union select name,sex,id from tableB where tableB.id>3;
select name,sex,id from tableA union all select name,sex,id from tableB where tableB.id>3;
--说明
join 是两张表按 key 关联比对后里面条件相同的部分记录产生一个记录集,
union是产生的两个记录集(字段要一样的)并在一起,成为一个新的记录集※ 更多 SQL 查询实践 case 推荐阅读 Refer 链接 [3] [4] [5]
7、Hive 多表关联查询
在数据统计分析领域,多表 join 关联查询是非常高频的需求和操作,对技术和业务的理解也会稍微高些,所以这一节咱们专门拿出来分析和讲解下。
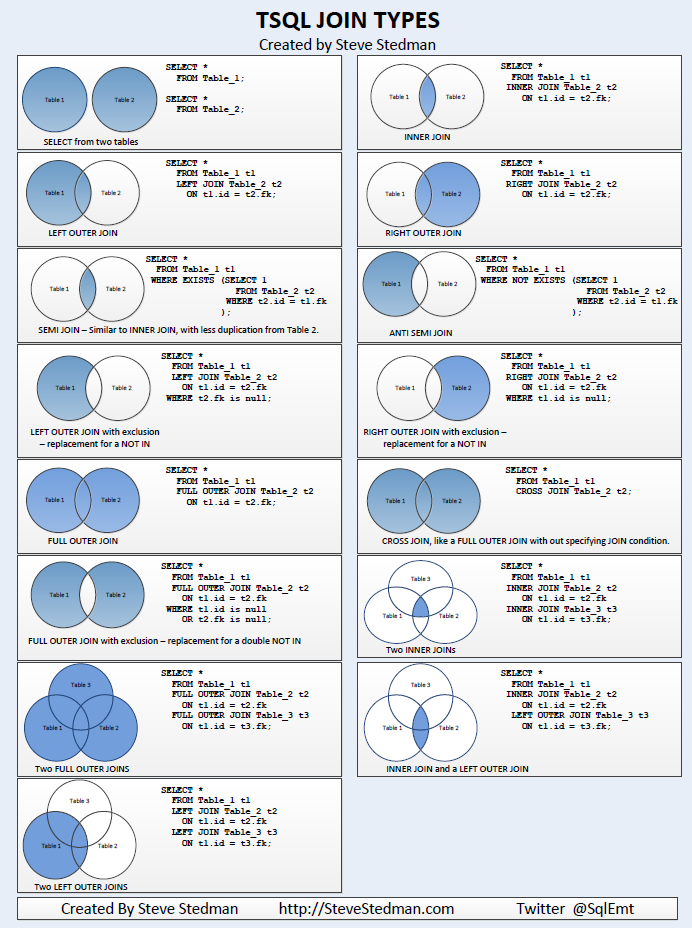
Hive中除了支持和传统数据库中一样的内关联、左关联、右关联、全关联,还支持LEFT SEMI JOIN和CROSS JOIN,但这两种JOIN类型也可以用前面的代替。
注意:Hive中Join的关联键必须在ON ()中指定,不能在Where中指定,否则就会先做笛卡尔积,再过滤。
数据准备:
hive> desc lxw1234_a;
OK
id string
name string
Time taken: 0.094 seconds, Fetched: 2 row(s)
hive> select * from lxw1234_a;
OK
1 zhangsan
2 lisi
3 wangwu
Time taken: 0.116 seconds, Fetched: 3 row(s)
hive> desc lxw1234_b;
OK
id string
age int
Time taken: 0.159 seconds, Fetched: 2 row(s)
hive> select * from lxw1234_b;
OK
1 30
2 29
4 21
Time taken: 0.09 seconds, Fetched: 3 row(s)7.1 内关联(JOIN)
只返回能关联上的结果。
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
join lxw1234_b b
ON (a.id = b.id);
--执行结果
1 zhangsan 30
2 lisi 297.2 左外关联(LEFT [OUTER] JOIN)
以LEFT [OUTER] JOIN关键字前面的表作为主表,和其他表进行关联,返回记录和主表的记录数一致,关联不上的字段置为NULL。
是否指定OUTER关键字,貌似对查询结果无影响。
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
left join lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan 30
2 lisi 29
3 wangwu NULL7.3 右外关联(RIGHT [OUTER] JOIN)
和左外关联相反,以RIGTH [OUTER] JOIN关键词后面的表作为主表,和前面的表做关联,返回记录数和主表一致,关联不上的字段为NULL。
是否指定OUTER关键字,貌似对查询结果无影响。
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
RIGHT OUTER JOIN lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan 30
2 lisi 29
NULL NULL 21
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
RIGHT OUTER JOIN lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan 30
2 lisi 29
NULL NULL 21
7.4 全外关联(FULL [OUTER] JOIN)
以两个表的记录为基准,返回两个表的记录去重之和,关联不上的字段为NULL。
是否指定OUTER关键字,貌似对查询结果无影响。
注意:FULL JOIN时候,Hive不会使用MapJoin来优化。
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
FULL OUTER JOIN lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan 30
2 lisi 29
3 wangwu NULL
NULL NULL 217.5 LEFT SEMI JOIN
以LEFT SEMI JOIN关键字前面的表为主表,返回主表的KEY也在副表中的记录。
SELECT a.id,
a.name
FROM lxw1234_a a
LEFT SEMI JOIN lxw1234_b b
ON (a.id = b.id);
--执行结果:
1 zhangsan
2 lisi
--等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
WHERE a.id IN (SELECT id FROM lxw1234_b);
--也等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
join lxw1234_b b
ON (a.id = b.id);
--也等价于:
SELECT a.id,
a.name
FROM lxw1234_a a
WHERE EXISTS (SELECT 1 FROM lxw1234_b b WHERE a.id = b.id);
7.6 笛卡尔积关联(CROSS JOIN)
返回两个表的笛卡尔积结果,不需要指定关联键。
SELECT a.id,
a.name,
b.age
FROM lxw1234_a a
CROSS JOIN lxw1234_b b;
--执行结果:
1 zhangsan 30
1 zhangsan 29
1 zhangsan 21
2 lisi 30
2 lisi 29
2 lisi 21
3 wangwu 30
3 wangwu 29
3 wangwu 21
Hive中的JOIN类型基本就是上面这些,至于JOIN时候使用哪一种,完全得根据实际的业务需求来定,但起码你要搞清楚这几种关联类型会返回什么样的结果。
除非特殊需求,并且数据量不是特别大的情况下,才可以慎用CROSS JOIN,否则,很难跑出正确的结果,或者JOB压根不能执行完。
经验告诉我,Hive中只要是涉及到两个表关联,首先得了解一下数据,看是否存在多对多的关联。
7.7 图解 Join 类型
8、SQL性能优化
一定要注意SQL需要带上分区以及条件,而且分区必须位于 where 后第一个条件的位置:
-- 错误:没带分区以及业务逻辑条件
SELECT
cilentTime,
actiontype
FROM
defaultdb.t_lmmarking;
-- 错误:没带分区
SELECT
cilentTime,
actiontype
FROM
defaultdb.t_lmmarking
WHERE
actiontype='uploadFail' limit 10;
-- 错误:没带业务逻辑条件,以及结果集行数限制
SELECT
cilentTime,
actiontype
FROM
defaultdb.t_lmmarking
WHERE
DATE='2017-03-17';
-- 正确,如果要全量结果,可以去掉 limit 10,如果结果有很多,则需要考虑浏览器或笔记本奔溃的风险
SELECT
cilentTime,
actiontype
FROM
defaultdb.t_mmarking
WHERE
DATE ='2017-03-17'
AND actiontype='uploadFail' limit 10;推荐书单:MySQL必知必会
https://item.jd.com/10063118.html?dist=jd?dist=jd

——END——
Refer
[1] LanguageManual UDF
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
[2] 一起学Hive
http://lxw1234.com/archives/tag/learn-hive/page/2
[3] MySQL入门学习笔记——七周数据分析师实战作业
https://zhuanlan.zhihu.com/p/31765353?group_id=921825422153949184
[4] 【一文打尽】SQL 数据分析常用语句
https://blog.csdn.net/xgjianstart/article/details/76468015
[5] 七周成为数据分析师:SQL,从入门到熟练
https://zhuanlan.zhihu.com/p/30443153
[6] sqlfiddle
[7] SQL Tutorial/zh
[8] SQL 练习的前期准备
https://www.jianshu.com/p/f5cfc965fcef
[9] sql 练习(五)
https://www.jianshu.com/p/a99ed9a0adfb















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









