







nutch
1.nutch的相关介绍
1.1 什么是nutch?
Nutch 是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。
Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,接着Nutch进一步演化为两大分支版本:1.X和2.X,这两大分支最大的区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术。
1.x版本是基于Hadoop架构的,底层存储使用的是HDFS(Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。),而2.x通过使用Apache Gora(Apache Gora是一个开源的ORM框架,主要为大数据提供内存数据模型与数据的持久化。目前Gora支持对于列数据、key-value数据,文档数据与RDBMS数据的存储,还支持使用Apache Hadoop来对对大数据进行分析。),使得Nutch可以访问HBase、Accumulo、Cassandra、MySQL、DataFileAvroStore、AvroStore等NoSQL。
1.2 nutch的组成
爬虫crawler和查询searcher。Crawler主要用于从网络上抓取网页并为这些网页建立索引。Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。
1.3 Nutch和Lucene之间的关系
Nutch是基于Lucene的。Lucene为Nutch提供了文本索引和搜索的API。常见的应用场合是:你有数据源,需要为这些数据提供一个搜索页面。在这种情况下,最好的方式是直接从数据库中取出数据并用Lucene API 建立索引。
在你没有本地数据源,或者数据源非常分散的情况下,应该使用Nutch。说道Lucene不得不说solrnutch主要用于采集网页,solr可以作为搜索服务器。nutch+solr可以搭建一个简单的搜索引擎。简单地讲,nutch就是用于分布式采集数据源,solr用于建索引和搜索服务。
1.4nutch的工作原理
Crawler的工作原理:首先 Crawler根据WebDB生成一个待抓取网页的URL集合叫做Fetchlist,接着下载线程Fetcher根据Fetchlist将网页抓取回 来,如果下载线程有很多个,那么就生成很多个Fetchlist,也就是一个Fetcher对应一个Fetchlist。然后Crawler用抓取回来的 网页更新WebDB,根据更新后的WebDB生成新的Fetchlist,里面是未抓取的或者新发现的URLs,然后下一轮抓取循环重新开始。这个循环过 程可以叫做“产生/抓取/更新”循环。
在Nutch中,Crawler操作的实现是通过一系列子操作的实现来完成的。这些子操作Nutch都提供了子命令行可以单独进行调用。下面就是这些子操作的功能描述以及命令行,命令行在括号中。在创建一个WebDB之后(步骤1), “产生/抓取/更新”循环(步骤3-6)根据一些种子URLs开始启动。当这个循环彻底结束,Crawler根据抓取中生成的segments创建索引 (步骤7-10)。在进行重复URLs清除(步骤9)之前,每个segment的索引都是独立的(步骤8)。最终,各个独立的segment索引被合并为 一个最终的索引index(步骤10)。
Injector-》
Generator-》Fetcher-》ParseSegment-》CrawlDb update depth=1
Generator-》Fetcher-》ParseSegment-》CrawlDb update depth=2
Generator-》Fetcher-》ParseSegment-》CrawlDb update-》LinkDbdepth=3
也就是说往复循环Generator-》Fetcher-》ParseSegment-》CrawlDb update 这个过程;
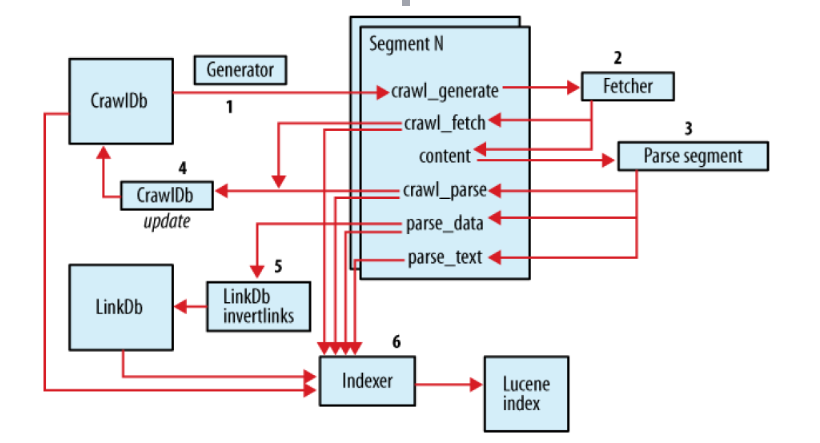
1. 创建一个新的WebDb (admin db -create).
2. 将抓取起始URLs写入WebDB中 (inject).
3. 根据WebDB生成fetchlist并写入相应的segment(generate).
4. 根据fetchlist中的URL抓取网页 (fetch).
5. 根据抓取网页更新WebDb (updatedb).
6. 循环进行3-5步直至预先设定的抓取深度。
7. 根据WebDB得到的网页评分和links更新segments (updatesegs).
8. 对所抓取的网页进行索引(index).
9. 在索引中丢弃有重复内容的网页和重复的URLs (dedup).
10. 将segments中的索引进行合并生成用于检索的最终index(merge).
Nutch的数据文件:
crawldb: 爬行数据库,用来存储所要爬行的网址。crawldb中存放的是url地址,第一次根据所给url:http://blog.tianya.cn进行注入,然后update crawldb 保存第一次抓取的url地址,下一次即depth=2的时候就会从crawldb中获取新的url地址集,进行新一轮的抓取。
linkdb: 链接数据库,用来存储每个网址的链接地址,包括源地址和链接地址。
segments: 抓取的网址被作为一个单元,而一个segment就是一个单元。
http://www.cnblogs.com/huligong1234/p/3515214.html{更详情解释}
2.搭建测试环
安装nutch2+Hbase+Slor4
介绍
Nutch 网络爬虫 与1.x版本的不同在于,nutch2.x不再有bin目录了,有了新的ivy目录用于使用ivy管理nutch。
HBase 是一个分布式,版本化,面向列的数据库,构建在 Apache Hadoop和 Apache ZooKeeper之上。,HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
Solrs 搜索服务器 好比是百度搜索,谷歌的搜索
版本说明
apache-nutch-2.2.1-src.tar.gz
hbase-0.98.19-hadoop2-bin.tar.gz
solr-4.5.1-src.tgz
2.1安装jdk
选用的是 jdk-7u76-linux-x64.tar,进行上传在usr下创建java文件夹
设置权限 chmod u+x jdk-7u76-linux-x64.tar
解压tar -zxvf /usr/java/jdk-7u76-linux-x64.tar
配置环境变量
vim /etc/profile 添加下面2行
export JAVA_HOME=/usr/java/jdk1.6.0_45
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$CLASSPATH
然后重新加载配置文件source /etc/profile
输入java -version看是否成功

2.2安装Hbase
使用的是单机版的HBase
由于Hbase是一个分布式的数据库,所以我们经常与Hadoop联系起来一起用。使用这里就可以不于hadoop一起使用,使用这里就直接安装单击版的Hbase。来在官方的安装和使用http://hbase.apache.org/book/quickstart.html{英文}http://abloz.com/hbase/book.html{中文}。看2.2 HDFS查看http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
选用的是hbase-0.98.19-hadoop2-bin.tar.gz
解压tar -zxvf /usr/java/hbase-0.98.19-hadoop2-bin.tar.gz
进行授权chmod -R 777 hbase-0.98.19-hadoop2

重新加载配置文件

查看官网说明

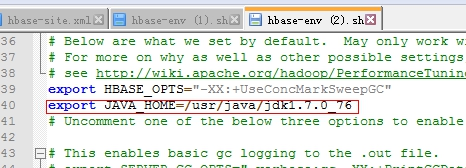
在hbase-env里面添加
export JAVA_HOME=/usr/java/jdk1.7.0_76

编辑 conf/hbase-site.xml 去配置hbase.rootdir,来选择HBase将数据写到哪个目录 .
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:usr/java/hbase-0.98.19-hadoop2/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/java/hbase-0.98.19-hadoop2/zookeeper</value>
</property>
</configuration>我们不需要创建data文件夹habase会帮我们创建,如果我们创建了hbase会帮我们做迁移
You do not need to create the HBase data directory. HBase will do this for you. If you create the directory, HBase will attempt to do a migration, which is not what you want.
启动Hbase
在bin目录下start-hbase.sh
启动后不报错表示成功了

2.3 安装Nutch
在安装Nutch与Hbase结合前,可以先参考官方文档https://wiki.apache.org/nutch/Nutch2Tutorial
选用的是apache-nutch-2.3.1-src.tar.gz
解压tar -zxvf /usr/java/apache-nutch-2.3.1-src.tar.gz
将nutch文件夹进行重命名mv apache-nutch-2.3.1 nutch2
chmod -R 777 nutch2

<property> <name>storage.data.store.class</name> <value>org.apache.gora.hbase.store.HBaseStore</value> <description>Default class for storing data</description></property>

gora.datastore.default=org.apache.gora.hbase.store.HBaseStore

--------------------------------------------------------------------------------------
Conf目录下的文件有:
automaton-urlfilter.txt、gora-accumulo-mapping.xml、hbase-site.xml、nutch- site.xml、regex-urlfilter.txt、suffix-urlfilter.txt、 configuration.xsl、gora-cassandra-mapping.xml、httpclient-auth.xml、parse- plugins.dtd、schema-solr4.xml、domain-suffixes.xml、gora-hbase-mapping.xml、 log4j.properties、parse-plugins.xml、schema.xml、domain-suffixes.xsd、 gora.properties、nutch-conf.xsl、prefix-urlfilter.txt、solrindex- mapping.xml、domain-urlfilter.txt、gora-sql-mapping.xml、nutch-default.xml、 regex-normalize.xml、subcollections.xml。
对于刚开始学习Nutch的人(包括自己),比较重要的文件有三个:nutch-site.xml、gora.properties、nutch-default.xml。nutch-default.xml保存了Nutch所有可用的属性名称及默认的值,当需要修改某些属性值时,可以拷贝该文件中的属性到nutch-site.xml中,并修改为自定义的值。不做任何配置修改的情况,文件nutch-site.xml不包含任何属性和属性值,该文件用于保存用户调整Nutch配置后的属性{nutch2.3中nutch-site.xml设置说明 http://www.aboutyun.com/thread-10080-1-1.html}。gora.properties用于配置Gora的属性,由于Nutch2.x版本存储采用Gora访问Cassandra、HBase、Accumulo、Avro等,需要在该文件中制定Gora属性,比如指定默认的存储方式gora.datastore.default= org.apache.gora.hbase.store.HBaseStore,该属性的值可以在nutch-default.xml中查找storage.data.store.class属性取得,在不做gora.properties文件修改的情况下,存储类为org.apache.gora.memory.store.MemStore,该类将数据存储在内存中,仅用于测试目的。本人在学习Nutch2.2.1的过程中,存储使用了HBase,所以在gora.properties中添加了gora.datastore.default=org.apache.gora.hbase.store.HBaseStore,在nutch-site.xml中添加了
在Nutch的conf目录中有automaton-urlfilter.txt、regex-urlfilter.txt、suffix-urlfilter.txt、prefix-urlfilter.txt、domain-urlfilter.txt几个文件用于实现过滤抓取数据,比如不抓取后缀为gif、exe的文件等,通过修改其中的值可以达到只抓取感兴趣的内容的目的,在一定程度上也有助于提高抓取速度。在抓取过程中,这几个文件不是都起作用的,默认情况下只有regex-urlfilter.txt会达到过滤目的,这一点可以从Nutch-default.xml确认。在进行过滤规则的修改之前,先说明Nutch的过滤器原理。在Nutch中,过滤器是通过插件的方式实现的,插件在nutch-default.xml中定义,更详细看{http://www.aboutyun.com/thread-10080-1-1.html}
还有ivy目录下的ivy.xml文件,下载依赖的jar包。
2.4 安装ant
选用的是apache-ant-1.9.2-bin.tar
解压tar -zxvf /usr/java/apache-ant-1.9.2-bin.tar
将nutch文件夹进行重命名mv apache-ant-1.9.2 ant
配置环境变量

source /etc/profile
在配置nutch-2/runtime/local/conf/nutch-site.xml
在添加如下配置信息
<property><name>http.agent.name</name><value>Your Nutch Spider</value></property><property><name>http.accept.language</name><value>ja-jp, en-us,en-gb,en;q=0.7,*;q=0.3</value><description>Value of the “Accept-Language” request header field.
This allows selecting non-English language as default one to retrieve.
It is a useful setting for search engines build for certain national group.
</description></property><property><name>parser.character.encoding.default</name><value>utf-8</value><description>The character encoding to fall back to when no other information
is available</description></property>
2.5 测试nutch和hbase
在seed.txt中添加要抓取的链接 这里以csdn为例
cd /usr/java/nutch2/conf/
mkdir -p urls
cd urls
touch seed.txt
vim seed.txt

最后开始编译
cd /usr/java/nutch2/
先执行ant命令
编译runtime
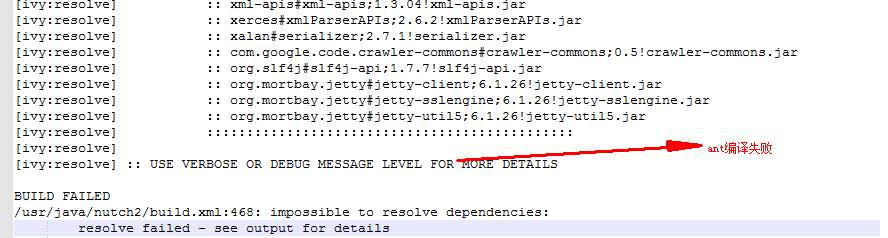
ant runtim
修改nutch-2里面ivy/ivysettings.xml配置文件中 由于镜像文件地址有问题
修改ivysettings.xml 中repository.apache.org值为http://maven.restlet.org/
<property name="repository.apache.org" value="http://maven.restlet.org/" override="false"/>
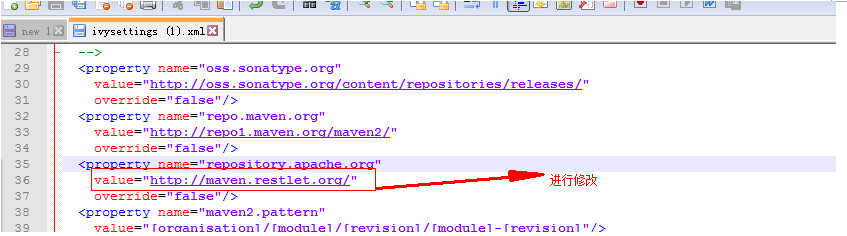
修改后执行
ant runtim
可能会有的jar包下载不下来,多ant runtim几次就好了
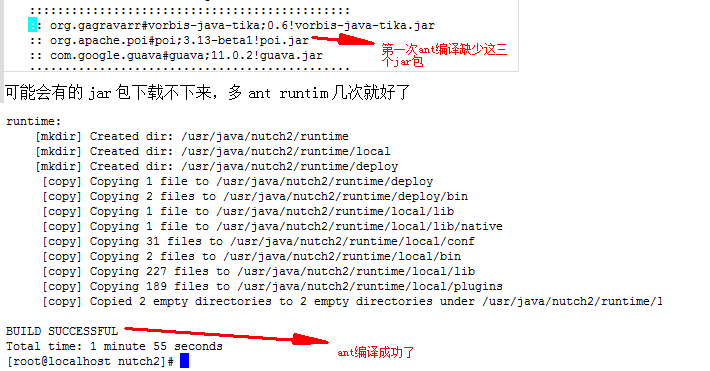

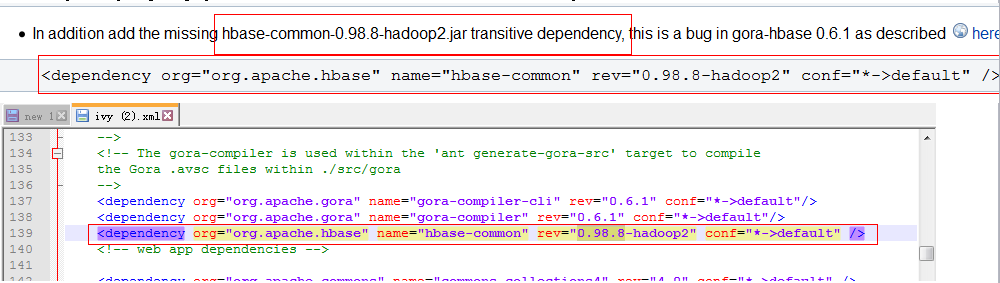
出现这个原因,是由于nutch2.x版本之前不支持hbase,所以ivy.xml配置文件中没有注入连接hbase的jar包所以在ivy.xml中添加这个依赖<dependency org="org.apache.hbase" name="hbase-common" rev="0.98.8-hadoop2" conf="*->default" />
然后再编译runtime
$:ant runtime
编译完成后
$:cd /usr/java/nutch2/runtime/local/bin
--------------------------------------------------------------------------------------
抓取路径最后一个自己配置的是抓取层数
Usage: crawl <seedDir> <crawlID> [<solrUrl>] <numberOfRounds>{抓取的唯一标识第二次抓的不一样会进行内容得更新不是覆盖}{后面会说道}在Nutch-2.x版本中,为了方便用户的使用,爬取流程所涉及的命令整合到了crawl脚本中,使用者可以通过输 入./crawl<seedDir> <crawlID> <solrURL> <numberOfRounds>完成爬取流程,而不必像Nutch-2.1版本中那样,必须一步一步地执行inject、 generate、fetch、parse等命令。对于初学者的我来说,决定不执行傻瓜命令(crawl命令) $ /bin/ nutch inject /usr/java/nutch2/runtime/local/urls $ /bin/nutch readdb
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
抓取 numberOfRounds表明的前缀
$:./crawl /usr/java/nutch2/conf/urls/ numberOfRounds 3
抓取完成后进入hbase shell查看数据
$:hbase shell
查看列表
$:list
查看数据(numberOfRounds_webpage)为表名,以list命令查出的表名为准,这里就以此表名做例子

可以浏览抓取信息$:scan 'numberOfRounds_webpage'
[Nutch]Nutch重要命令使用说明 http://blog.csdn.net/kandy_ye/article/details/51295328
cd /usr/java/nutch2/runtime/local/bin/
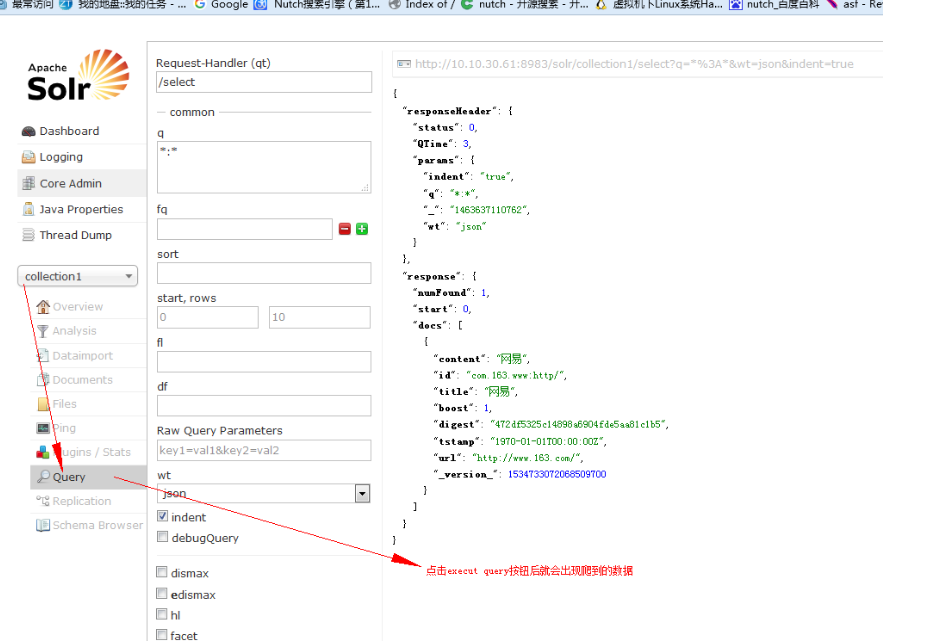
nutch indexchecker http://www.163.com 用来检查索引插件对应着solrindex-mapping.xml
2.6安装solr
选用的是 solr-4.10.4.tgz
拷贝到/usr/java目录
tar -zxvf solr-4.10.4.tgz
chmod -R 777 solr-4.10.4
进入到example文件夹
cd /usr/java/solr-4.10.4/example/
启动solr
java -jar start.jar
第二种是在bin/solr start
关闭bin/solr stop -p 8983

http://localhost:8983/solr默认端口号是8983
表示安装启动成功
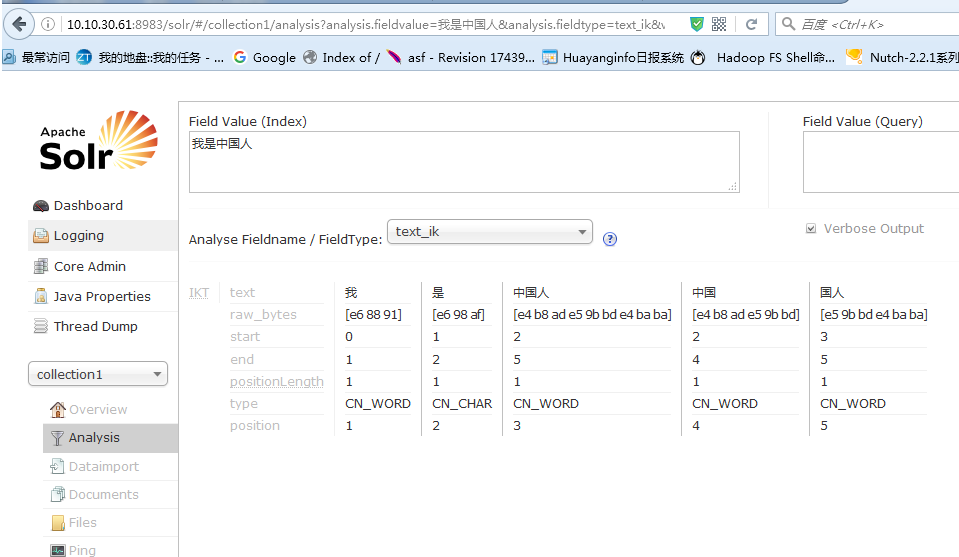
测试了一下原代的切词器,效果是将切成一个一个字,不是想要的效果,后期再改
解压后的文件夹及文件介绍

contrib:Solr服务独立运行相关依赖包
dist:可独立运行的war和solr服务运行相关jar包
docs:Solr的相关文档
example:提供的Solr的配置案例和基于jetty服务器的可运行的star.jar
solr配合nutch的使用
nutch的conf文件夹有些文件是用于solr索引的,比如schema-solr4.xml、schema.xml。但是我安装的是小版本的,所以里面没用schema-solr4.xml这个约束,所以对其进行了下载,如何将solr和nutch联系起来,就是将schema-solr4.xml配置文件对solr下的schema.xml配置文件进行替换,还要将其放在nutch下的conf一份并且重命名为schema.xm,若不修改则在启动Solr会报找不到schema.xm的错误而无法启动Solr。 /usr/solr-4/example/solr-4.10.4/collection1/conf/schema.xml
直接访问会报错,

加上<field name="_version_" type="long" indexed="true" stored ="true"/>
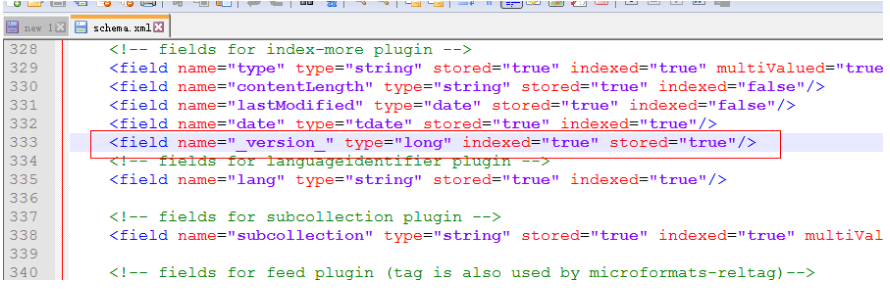
出现这个问题,需要检查下配置文件nutch的配置文件、

Make sure that the plugin indexer-solr is included. Go to the file: conf/nutch-site.xml and in the propertyplugin.includes add the plugin, for instance:确保indexer-solr这个插件存在,去conf/nutch-site.xml进行配置

<property>
<name>plugin.includes</name>
<value>protocol-http|urlfilter-regex|parse-(html|tika)|index-(basic|anchor)|indexer-solr|scoring-opic|urlnormalizer-(pass|regex|basic)</value>
<description>Regular expression naming plugin directory names to
include. Any plugin not matching this expression is excluded.
In any case you need at least include the nutch-extensionpoints plugin. By
default Nutch includes crawling just HTML and plain text via HTTP,
and basic indexing and search plugins. In order to use HTTPS please enable
protocol-httpclient, but be aware of possible intermittent problems with
the
underlying commons-httpclient library.
</description>
</property>
最开始的solr
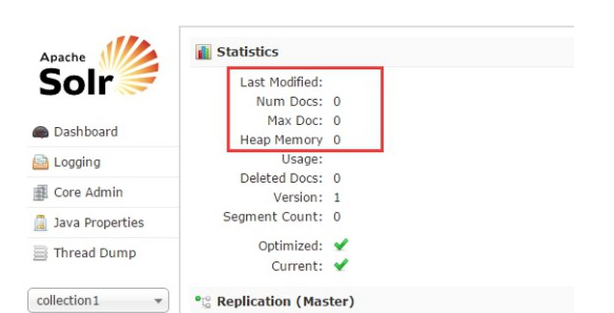
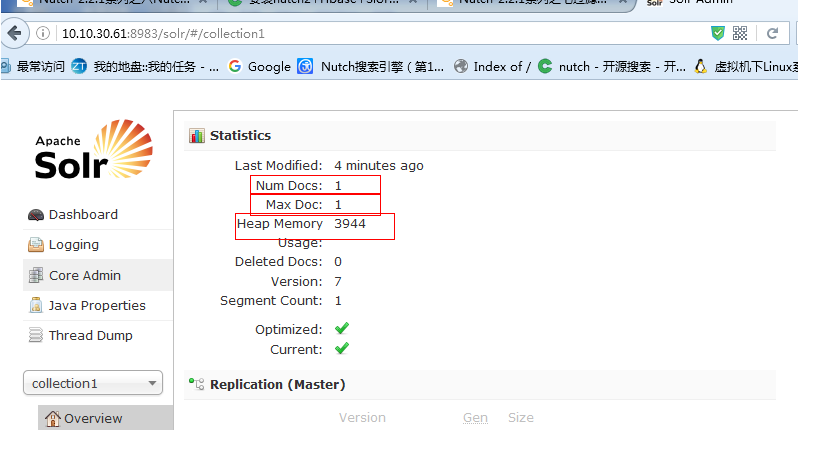
执行爬虫注入操作
Usage: crawl <seedDir> <crawlID> [<solrUrl>] <numberOfRounds>
./crawl /usr/java/nutch2/conf/urls/ sina http://localhost:8983/solr 2
· ~/urls 是存放了种子url的目录
· TestCrawl 是crawlId,这会在HBase中创建一张以crawlId为前缀的表,例如TestCrawl_Webpage。
· http://localhost:8983/solr/ , 这是Solr服务器
· 2,numberOfRounds,迭代的次数
http://10.10.30.61:60010/master-status
3.伪集群的搭建
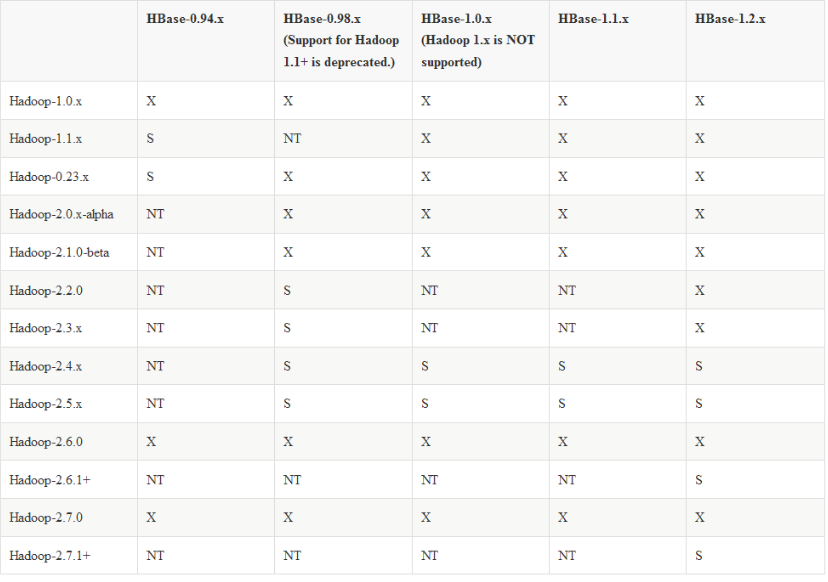

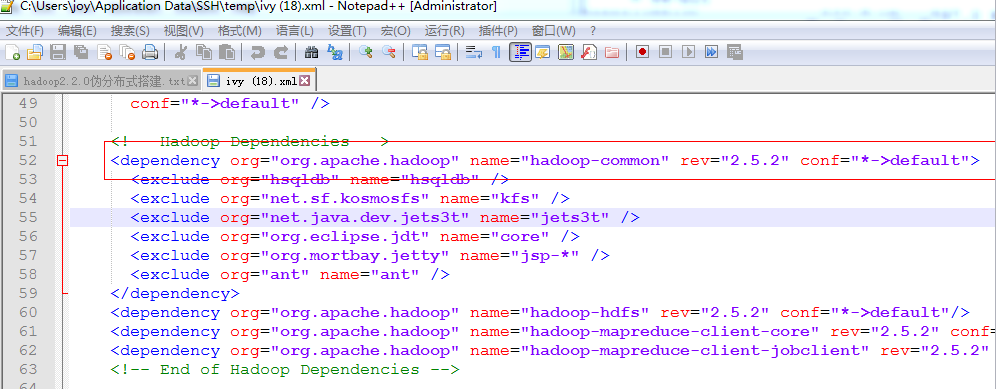
选用的版本是hadoop-2.5.2.tar.gz 将其解压后
将其改名为hadoop mv hadoop-2.5.2 hadoop 如果选的是其他的版本记得修改hadoop-common的依赖
Hadoop可以在单节点上以所谓的伪分布式模式运行,此时每一个Hadoop守护进程都作为一个独立的Java进程运行。
伪分布式模式需要免密码ssh设置,确认能否不输入口令就用ssh登录localhost:
ssh localhost
如果不输入口令就无法用ssh登陆localhost,执行下面的命令(注意:只有拥有root权限的用户才能执行下面命令):
Shell代码
1. ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2. cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys

修改几个重要的配置文件(共5个)
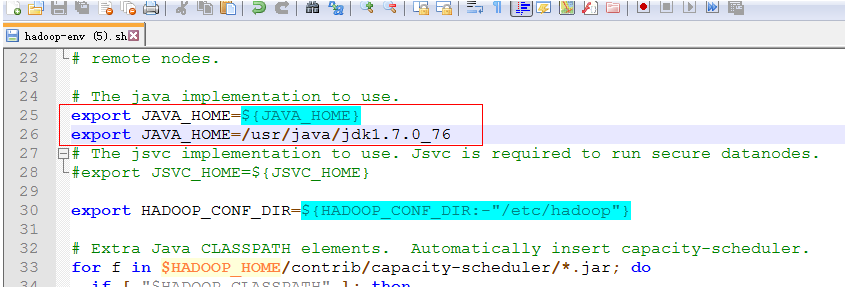
第一个:hadoop-env.sh
添加export JAVA_HOME=/usr/java/jdk1.7.0_76
第二个:core-site.xml

<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/java/hadoop/tmp</value>
</property>
</configuration>
第三个:hdfs-site.xml
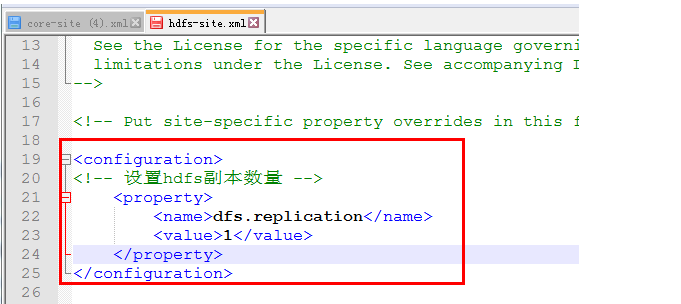
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
第四个:mapred-site.xml.template 需要重命名: mv mapred-site.xml.template mapred-site.xml

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
第五个:yarn-site.xml

<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
将hadoop添加到环境变量
vim /etc/profile
export HADOOP_HOME=/data/java/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile

格式化HDFS(namenode)第一次使用时要格式化
hadoop namenode -format
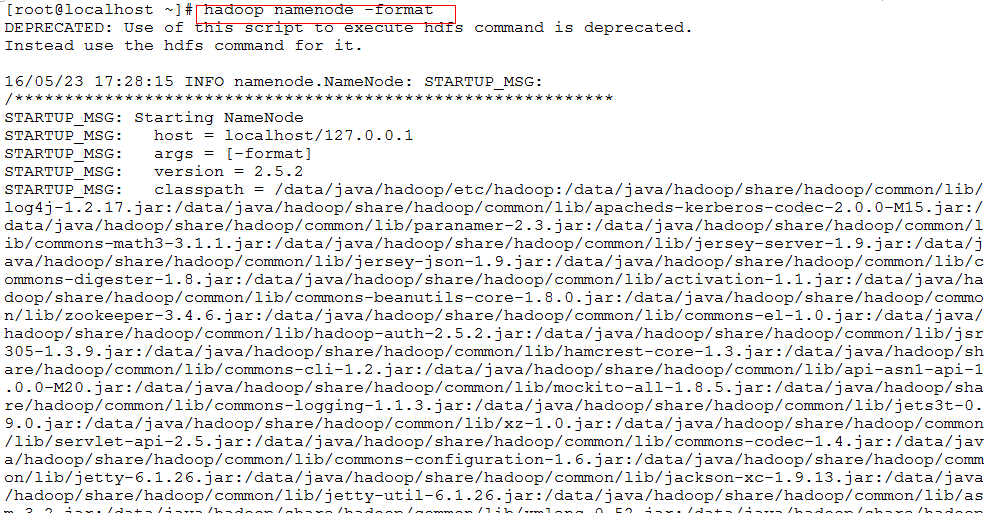
验证是否启动成功
使用jps命令验证 sbin/start-all.sh

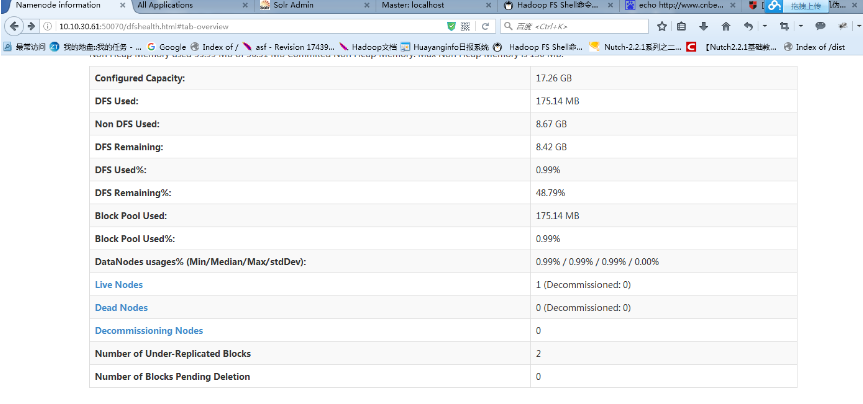
http://10.10.30.61:50070 (HDFS管理界面)
http://10.10.30.61:8088 (MR管理界面)
nutch和hadoop整合
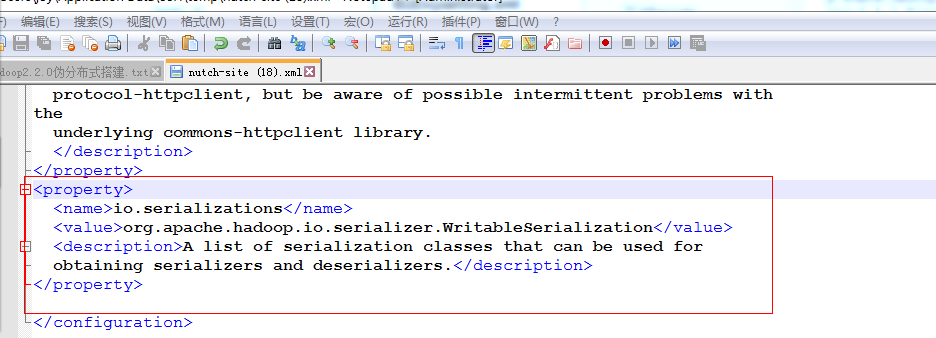
修改nutch-site.xml在单机版基础上进行了修改 添加节点的存储要实现序列化和反序列化
<property><name>io.serializations</name><value>org.apache.hadoop.io.serializer.WritableSerialization</value><description>A list of serialization classes that can be used for
obtaining serializers and deserializers.</description></property>
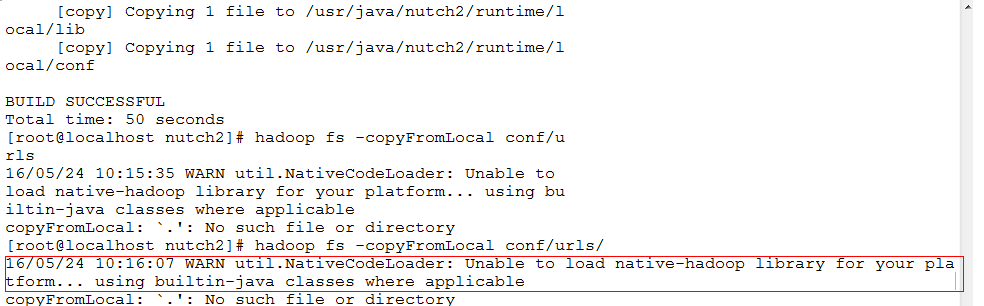
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
由于hadoop下载的默认是32位编译的,我们使用的系统是64位的,搜索要重新进行编译
下载hadoop-native-64-2.5.2.tar将其解压到hadoop下的lib下的native文件夹中
tar -zxvf hadoop-native-64-2.5.2.tar -C hadoop/lib/native/

先进入nutch的deply目录:
cd nutch/runtime/deploy
和在local模式一样 ,我们先建立一个urls目录,并将抓取链接放入url.txt文件里面:
mkdir urls
echo http://www.cnbeta.com > urls/url.txt
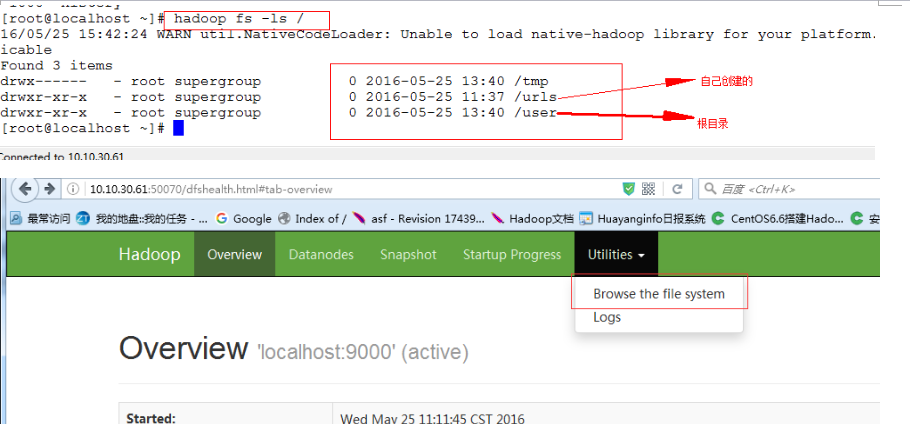
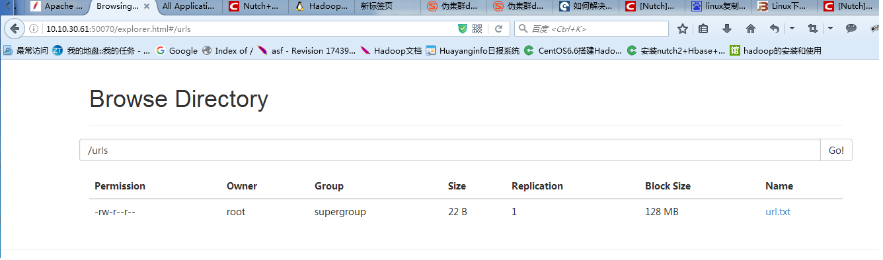
将链接文件放入hadoop的分布式文件系统上:
hadoop fs -put urls /urls
bin/hadoop jar /data/java/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar randomwriter out
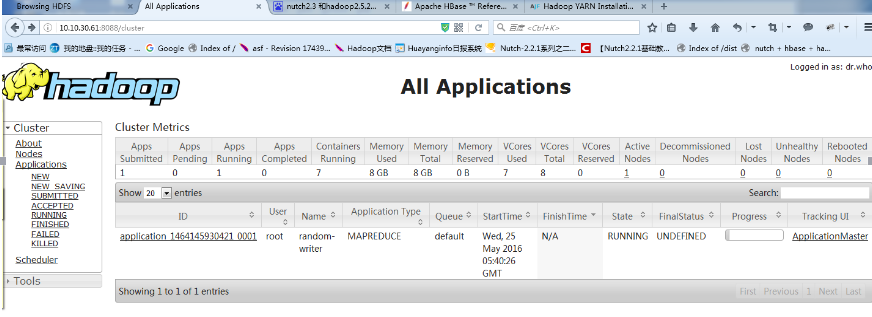
使用的是hadoop的话抓取的路径 cd /usr/java/nutch2/runtime/deploy/bin/
crawl /urls si http://localhost:8983/solr 2


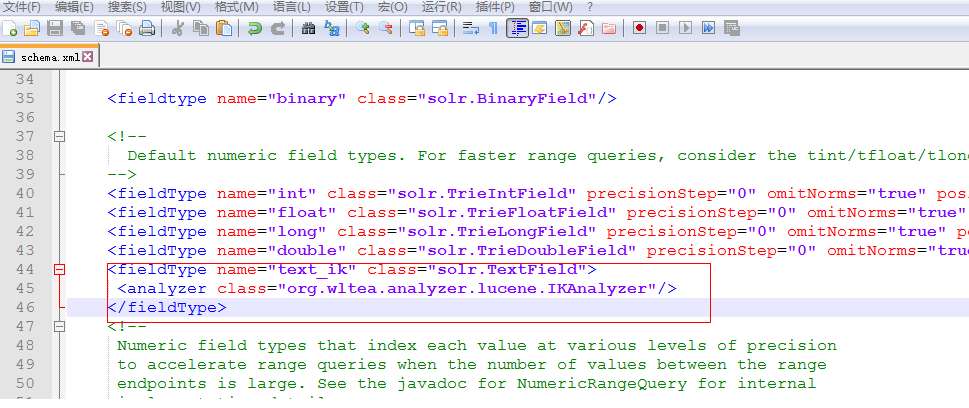
4集成IKAnalyzer中文分词器
1、 将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下;
2、 在schema.xml文件中添加fieldType:
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
3、 下图设置

效果:
1、 修改默认检索的字段名称,df(text)-à custom_field
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">common_text</str> 检索的字段名称
</lst>
</requestHandler>
1、 requestHandler:用来配置执行的方法 name:指定的方法名称 wt:响应的数据格式;df:默认检索的字段。

2、 去掉竞价排名配置(因为需要加载一个xml文件提高效率)

5.将hbase保存在节点上
开始使用的是单机版默认是存储在文件里面的
关闭hbase的情况下
修改hbase-site.xml添加下面字段
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
修改存储的位置 这个存储的文件节点文件夹不用自己创建系统会创建

开启hbase
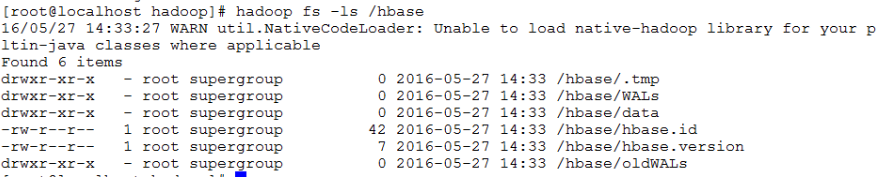
输入hadoop fs -ls /hbase















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









