






数据分析是所有产品、运营日常工作中重要的部分,除了依赖公司的BI平台或者数据产品经理的支持外,通常也需要大家写一些自定义SQL完成特定查询需求。因此,擅长写SQL能够极大的提升数据分析工作的效率。
本文整理了日常工作使用频次较高的SQL语句模板,如曝光&点击行为、时长、活跃天频、留存,供大家参考。
此外,为了方便SQL零基础的同学能够快速上手,第一二部分会简单介绍下数据埋点系统及SQL语法的基础知识,有基础的同学可以直接跳过。
数据埋点系统
SQL基础语法
常用SQL模板
数据埋点系统
作为有一定工作经验的产品、运营,埋点基本是大家耳熟能详的东西,简言之,即用户行为统计。概括而言,数据埋点系统主要包含四部分:建表、投递、存储、使用(查询及可视化)。
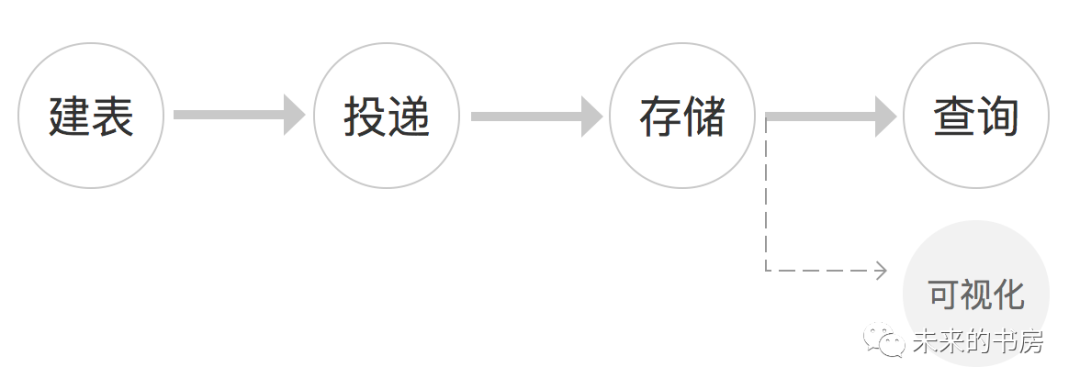 建表:在收集数据之前,需要提前定义好我们想统计信息的字段,并在数据库里建一个空表。
通常由公司的BI平台制定规范,定义好公共字段,然后由产品运营同学申请业务需要统计的自定义字段;
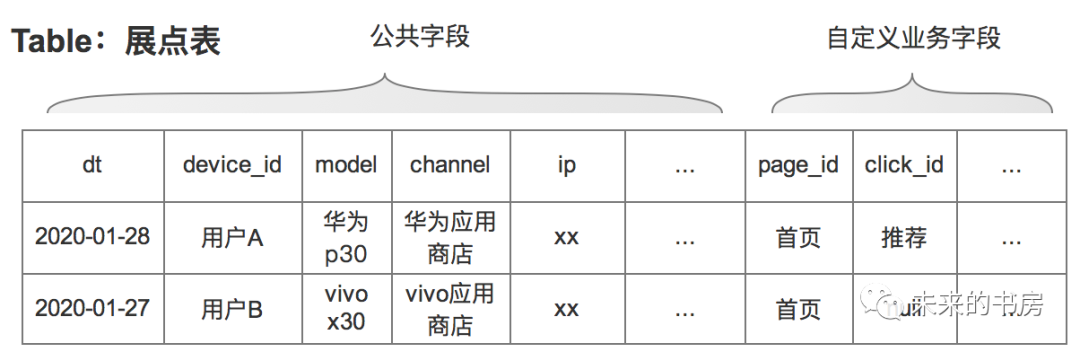
下表为常用的展点表(统计页面曝光及点击行为)示范,公共字段统计用户基础信息,如日期、设备信息、渠道信息等;自定义字段因需求而不同,展点表里会包含展示页面id、点击事件id等;
建表:在收集数据之前,需要提前定义好我们想统计信息的字段,并在数据库里建一个空表。
通常由公司的BI平台制定规范,定义好公共字段,然后由产品运营同学申请业务需要统计的自定义字段;
下表为常用的展点表(统计页面曝光及点击行为)示范,公共字段统计用户基础信息,如日期、设备信息、渠道信息等;自定义字段因需求而不同,展点表里会包含展示页面id、点击事件id等;
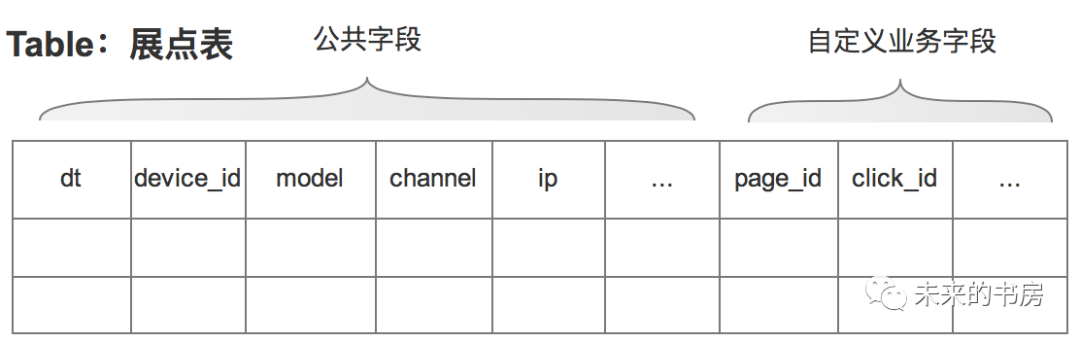 投递:建好埋点表之后,接下来就是产品将统计需求提交给开发,需求里会定义清楚什么时机下投递用户产生的什么信息。比如用户访问app首页时,投递该页面的访问信息;点击首页的推荐按钮时,投递‘推荐’的点击行为,每一次投递均包含一些公共字段,便于唯一标识一个设备或用户。下面为示范:
投递:建好埋点表之后,接下来就是产品将统计需求提交给开发,需求里会定义清楚什么时机下投递用户产生的什么信息。比如用户访问app首页时,投递该页面的访问信息;点击首页的推荐按钮时,投递‘推荐’的点击行为,每一次投递均包含一些公共字段,便于唯一标识一个设备或用户。下面为示范:
 存储:前端开发实现好投递逻辑后,当用户触发指定投递时机时,前端会调用投递的接口(一个http请求),将要投递的数据作为参数上传到BI平台,并由BI后台将投递字段取出,存在事先创建好的埋点表里;
使用:存储好的数据,一方面可供BI平台制作出固定的报表,如统计APP活跃、留存的核心报表;
另一方面,可供大家通过SQL
进行自定义查询。
前者能覆盖的数据分析需求很有限,绝大部分的数据分析需要通过SQL查询来完成。
下面主要是自定义查询部分展开讲解。
存储:前端开发实现好投递逻辑后,当用户触发指定投递时机时,前端会调用投递的接口(一个http请求),将要投递的数据作为参数上传到BI平台,并由BI后台将投递字段取出,存在事先创建好的埋点表里;
使用:存储好的数据,一方面可供BI平台制作出固定的报表,如统计APP活跃、留存的核心报表;
另一方面,可供大家通过SQL
进行自定义查询。
前者能覆盖的数据分析需求很有限,绝大部分的数据分析需要通过SQL查询来完成。
下面主要是自定义查询部分展开讲解。
SQL基础语法
SQL是数据库查询语法,实现通过命令的方式查询出数据库里需要的数据。
单表查询 先介绍下最基本的单表查询相关语法,以上述展点表为例,假设我们希望查询出2020年1月28日访问过首页的用户(设备id),可以通过以下语句。 单表查询语法的模式为:
“从A表,选出满足XX条件的X列、Y列…”
除
了
直接按条件查询某列的数据外,还可以对数据结果进行运算、排重、筛选、排序等操作,如:
单表查询语法的模式为:
“从A表,选出满足XX条件的X列、Y列…”
除
了
直接按条件查询某列的数据外,还可以对数据结果进行运算、排重、筛选、排序等操作,如:
- count,为对满足条件的数据行数进行计数;
- distinct,为对满足条件的数据进行排重;
- If,在满足where命令查询出所有数据里,筛选出某列满足某额外条件的结果;
- group by 对结果按某列分组,列值相同的分为一个组;
- order by 对结果按某列进行排序(默认为升序),倒序为 order by xx desc;
- sum 对结果的某列值进行累加运算;avg对结果的某列值求平均值运算;max/min对结果的某列值求最大/最小值
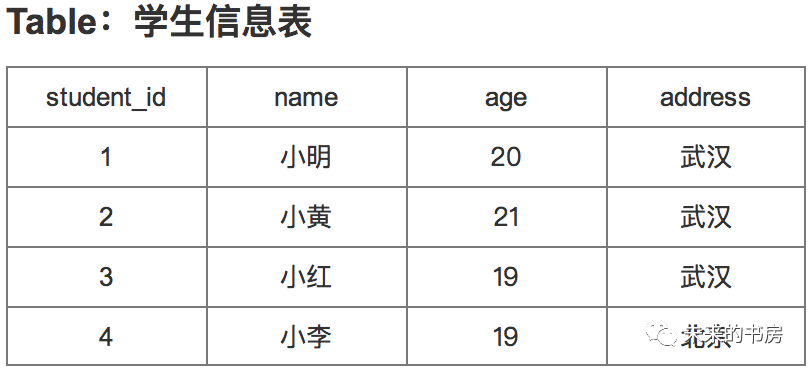 学生信息表表名为:
student_info;包含学生id、姓名、年龄、地址字段。下面举例示范:
Q:
查询总共有多少名学生?
A:
学生信息表表名为:
student_info;包含学生id、姓名、年龄、地址字段。下面举例示范:
Q:
查询总共有多少名学生?
A:
select count(student_id) from student_info;select count(distinct(address)) from student_info;select count(if(age ≥ 20, 1, 0)) from student_info;if(判断条件,result1, result2) 当符合判断条件时返回result1,否则result2;select count(student_id) from student_info where age≥20;select address, count(student_id) from student_info group by address;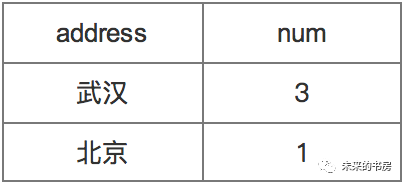
select name, age from student_infoorder by age;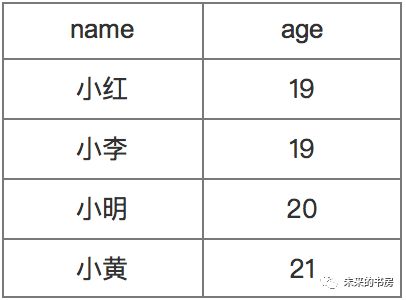
select avg(age) from student_info;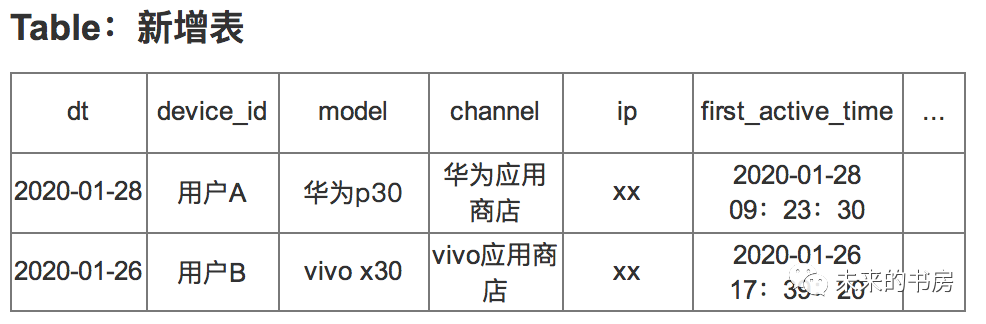 查询方法为:
查询方法为:
 解释:
在原有的查询条件基础之上(2020年1月28日访问过首页),通过关联展点表与新增表的device_id 和日期,筛选出访问当天的新用户。
联表查询语法的模式为:
“通过xx字段关联A表、B表,选出满足xx字段同时存在于A表及B表的用户,且满足XX条件的X列、Y列…”
联表查询除了上述最基础的查询方式,还有:
解释:
在原有的查询条件基础之上(2020年1月28日访问过首页),通过关联展点表与新增表的device_id 和日期,筛选出访问当天的新用户。
联表查询语法的模式为:
“通过xx字段关联A表、B表,选出满足xx字段同时存在于A表及B表的用户,且满足XX条件的X列、Y列…”
联表查询除了上述最基础的查询方式,还有:
- 两个相同的表联查
- left join
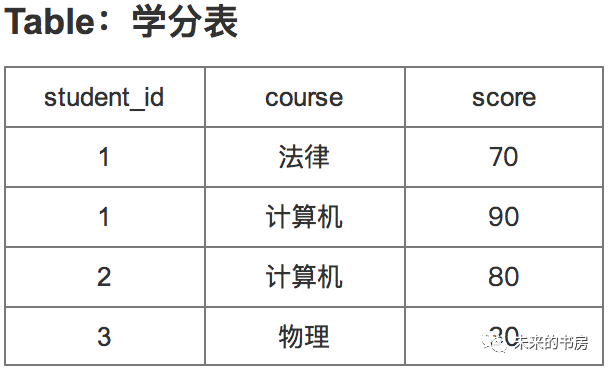 令学生信息表表名及学分表表名分别为:
student_info、
score_info
Q:
查询已选课程的学生姓名、选修课程及学分?
A:
令学生信息表表名及学分表表名分别为:
student_info、
score_info
Q:
查询已选课程的学生姓名、选修课程及学分?
A:
select student_info.name, score_info.course, score_info.scorefrom student_info join score_info on student_info.student_id = score_info.student_id;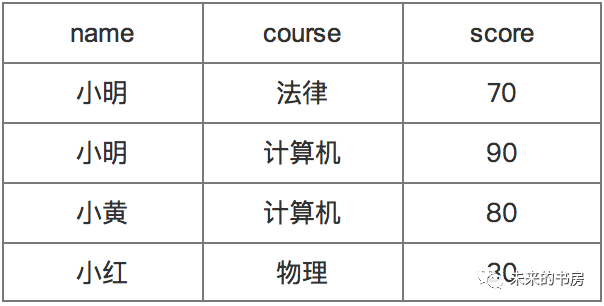
select student_info.name, score_info.course, score_info.scorefrom student_info left join score_info on student_info.student_id = score_info.student_id;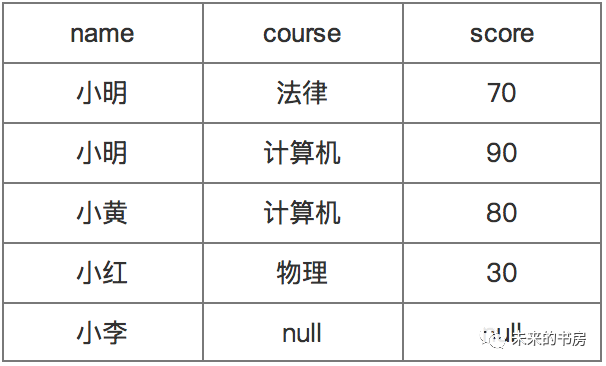
- join为对两个表双向关联,筛选出所关联字段(上述例子中的关联字段为student_id)既存在于左侧表(join左侧的表),也存在于右侧表(join右侧的表)的记录。上面第一个例子里,由于join右侧表,即学分表,不存在小李的student_id,所以最后返回的结果里没有小李的记录;
- left join为对两个表进行左关联,返回关联字段在左侧表所有的记录,不论关联字段是否存在于右侧表中,如果不存在,则该条记录对应的右侧表列值为null(空符号)。上面第二个例子中,即使学分表里不存在小李的student_id,最后的结果仍然会返回此条记录,他对应的course、score则为空值。
常用SQL模板
下面列举几种产品运营工作中经常用到的查询sql模板,由于每个公司、业务的差异性,实际借鉴模板过程中需要结合各自情况对下面sql语句的表名、字段进行替换。
1. 曝光&点击 曝光和点击是最基础的查询应用,仍然以上面的展点表为例进行讲解。 a. 查询点击XX的用户UV/PV
Select count(device_id), count(distinct device_id)from 展点表where dt = "xx" and click_id = "xx"Select count(device_id), count(distinct device_id)from 展点表where dt = "xx" and page_id = "xx"Select count(distinct A1.u)from 展点表 as A1 join ( select * from 展点表 where dt = "2020-01-27" and click_id = "xx" ) A2 on A1.device_id = A2.device_id and A1.dt = A2.dtwhere A1.dt = "2020-01-27" and A1.click_id = "yy"Select count(distinct A.device_id)from 展点表 as A join 新增表 as B on A.device_id = B.device_id and A.dt = B.dtwhere A.dt = "xx" and A.click_id="xx"Select count(distinct B.device_id) new_user, count( distinct if( B.device_id is not null and B.page_id = "xx", B.device_id, null ) ) page_xx_uv, count( distinct if( B.device_id is not null and B.page_id = "yy", B.device_id, null ) ) page_yy_uvfrom 新增表 as B left join 展点表 as A on A.device_id = B.device_id and A.dt = B.dtwhere A.dt = "xx"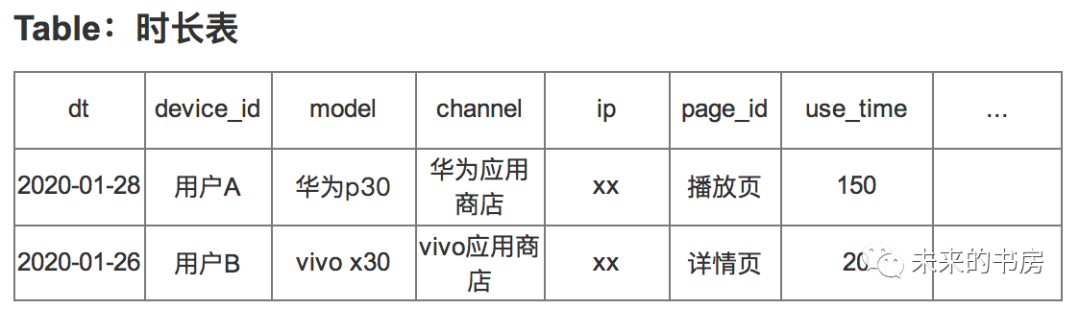 a. 查询时长超XX的用户数
a. 查询时长超XX的用户数
Select count(distinct device_id)from ( select sum(use_time) total_use_time, device_id from 时长表 where dt = "xx" and page_id = "xx" group by device_id ) table_tmp where table_tmp.total_use_time > xxselect sum(use_time) total_time, count(distinct device_id) uv, sum(use_time) / count(distinct device_id) avg_use_timefrom 时长表where dt = "xx" and page_id = "xx"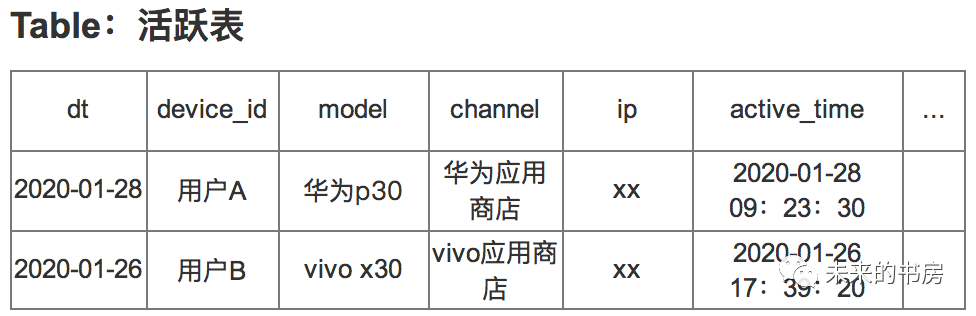 a. 查询活跃天频分布
a. 查询活跃天频分布
Select tmp.tianpin, count(distinct tmp.device_id)from ( select count(distinct dt) tianpin, device_id from 活跃表 where dt >= "xx" and dt <= "xx" group by device_id ) tmpgroup by tmp.tianpinorder by tmp.tianpin descSelect avg(tmp.tianpin)from ( select count(distinct dt) tianpin, device_id from 活跃表 where dt >= "xx" and dt <= "xx" group by device_id ) tmpSelect avg(tmp.tianpin)from ( select count(distinct dt) tianpin, device_id from 活跃表 join( select * from 展点表 where click_id = "xx" and dt = "xx" ) inner_tmp on 活跃表.device_id = inner_tmp.device_id where 活跃表dt >= "xx" and 活跃表.dt <= "xx" group by 活跃表.device_id ) tmpSelect count(distinct A1.device_id) act_uv, count( distinct if(A2.device_id is not null, A2.device_id, null) ) liucunfrom 活跃表 as A1 left join( select * from 活跃表 where dt = "2020-01-02" ) as A2 on A1.device_id = A2.device_idwhere A1.dt = "2020-01-01"Select count(distinct A1.device_id) act_uv, count( distinct if(A2.device_id is not null, A2.device_id, null) ) liucunfrom 新增表 as A1 left join ( select * from 活跃表 where dt = "2020-01-02" ) as A2 on A1.device_id = A2.device_idwhere A1.dt = "2020-01-01"Select count(distinct A1.device_id) act_uv, count( distinct if(A2.device_id is not null, A2.device_id, null) ) liucunfrom 新增表 as A1 left join ( select * from 活跃表 where dt = "2020-01-02" ) as A2 on A1.device_id = A2.device_idwhere A1.dt = "2020-01-01" and A1.channel = "xx" /* channel代表渠道号 */Select count(distinct A1.device_id) act_uv, count( distinct if(A2.device_id is not null, A2.device_id, null) ) liucunfrom 新增表 as A1 join 展点表 on A1.device_id = 展点表.device_id and A1.dt = 展点表.dt left join ( select * from 活跃表 where dt = "2020-01-02" ) as A2 on A1.device_id = A2.device_idwhere A1.dt = "2020-01-01" and 展点表.click_id = "xx"Select count(distinct A1.device_id) act_uv, count( distinct if(A2.device_id is not null, A2.device_id, null) ) liucunfrom 展点表 as A1 left join ( select * from 展点表 where dt = "2020-01-02" and click_id = "xx" ) as A2 on A1.device_id = A2.device_idwhere A1.dt = "2020-01-01" and A1.click_id = "xx"














 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









