






本节书摘来自异步社区《计算机视觉度量深入解析》一书中的第1章1.2节摄像机和计算成像,作者【美】Scott Krig(斯科特·克里格),更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.2 摄像机和计算成像
许多新颖的摄像机配置正在进入商业应用领域,它们使用计算成像方法将原始传感器数据合成为新图像,如深度摄像机和高动态范围摄像机。如图1-6所示,传统的照相机系统使用单个传感器、镜头和光照装置来创建二维图像。然而,计算成像的摄像机可以提供多种光学元件、多种可编程的光照模式以及多个传感器,从而使新的应用(如三维深度感知和图像的加光效果(relight))成为可能,这些应用可充分利用深度信息将图像作为纹理映射到深度图上,并引入新的光源,然后在图形流程中重新呈现该图像。由于可计算摄像机才开始出现在消费设备上,这将成为计算机视觉流程的最前沿,下面将介绍一些常用的方法。
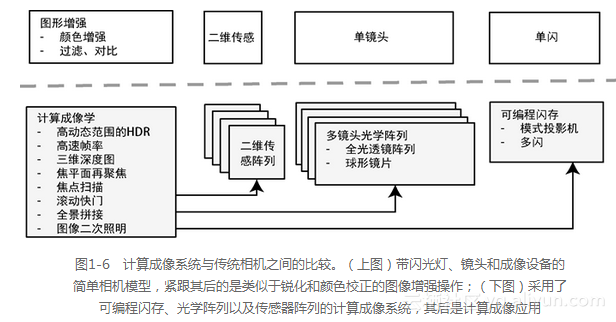
1.2.1 计算成像概述
计算成像学[447,414]为原始图像数据合成新图像提供了方法。一个可计算摄像机能够控制可编程闪光模式投影仪、透镜阵列和多个图像传感器,也可以从原始数据合成新的图像,如图1-6所示。读者如果想深入了解计算成像学和探索当前的研究进展,可以参考哥伦比亚大学的CAVE计算机视觉实验室和Rochester成像技术研究所关于这方面的研究。下面是一些常用的方法和应用。
1.2.2 单像素的摄像机计算
单像素可计算相机可从一系列来自相同场景的单相机检测器像素图像中重建图像。单像素相机的研究领域[103,104]属于压缩感知的研究范围,压缩感知有一些应用已经超出图像处理的研究范围,延伸到诸如模拟-数字转换这样的一些领域。
如图1-7所示,单像素相机可使用微镜阵列(micro-mirror array)或数字微镜器件(digital mirror device, DMD),类似于一个衍射光栅。光栅被安排在一个矩形微镜网格阵列上,它允许网格区域被打开或关闭,从而生产二值网格模式。该二值模式被设计成一个伪随机二值基础集合。网格模式的分辨率可以通过组合邻近的区域(例如2×2或3×3微镜区域的一个网格)来进行调节。
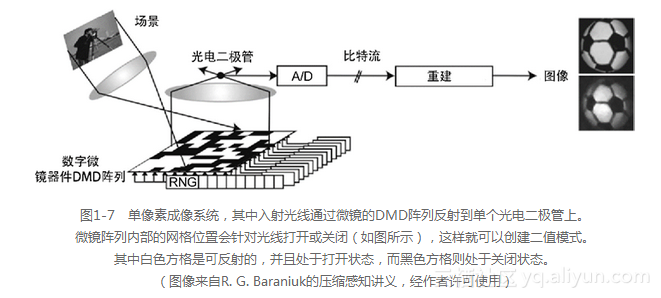
单像素的图像序列可通过一组伪随机微透镜阵列模式拍摄得到,然后从这组图像中重建图像。实际上,由于在重构图像的过程中使用了稀疏的随机采样方法,并且从数学上证明该方法足够有效[103,104],因而重构图像所需的模式样本数量要低于Nyquist频率。网格基础集的采样方法可以直接用于图像压缩,因为仅需要收集一个相对稀疏的模式和样本。由于微镜阵列使用矩形,因而该模式可类比于一组HAAR基函数(欲了解更多信息,请参见图2-20和图6-22)。
当我们在一个规模相对较小的图像集上重建图像时,该图像集由单个摄像机,而不是类似于CMOS或CCD图像传感器中一个的二维阵列检测器拍摄得到,在这种情况下DMD方法具有显著的效果。由于只使用了一个传感器,将该方法应用在除近红外和可见光(由CMOS和CCD传感器成像)之外的波长时非常有前景。例如,DMD方法可以借助对不可见波长敏感的非硅传感器来检测处于不可见波长的隐匿武器或化学物质的辐射情况。
1.2.3 二维可计算摄像机
可编程二维传感器阵列、透镜和光照的新颖配置正在被开发成一种称为可计算摄像机的摄像机系统[424,425,426],计算成像学方法可以增强图像质量,其应用范围涉及数码摄影、军事和工业用途。可计算摄像机从共焦成像学[419]和共焦显微镜学[420,421]借用许多计算成像方法,如使用多种光照模式和多个焦平面图像。通过使用来自单个移动摄像机平台的宽基线数据,他们还将第二次世界大战后发展起来的合成孔径雷达系统方面[422]的研究成果用于创建高分辨率图像和三维深度图。使用多个图像传感器和光学器件获得合成孔径,以及使用晶片规模的集成制造用于视角覆盖的光学元件,这些内容也是目前研究的课题[419]。这里介绍了一些可计算的二维传感器方法,包括高分辨率(high resolution,HR)、高动态范围(high dynamic range, HDR)和高帧速率(high frame rate,HFR)摄像机。
目前流行的商用数码相机,范围在千万像素以上,提供的分辨率接近或超过在35毫米摄像机中所用的高端底片[412],所以图像传感器中像素在尺寸上比得上最高分辨率胶片上的白银颗粒。由于目前的数字方法已取代了大部分的胶片应用并且胶片打印机已经超过了人眼的分辨率,因此,从表面上看,似乎没有什么动力将更高的分辨率用于商业用途。
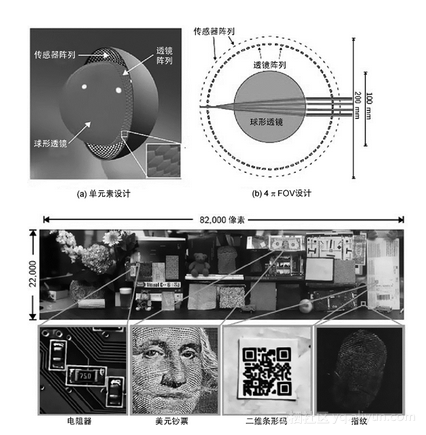
然而,具有十亿级像素的超高分辨率成像设备被设计和制作成图像传感器和镜头的一个阵列,为拍摄后的可计算成像提供了一些优势。一种配置是二维阵列摄像机,它是由图像传感器和相应光学器件的正交二维阵列组成;另一种配置是如图1-8[411,415]所示的球形摄像机阵列,它是由哥伦比亚大学CAVE实验室在DARPA研究项目中制造出来的。
高动态范围(HDR)摄像机[416,417,418]通过组合同一场景的多个在不同曝光环境下所生成的图像,来产生具有更高位分辨率和更好颜色通道分辨率的深像素。这种组合使用了一种合适的加权方案,从而产生一幅具有较高位深度的新图像(如每个颜色通道具有32个像素),它提供的图像已经超出普通商用CMOS和CCD传感器的能力。HDR方法给予了微光和强光相同的成像方式,并且通过自适应的局部方法组合微光和亮光以消除眩光,并创造更均匀、更赏心悦目的图像对比度。
高帧率HFR摄像机[425]能够捕捉快速变化的场景,并生成一组图像,然后使用多重曝光技术来组合这组图像以改变曝光、闪光、焦点、白平衡和景深。
1.2.4 三维深度的摄像机系统
在许多应用中,将三维景深用于计算机视觉的优势被低估,因为计算机视觉主要关注如何从二维图像中提取三维信息,由此引发了各种精度和不变性问题。新型三维描述子被设计用于三维景深的计算机视觉中,我们将会在第6章中讨论。
通过深度图可很容易地将场景分割成前景和背景,以识别和跟踪简单目标。数字摄影的应用程序在三维空间中整合了各种不同的计算机视觉方法,从而使得它们变得更加丰富多彩。将三维深度图的选定区域作为掩码,可增强局部图像的功能(如基于深度的对比度、锐化或其他预处理方法)。
如表1-1所示,有多种方法可从图像中提取深度信息。在某些情况下,只需要一个摄像机镜头和传感器,剩下的由软件来完成。需要注意的是,光照方法是许多深度感知方法(如结构光方法)的一个关键组成部分。图1-9显示了如何将传感器、透镜和光照组合在一起,用于深度成像和计算成像。本节将选取几个深度感知方法进行介绍。
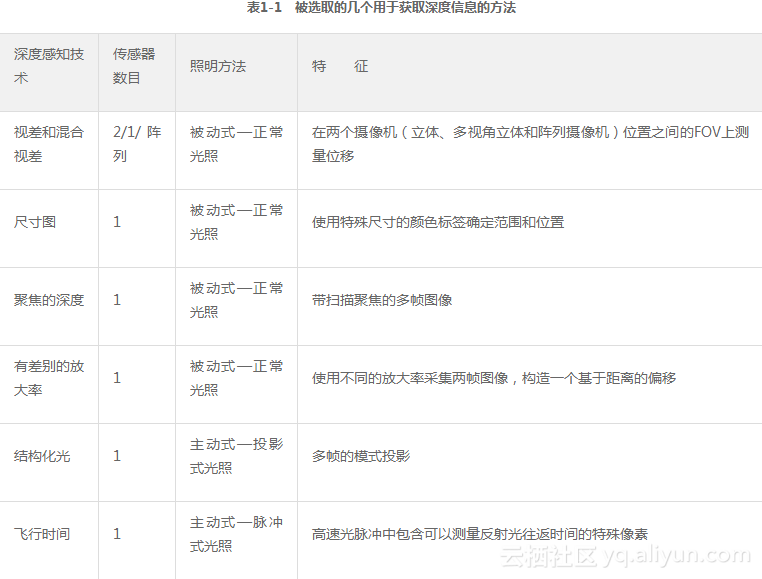

来源:部分来自Aptina的Ken Salsmann[427]提供,作者又添加了一些其他方法。
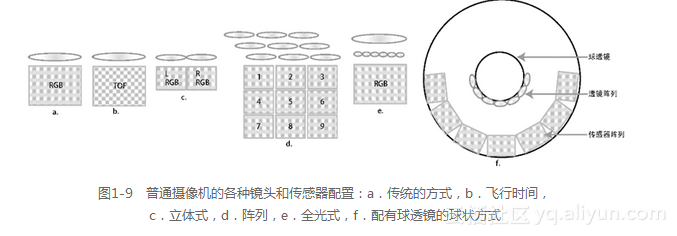
深度感知并不是一个新的领域,几个与庞大的工业应用和财政资源相关的学科都会涉及到它,比如卫星成像、遥感、摄影测量学以及医疗成像。然而,随着商业化的深度感知摄像机的出现,例如,Kinect使得研究生都有足够的预算来使用手机或PC机做关于3D深度或点云数据方面的实验,与深度感知有关的主题在计算机视觉领域引起了研究人员巨大兴趣。
几十年来,多视点立体(multi-view stereo,MVS)深度感知一直用于通过卫星图像(使用雷达和激光雷达成像)和区域性航空考察(使用装配高分辨率摄像机和稳定摄像机平台的特殊用途飞机,包含了与拼在一起的邻域图片相重叠的数字地形图)来计算数字高程地图(digital elevation map,DEM)和数字地形图(digital terrain map,DTM)。与之相关的一个主题是图像拼接,它在计算机视觉中受到了研究者们的关注。关于数字地形测绘方面的文献非常丰富,主要基于某种几何模型和差异计算方法来研究数字地形测绘。此外,在使用CAT和MRI形式的3D医学影像的背后有大量的研究团体,他们使用先进的深度感知方法,并提供基于深度的渲染和可视化。但经常发现在某个领域中非常有名的一些方法,在另一个领域(比如计算机视觉)中被“重新发明”出来,这常常是一个令人感兴趣的现象。这正如所罗门所言,“日光之下并无新事”。在这一节中我们将在计算机视觉的背景下通过引用相关文献来了解深度感知的一些研究进展,也给感兴趣的读者如何进入与之相关的其他学科提供一些建议。
1.2.4.1 双目立体
立体成像[432,433,437]可能是捕捉3D深度图的最基本和最常见的方式,因为有很多方法和算法可选择使用,所以这里参照一些经典文献来简要介绍。立体视觉算法的第一步通过确定摄像机系统的立体标定参数,以参数化现实世界的坐标点到相应的图像坐标点上的投影变换。有立体校准方面的开源软件[2]可供使用。注意,在搜索特征计算差异之前,应该标定左/右图像对。图1-10展示了如何计算立体深度r。
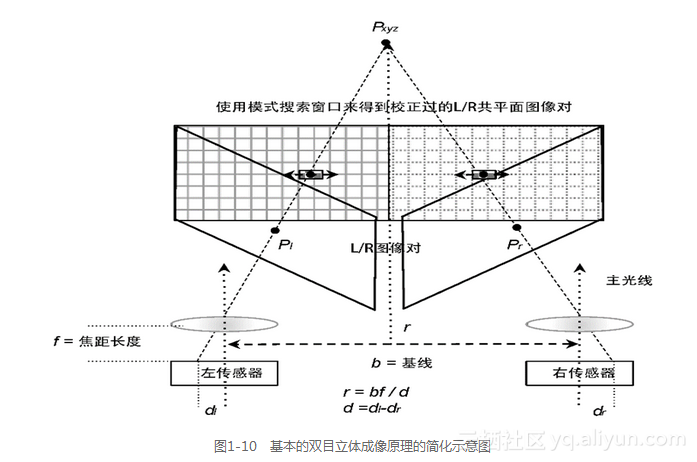
关于立体成像算法和方法的一个非常好的综述请参考Scharstein和Szeliski [440],以及Lazaros [441]的研究成果。投影几何和欧几里德空间相结合产生了立体几何[437],我们在随后的小节中将讨论影响立体几何精度的一些几何问题。Middlebury大学[3]提供了一些关于立体算法的经典在线资源,其中许多新算法都和基准算法进行了比较,并提供了比较结果(还涉及到附录B中所讨论的大量基准数据集)。
立体深度所需的基本几何校准信息包括下面的基本参数。
摄像机校准参数
尽管摄像机的校准在这项工作范围之外,但该校准总共有11个自由参数[435,432] ——即3个旋转参数、3个平移参数和5个固有参数,另外还加一个或多个镜头失真参数,它们用于从二维摄像机空间的像素中重建现实世界坐标系中的三维点。有几个方法可实现摄像机校准,包括著名的校准图像模式或自校准方法[436](这种自校准方法有很多)。外部参数定义了现实世界坐标系中摄像机的位置,而内部参数定义了摄像机图像坐标系中像素坐标之间的关系。其中关键的变量包括在光学器件下图像的中心点或主要点处两个摄像机之间校准后的基准距离,它们的像素大小和长宽比(可通过传感器大小除以每个坐标轴上像素分辨率来得到),摄像机的位置和方向。
基本矩阵或本征矩阵
这两个矩阵之间有一定关系,它们定义了立体摄像机系统的经典几何,以便投影重建[438,436,437]。由它们衍生的一些东西已经超出了这项工作的范围。可以使用两个矩阵中的任何一个,这取决于使用的算法。本征矩阵只使用外部摄像机参数和摄像机坐标,而基本矩阵同时依赖于外部参数和内部参数,它显示了极线(epipolar lines)上立体图形对之间的像素关系。
无论是哪种情况,最终会以在立体图形对中使用投影变换来将二维摄像机点重建成三维点。
立体视觉的处理步骤通常如下。
(1)采集:同时拍摄的左/右图像对。
(2)矫正:将左/右图像对矫正到同一平面上,使得像素行的x坐标和线对齐。几个投影扭曲方法可用于矫正[437]。通过沿x轴对齐图形,矫正将模式匹配问题归结为沿两幅图像之间的x轴进行一维搜索的问题。矫正还可能包括对光学器件进行径向畸变校正(作为一个单独的步骤),然而,许多摄像机在出厂前就已经进行了径向畸变校正。
(3)特征描述:对图像对中的每个像素,会将其周围隔离出一小片区域作为目标特征描述子。有各种各样的方法可用于立体视觉的特征描述[215,120]。
(4)一致性:在对应的图像对中为每个目标特征执行搜索。搜索操作通常进行两次,第一次在右边图像中搜索与左边图像目标特征对应的特征,然后在左边图像中搜索与右边图像目标特征对应的特征。一致性需要精确到亚像素精度以增加景深精度。
(5)三角化:使用三角化[439]来计算匹配点之间的差异性或距离。从很多种方法中挑选一种方法[440],对所有的左/右目标特征匹配进行排序以便找到最佳质量的匹配。
(6)孔填充:对没有找到最佳匹配的像素和相应的目标特征,在深度图的那个位置上会有一个孔。孔的出现或者是因为左/右图像对中的一个特征发生遮挡现象,或者一开始特征就不好。可以使用局部区域中邻近像素的插值方法来填充这些孔。
立体深度范围的分辨率从视角来看是距离的指数函数:一般情况下,基线越宽,远距离的深度分辨率越高。对于近距离深度而言,较短的基线会更好(如图1-10和图1-20所示)。人眼的基准或瞳孔间的距离在50毫米与75毫米之间,平均来说,男性的距离为70毫米左右,而女性的距离为65毫米左右。
与之相关的方法是多视点立体方法,它从几个视角使用相同物体的不同基线(如单一或单目相机,或摄像机的阵列)来计算深度。单目多视点,立体和阵列摄像机的深度感知将在本节后面介绍。
1.2.4.2 结构化光线和编码光线
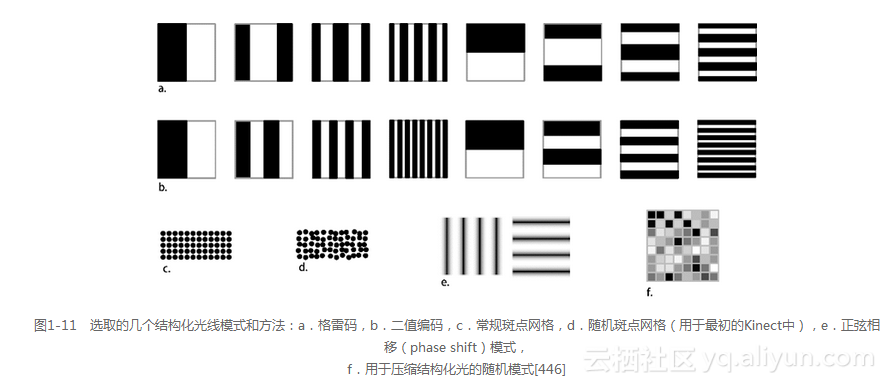
结构化光线或编码光线使用了一种特殊模式,可以将该模式投影到场景和成像的背面,然后通过测量该模式来确定深度(如图1-11所示)。在介绍结构化光线的过程中,会使用下列方法[445]。
空间的单模式方法。在单幅图像中仅需要一个单一的光照模式。
定时复用多模式方法。需要一系列的光照模式和图像,通常使用二值编码或n维的阵列编码,有时也包括在后续帧中进行相位移动或模式抖动以提高分辨率。常见的模式序列包括格雷码、二元编码、正弦编码和其他特殊编码。
例如,在最初微软的Kinect三维深度摄像机中,结构光线由几个稍微不同的微网格模式或红外光的伪随机点构成,在被投影到场景中之后,一旦出现在场景中,就抓拍单幅图来捕获斑点。基于对实际系统和专利应用的分析,最初的Kinect使用下列几种方法计算深度:①红外斑点的大小——更大的斑点和低模糊意味着位置更近,而较小的斑点和更深的模糊程度意味着位置更远;②斑点的形状:圆形显示一个平行曲面,椭圆显示一个倾斜的曲面;③同时使用小区域或斑点的微模式,即分辨率不是太高,但对噪声却非常敏感。使用这种方法从单幅图像就能计算图像深度,而不是需要几个连续的模式和图像。
结构化光使用了多图像方法,包括时序结构化和编码过的模式投影集,如图1-11所示。在多图像方法中,每种模式被依次送入场景进行成像,然后将来自所有模式的深度测量值组合在一起,从而构造最终的深度图。
来自结构化光线的深度测量被用于工业、科学和医疗方面,它能达到非常高的精度,成像对象的大小可达数米,成像精度却可延伸到微米以内。使用模式投影方法以及激光条纹模式方法(利用多个光源光束)构造波长干涉,测量该干涉可以计算距离。例如,常见的牙科设备采用小型手持激光测距仪,为了创建含有缺失部分牙齿区域的高精度深度图,可将该测距仪插入患者的口中,然后CAD/CAM微铣床会基于这些图像创建新的、几乎完全嵌合的冠或填充料。
当然,红外光模式在白天户外的情况下工作得并不是很好,自然光使它们变得像是被冲蚀过的一样。另外,可用的红外发射器强度也受到实用性和安全性的限制。在室内能够有效使用结构化光的距离受IR发射器电量的限制,现实情况下,5米可能是室内红外光的一个限制。Kinect要求当使用统一的恒定红外光照时,当前的TOF方法(飞行时间)的限制范围大约为4米,然而第一代Kinect感应器也要求在类似的深度范围内使用结构光线。
除了创建深度图,结构化光线或编码光线还可以用于光学编码器测量(比如用在机器人和过程控制系统中)。编码器测量径向或线性位置。它们提供了红外照明模式,测量刻度或标线片上的响应,这些响应对于像线性马达与旋转导向螺杆的单轴定位设备很有用。例如,像二值位置码和反射二值格雷码[444]可以很容易地转换成二进制数(如图1-11所示)。格雷码集合中的每个元素在连续元素之间都有一个长度为1的汉明距离。
当处理高镜面反射和阴影时,使用结构化光线方法会碰到一些问题。然而,通过使用模式投影器和场景之间的光漫射器(它使用散射的结构化光线方法[443]来保存光照编码),这些问题会有所减轻。此外,多模式结构光线方法无法处理快速移动的场景,但单模式方法仅仅需要一帧图像,因此它能很好地处理帧运动。
1.2.4.3 光学编码:衍射光栅
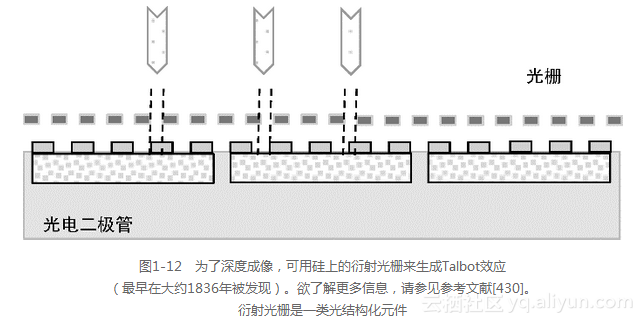
衍射光栅是众多光学编码[447]方法中的一种,它为景深图像创建一组模式,其中光结构化元素,诸如反射镜、光栅、导光板或特殊透镜被放置在接近检测器或透镜的地方。据报道,最初的Kinect系统使用衍射光栅方法来创建随机化的红外斑点照明模式。位于传感器上方的衍射光栅[430,431](如图1-12所示)可以提供角度敏感的像素感知。在这种情况下,光将以不同的角度折射到周围的单元格,这是由衍射光栅或者其他聚束元件(例如光导)的位置决定的。这是考虑到相对于给定的视角,相同的传感器数据会以不同的方式进行处理,从而产生不同的图像。
因为可以通过组合一系列低分辨率图像(它们并行地从多个狭小孔径的衍射光栅抓取)的方式来提供更高分辨率图像,所以该方法允许减小检测器大小。衍射光栅使得有可能从相同的传感器数据生成更为广泛的信息,包括深度信息、增强的像素分辨率、角度位移和图像拍摄后的多个焦平面的聚焦。衍射光栅是一种光照编码装置。
如图1-13所示,可有多种方式来配置光结构化或编码元件,包括以下几种[447]。
对象端编码:贴近主题。
瞳平面编码:在物体一侧,靠近透镜。
焦平面编码:接近检测器。
光照编码:接近光照。
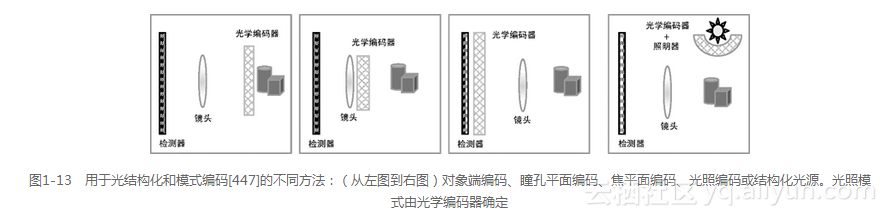
值得注意的是,光照编码在图1-11中显示为结构化光模式,而图1-7中显示的是光照编码的一种变化形式,它使用了一组可打开或关闭的反射镜来构造模式。
1.2.4.4 飞行时间传感器
通过测量红外光往返的时间,可以创建飞行时间(TOF)传感器[450]。TOF传感器是一种测距仪和激光雷达[449]。有几个单芯片TOF传感器阵列和深度摄像机的解决方案比较有效,比如Kinect深度摄像机的第二个版本。其基本概念会涉及在已知时间内红外光传播到场景中,如通过脉冲红外激光,然后在每个像素处测量光返回所需的时间。在一些高端系统中,从亚毫米的精度范围到数百米的精度均有报道[449],这取决于TOF传感器的使用条件、在设计中采用的特殊方法和红外激光发射器使用的功率。
在TOF传感器中,每个像素具有多个激活元件,如图1-14所示,包括红外线传感器以及时序逻辑以便测量从光照到检测红外光的往返时间,另外,光开关用于电子快门和脉冲红外激光器的同步。TOF传感器提供激光测距能力。例如,通过选通电子快门以消除短暂的往返响应,能够有效地减少一些环境条件(如减少雾或烟的反射)。此外,在所需的时间间隔内打开和关闭快门可以测定特定的深度范围(如长范围深度)。
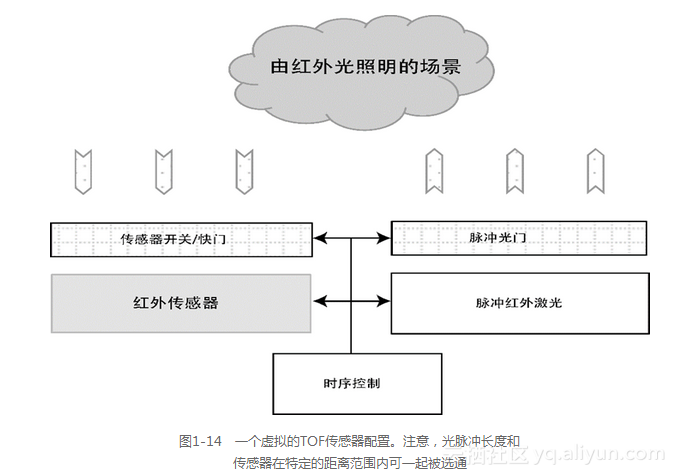
TOF传感器的光照方法可用很短的红外激光脉冲获取第一幅图像,获取第二幅图像时不需要激光脉冲,然后取两幅图像的差就可消除环境红外光的影响。通过使用光子混合器件(PMD)来调制具有RF载波信号的红外光束,可测量返回的红外信号相移以提高其准确性,这在许多激光测距方法中都很常见[450]。在有限的条件下(甚至在100米以上范围),快速的光学选通结合增强型CCD传感器可将其准确度提高到亚毫米范围。然而,单个红外脉冲的传送范围会超过整个场景,并且在成像前可能会被几个表面反射,因此,多个红外线反射会将误差引入到范围图像(range image)中。
由于TOF传感器的深度感知方法被集成到传感器的电子器件中,所以与立体视觉和其他的方法相比,该方法具有非常低的处理开销。然而,在室外的条件下,使用红外光仍有一些限制[448],这可能会影响深度的精度。
1.2.4.5 阵列摄像机
如前面的图1-9所示,一个阵列摄像机包含了几个摄像机,它们通常被放置在一个二维阵列中(诸如一个3×3阵列),为计算成像提供了几个重要的选择。针对便携式设备的商用阵列摄像机开始出现,通过将传感器组合成阵列(如前面所讨论的那样),它们可以使用多视点立体视觉方法来计算视差。阵列摄像机的几个主要优点包括:可通过设置宽基线图像来计算可以穿透和环顾遮挡的三维深度图,对每个传感器的多个低分辨率图像(全景对焦图像)进行插值以获取更高分辨率的图像,以及在一个或多个位置对特定图像进行再聚焦。阵列摄像机的最大孔径等于传感器之间的最宽基线。
1.2.4.6 径向摄像机
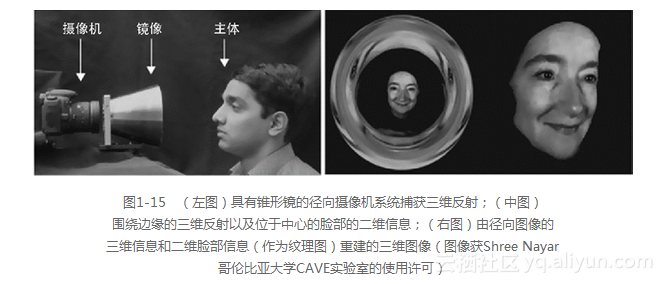
围绕透镜和二维图像传感器的锥形镜或径向镜构成了一个径向摄像机[413],它结合了二维和三维成像。如图1-15所示,径向镜在传感器的中心位置形成二维图像,在传感器的边缘位置形成了一个包含反射三维信息的径向环形图像。基于锥形镜的几何形状将环形信息融入到点云,这样就可以提取深度,并且对于完整的3D重建而言,在图像中心处的二维信息可作为纹理图叠加。
1.2.4.7 全光方法:光场摄像机
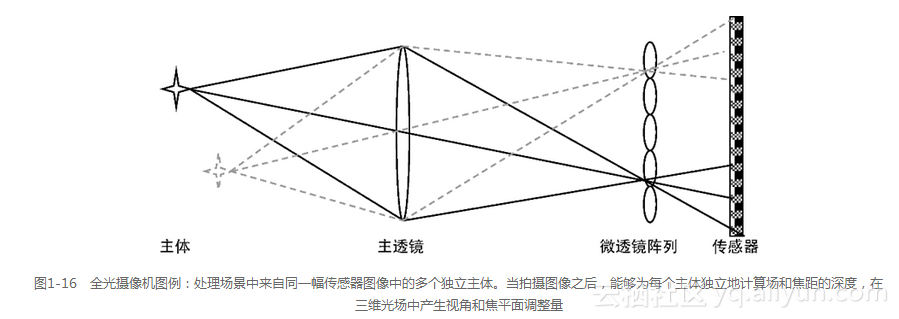
全光方法(plenoptics)创建了一个被称为光场的三维空间,它由多个光学元件创建而成。全光系统使用一组微光学元件和主光学元件对一个四维的光场进行成像,并且在后处理的过程中从光场中提取图像[451,452,423]。全光照摄像机仅需要一个图像传感器(如图1-16所示)。四维光场包含空间中的每个点的信息,并且可以被表示为一个体积数据集,该数据集将每个点当做一个体元或具有三维方向表面、颜色和透明度的三维像素。体积数据可以被进一步处理以产生不同的视图和视角位移,并且允许拍照之后在多个焦平面上聚焦。多片的体积数据可用于隔离透视图和渲染二维图像。通过使用光线跟踪和体积绘制方法[453,454]来渲染光场。
除了光场的体积和表面效果图以外,还可以在频域中通过傅里叶投影切片定理(Fourier Projection Slice Theorem)[455]处理来自三维场或体积的二维切片,如图1-17所示。这是处理三维核磁共振医学成像和CAT扫描数据的基础。Levoy [455,452]和Krig [137]描述了傅里叶投影切片方法在体积和三维范围数据上的应用。基本的算法描述如下。
(1)体积数据通过三维 FFT[4]转化为幅度和相位数据。
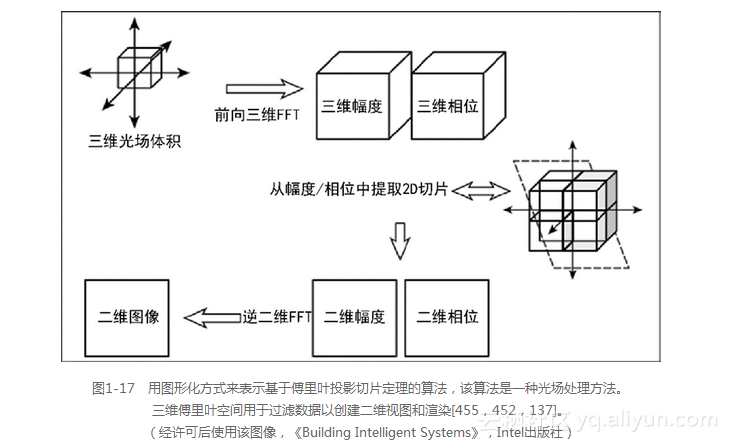
(2)为了便于可视化,生成的三维 FFT数据将被重新处理,并用频率体积表示这些三维FFT。其重新处理的具体过程为将每个立方体转动八分之一圆弧(45度),以便在体积的中心与围绕三维笛卡儿坐标系统中心的数据对齐,这些数据的频率为0。这类似于二维频谱可视化方式,即为了让频谱围绕二维笛卡尔坐标系统的中心位置显示,频谱需要转动四分之一圆弧(90度)。
(3)从与FOV平行的体积中提取平面的二维切片,其中切片穿过体积的原点(中心)。从频域体积数据中提取的切片角度决定了所需的二维视图和景深。
(4)来自频域的二维切片通过执行一个逆二维FFT产生一个对应于选定角度和景深的二维空间图像。















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









