







本文实践源代码的码云地址: https://gitee.com/MaxBill/HMRP
在上文《hadoop(05)、使用Eclipse连接远程Hadoop集群》中我们主要实践了使用Eclispe开发工具安
装hadoop的开发插件,并且使用hadoop插件连接Hadoop远程集群。本文我们要在上文搭建的hadoop开
发环境的基础上开发Hadoop的MapReduce项目。
一、环境准备
1.hadoop集群
2.安装了hadoop插件的Eclipse
二、创建MapReduce项目
创建MapReduce项目可以通过eclispe的MapReduce插件创建,也可以使用Maven来构建,建议使用Maven来构建,可以更好的管理项目依赖等问题,下面两种方式都会进行:
1.打开Eclipse的File菜单下的New Project视图,选择建立Map/Reduce Project
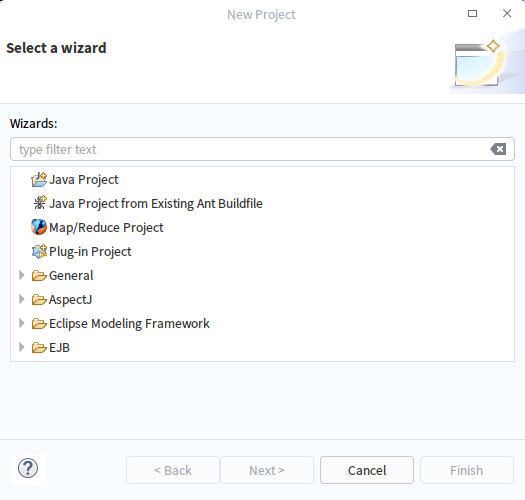
2.新建一个Map/Reduce项目
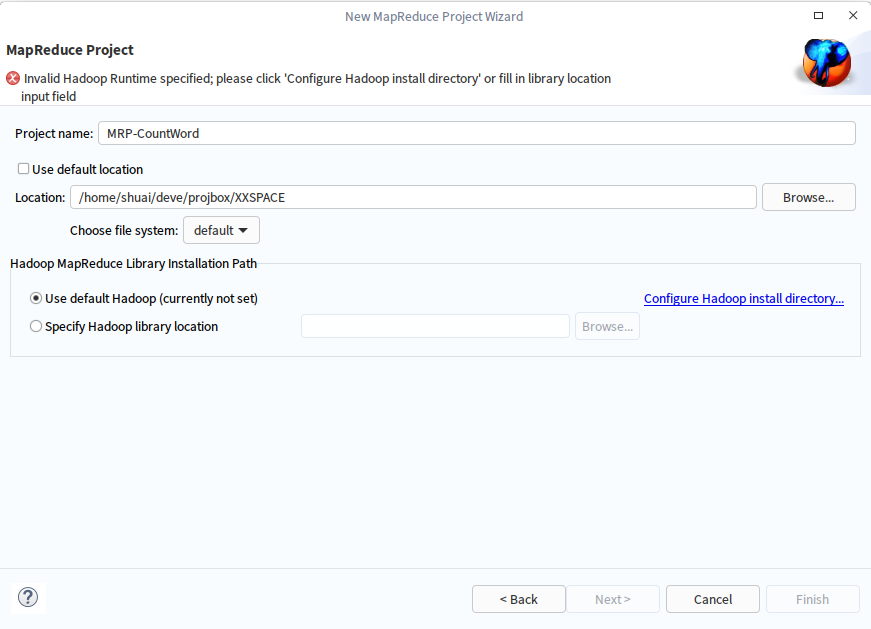
配置默认的hadoop,点击Configure Hadoop install directory...
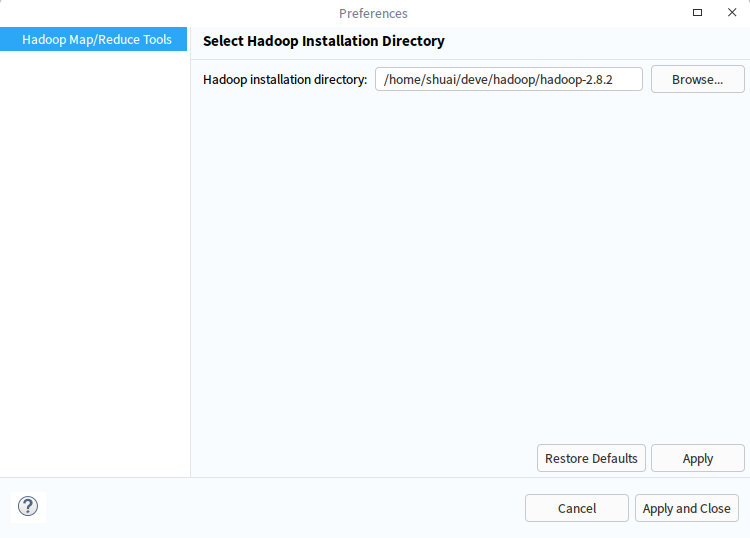
设置完成默认的hadoop,点击next
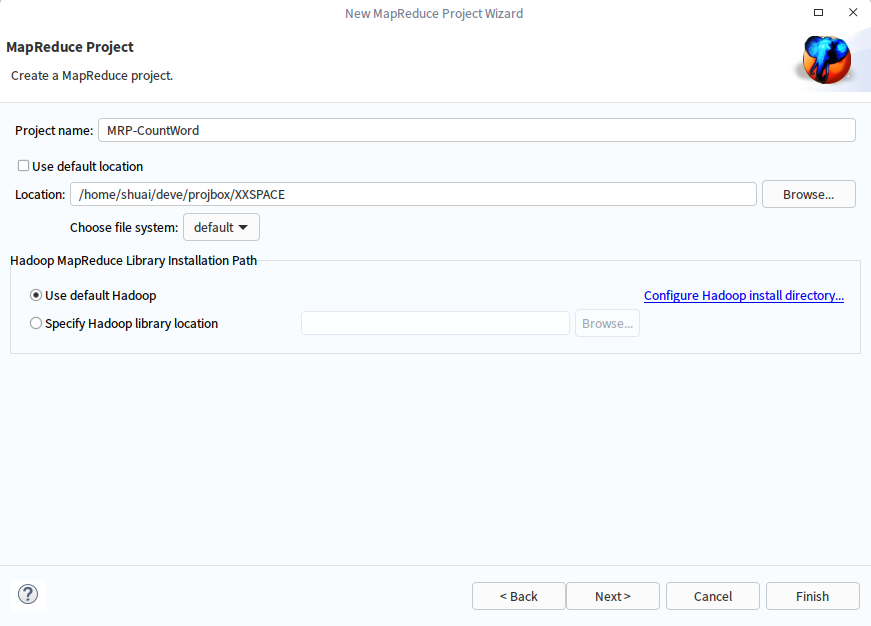
配置项目信息,点击完成,即可创建一个新的Map/Reduce项目
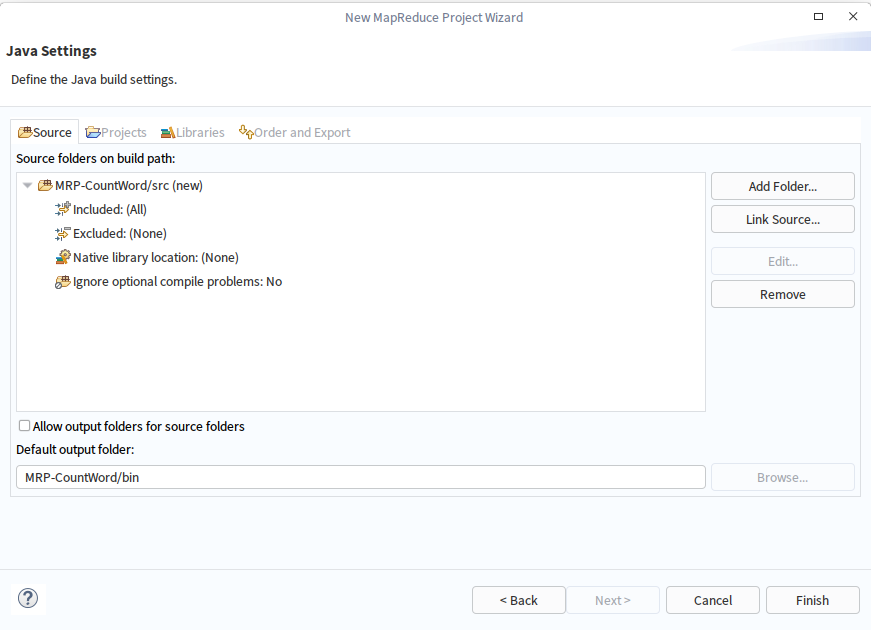
注意:以上方式适合简单的Map/Reduce项目,需要手动管理项目的JAR包,建议使用Maven来构建Map/Reduce项目,文本实际上使用的是以下Maven的方式:
1.创建Maven项目
点击File菜单下的New Project视图,选择建立Maven Project
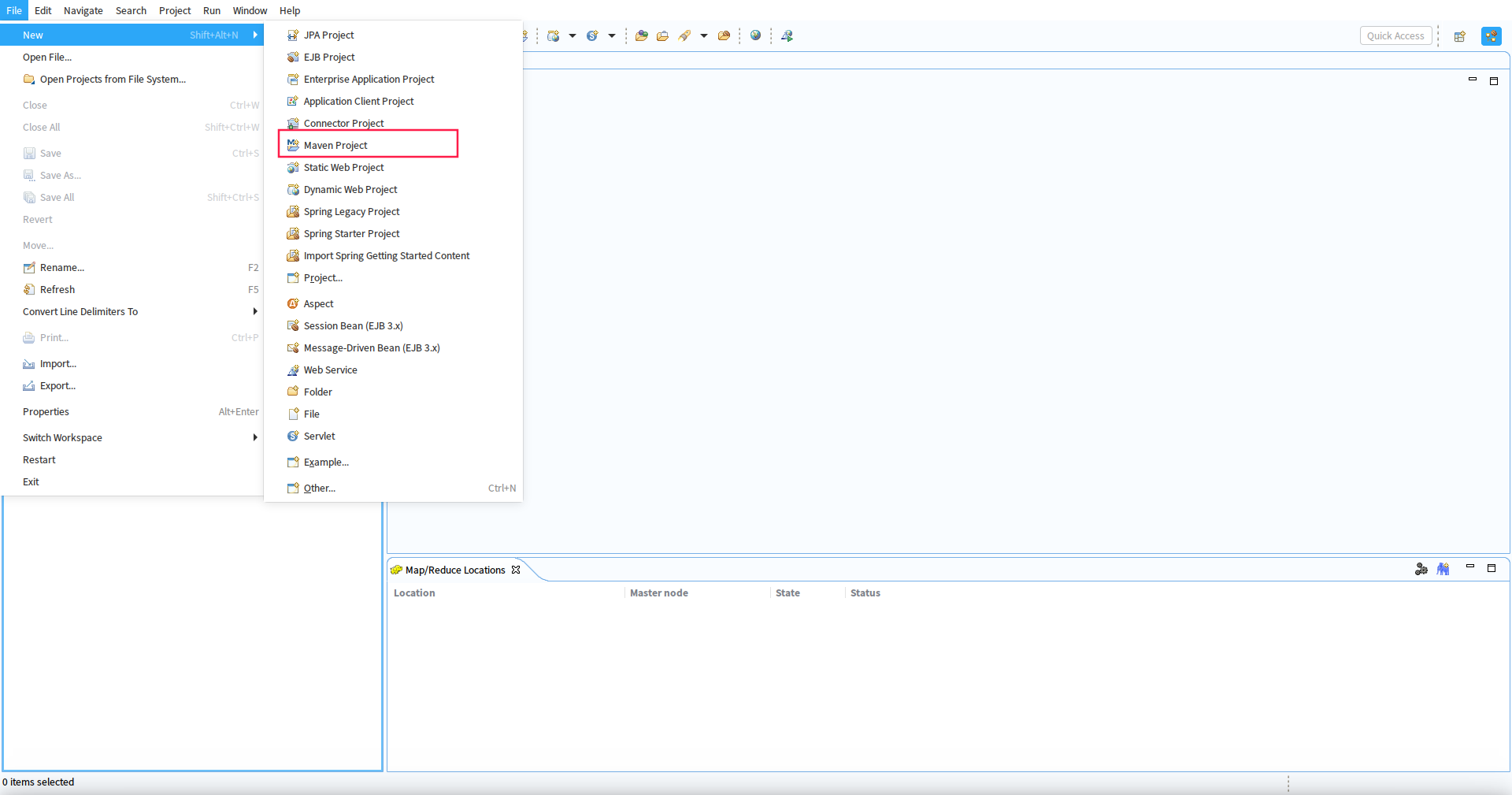
2. 填写项目信息,完成即可
项目结构如下:
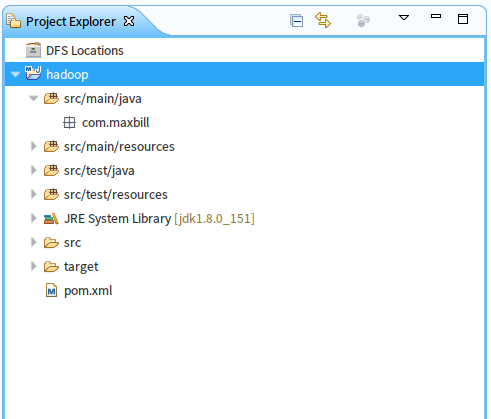
注:代码中项目名重构为HMRP了
三、编写代码
1.在上面创建的Maven项目中添加用到的hadoop开api包依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.2</version>
</dependency>
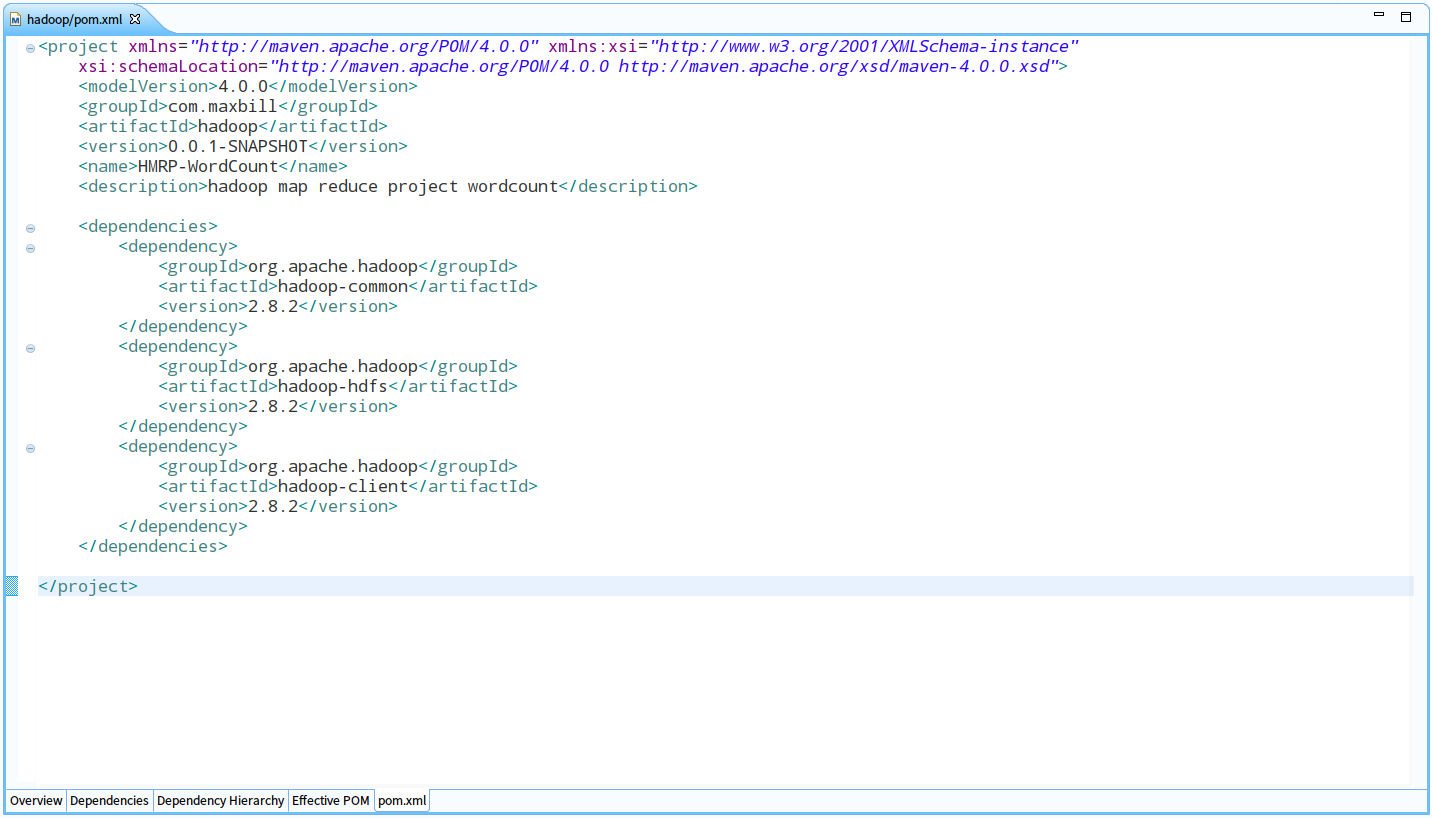
pom.xml如下图:
项目整体结构图如下:
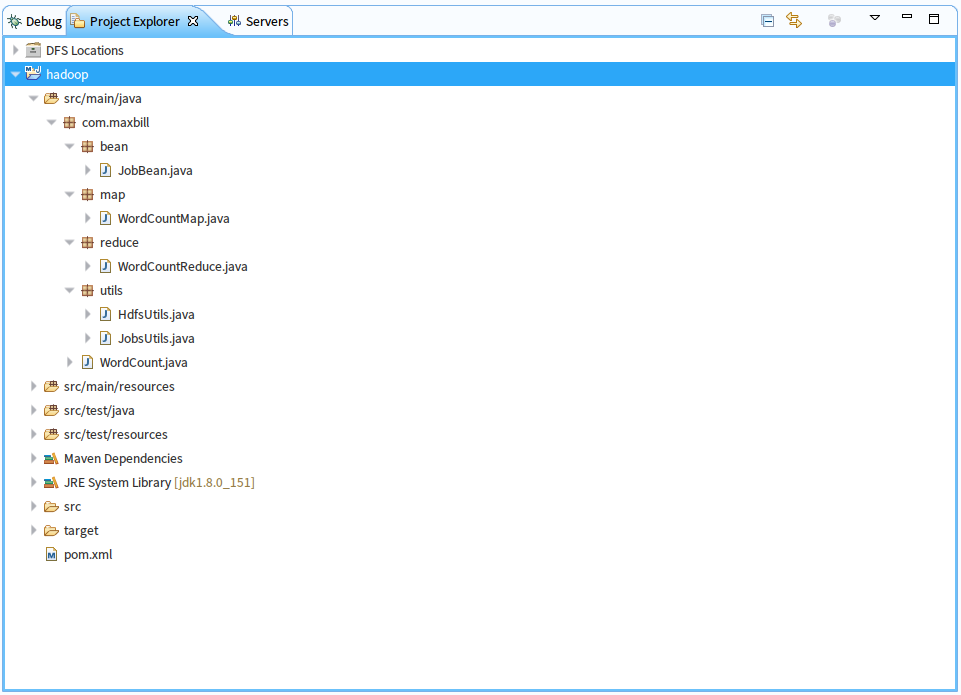
注意:项目个类说明
JobBean:是用来传递作业运行所需参数的BEAN
WordCountMap:我们自己定义的map函数类
WordCountReduce:我们定义的reduce函数类
HdfsUtils:Hdfs操作的工具类
JobsUtils:作业工具类
WordCount:词频统计主类
项目源代码已经上传码云,地址:https://gitee.com/MaxBill/HMRP
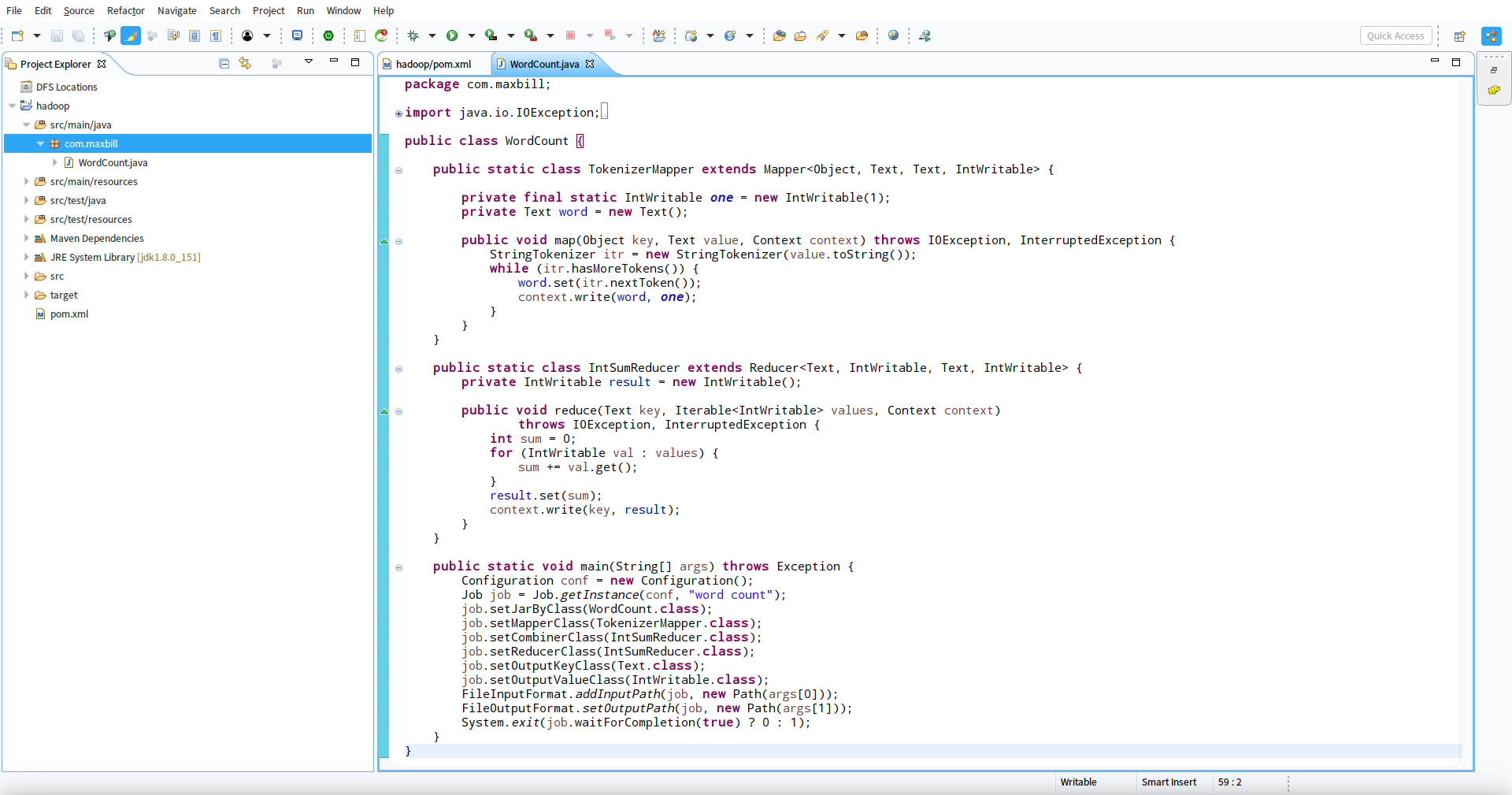
2.创建WordCount类,使用hadoop官方给出的例子代码来调试
本文使用的hadoop的版本是2.8.2,使用《官方hadoop2.8.2的wordcount示例代码》实践
3.使用java操作HDFS
我们对官方的例子做一些改动,官方是将写好的WordCount程序丢到hadoop上去执行,我们采用eclipse远程开发调试的方式
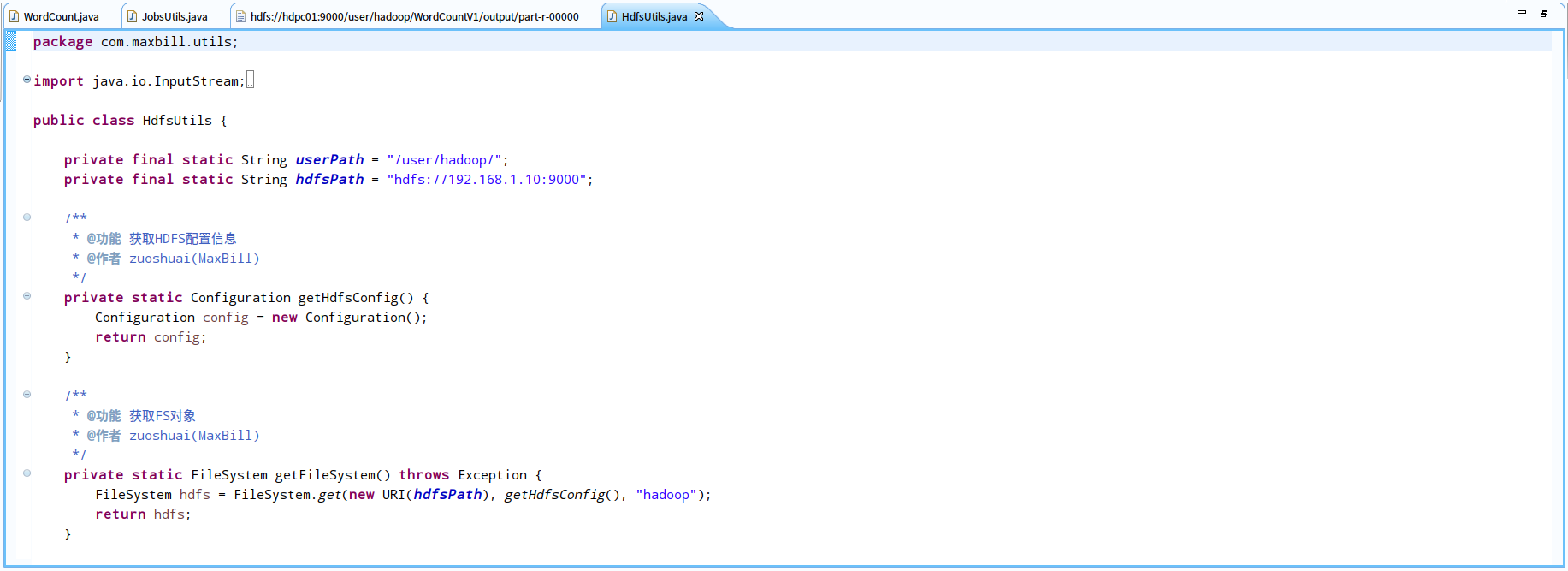
<1>.编写java客户端操作远程hdfs的工作类
<2>.编写自定义map函数
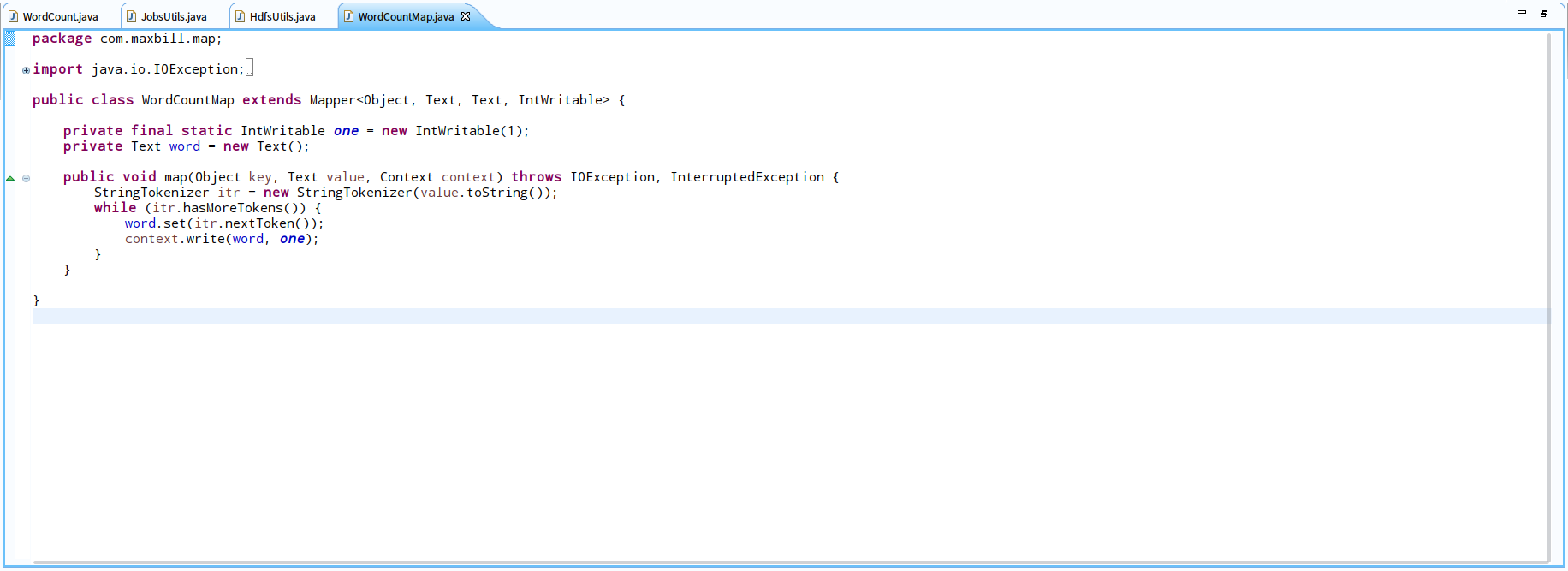
<3>.编写自定义reduce函数
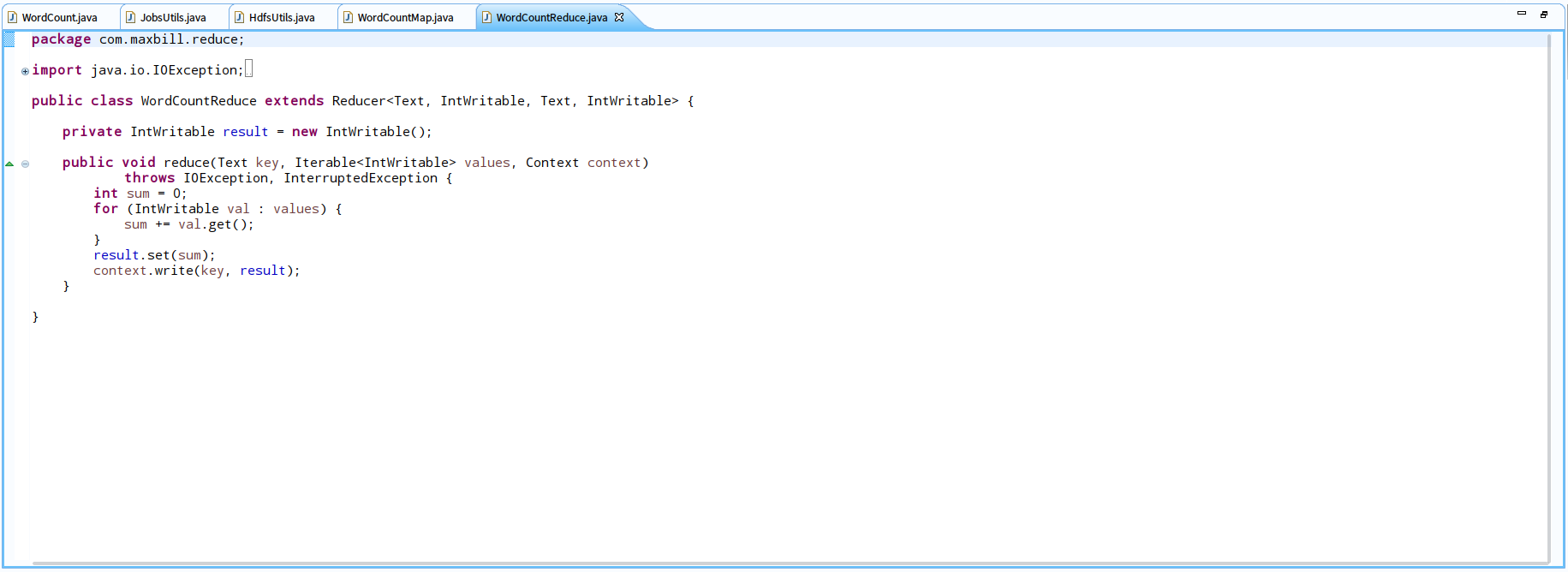
<4>.编写作业工具类
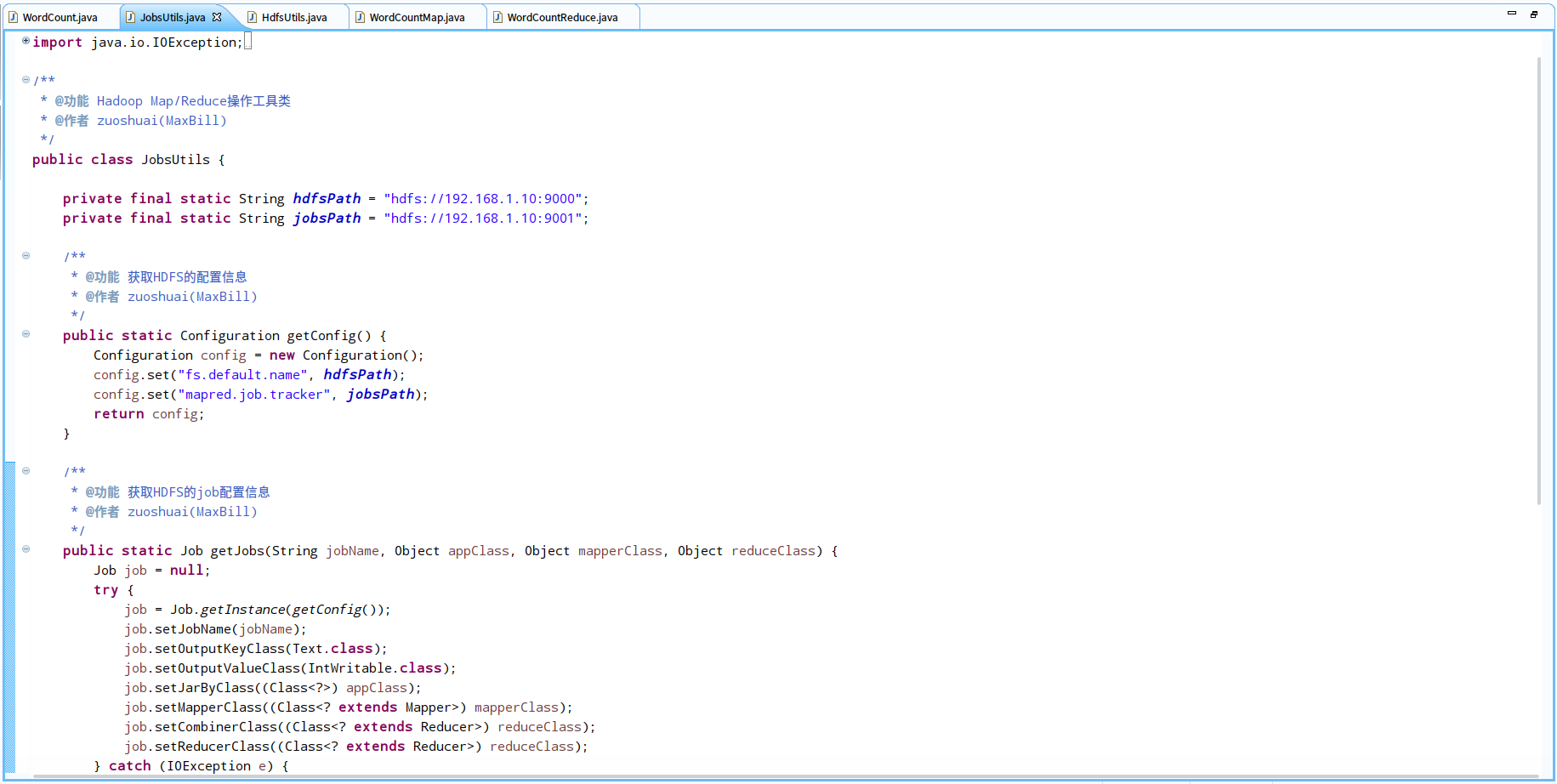
4.我们改动后的测试主类
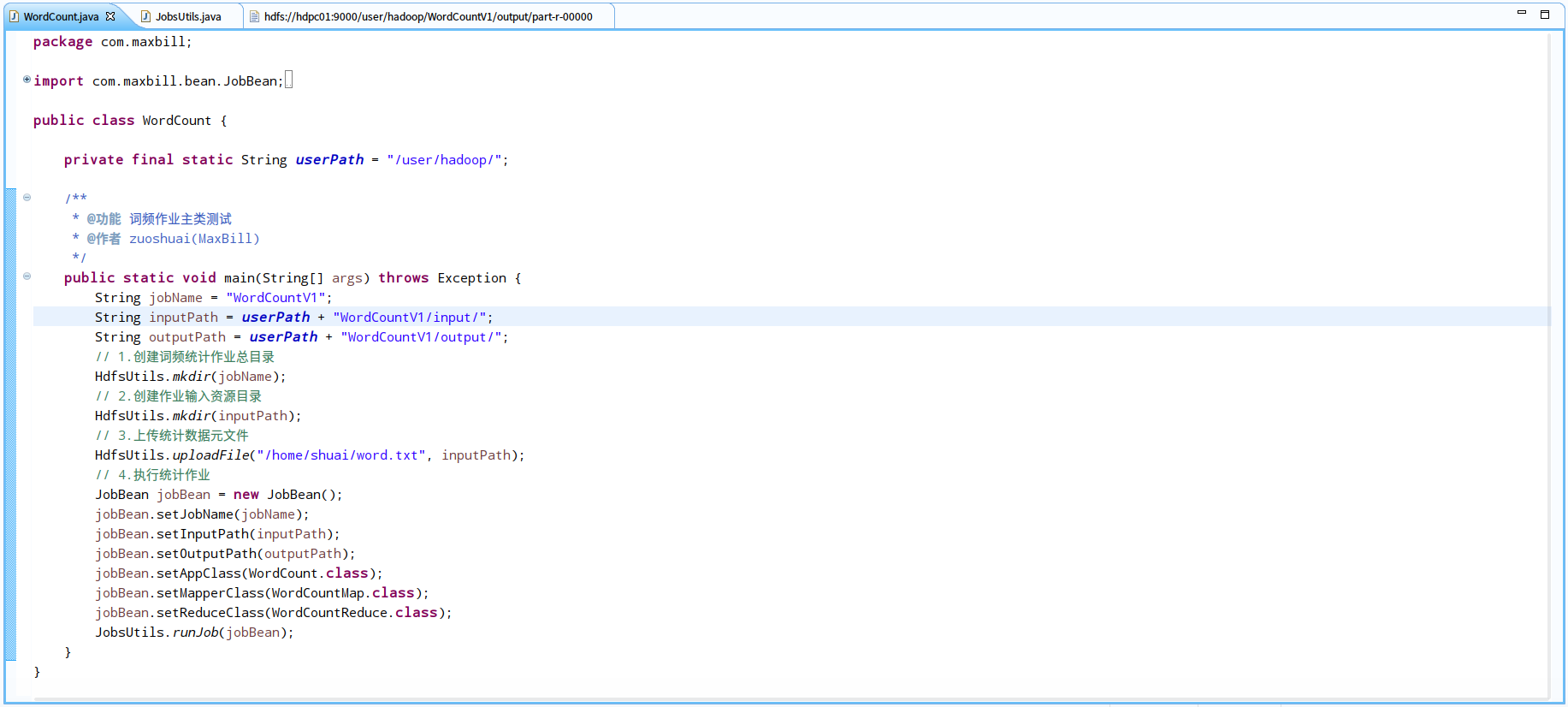
四、运行调试
1.准备资源数据
我们是统计词频程序,准备一个文本的元数据,用于我们的统计词频作业程序,在本地建一个txt文本,里面内容随便输入一些单词和句子即可
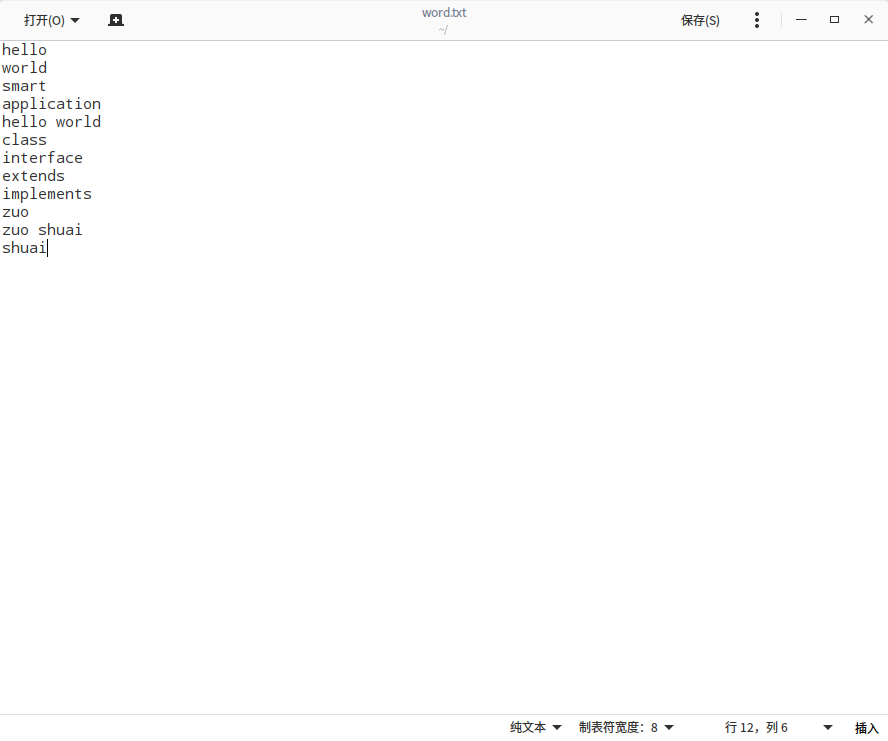
2.启动hadoop集群
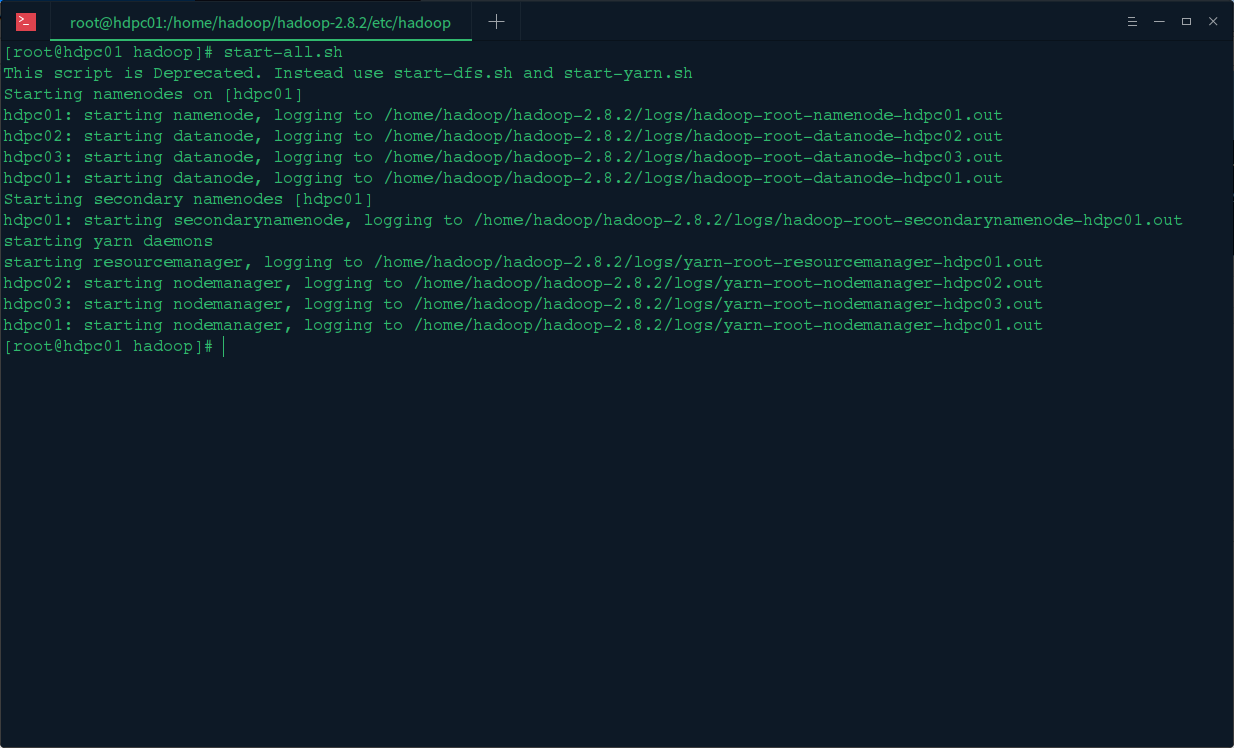
3.运行程序查看状态
从hdfs的web控制面板或者eclipse的hdfs插件可以看到,在数据输出目录已经产生执行完作业的数据结果了 :
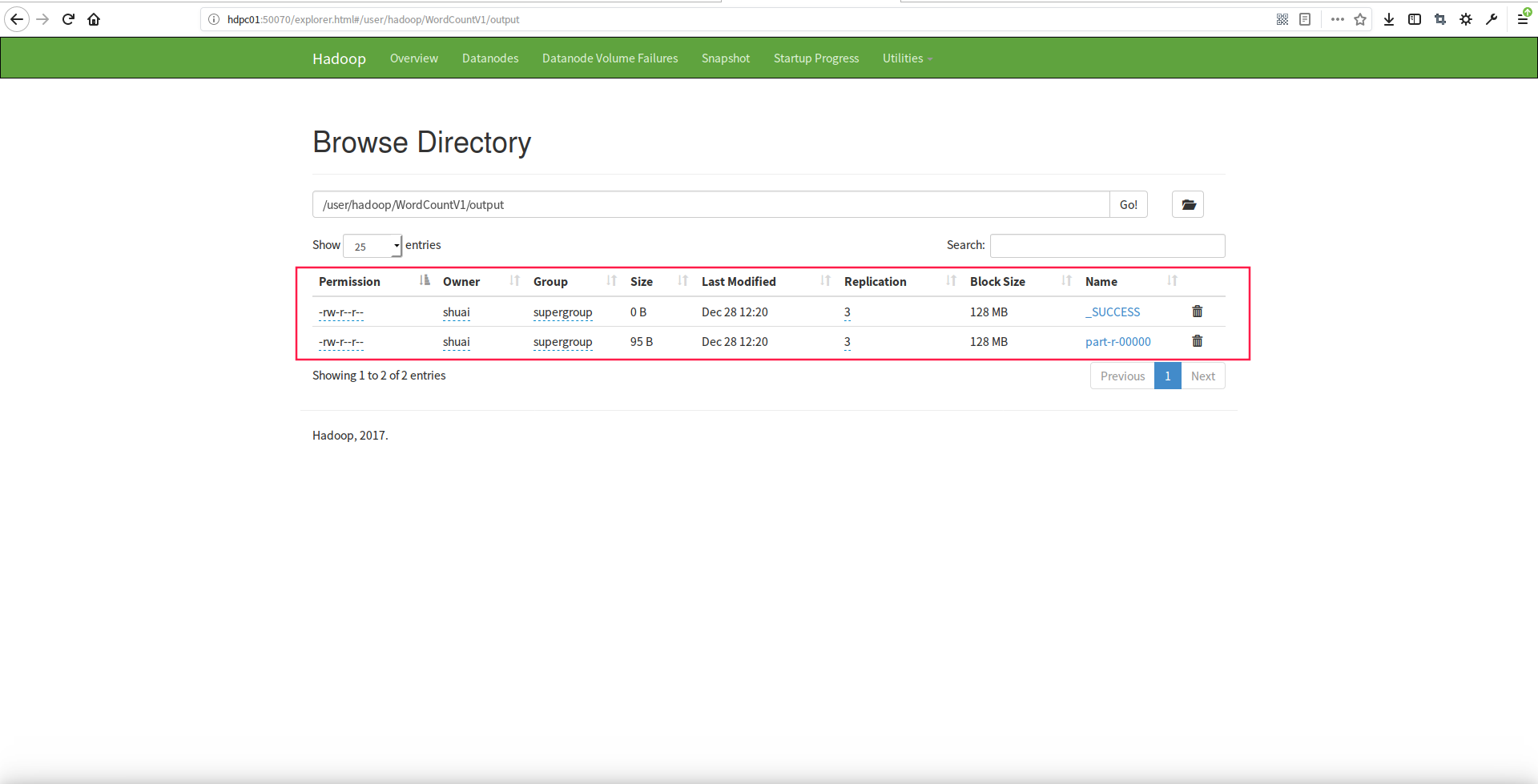
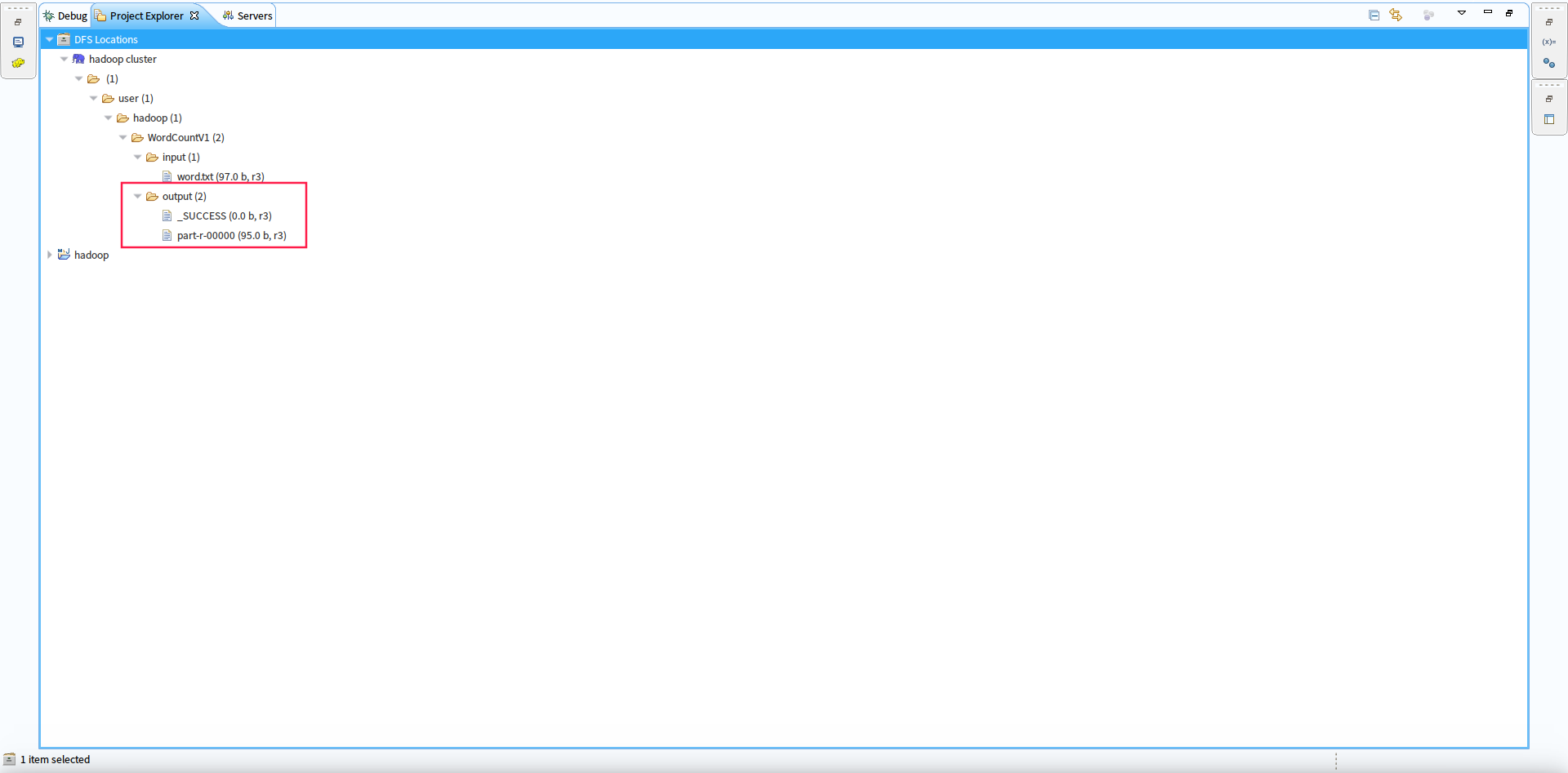
4.查看作业执行数据结果集
在eclipse的插件中双击我们执行作业产生的作业结果:
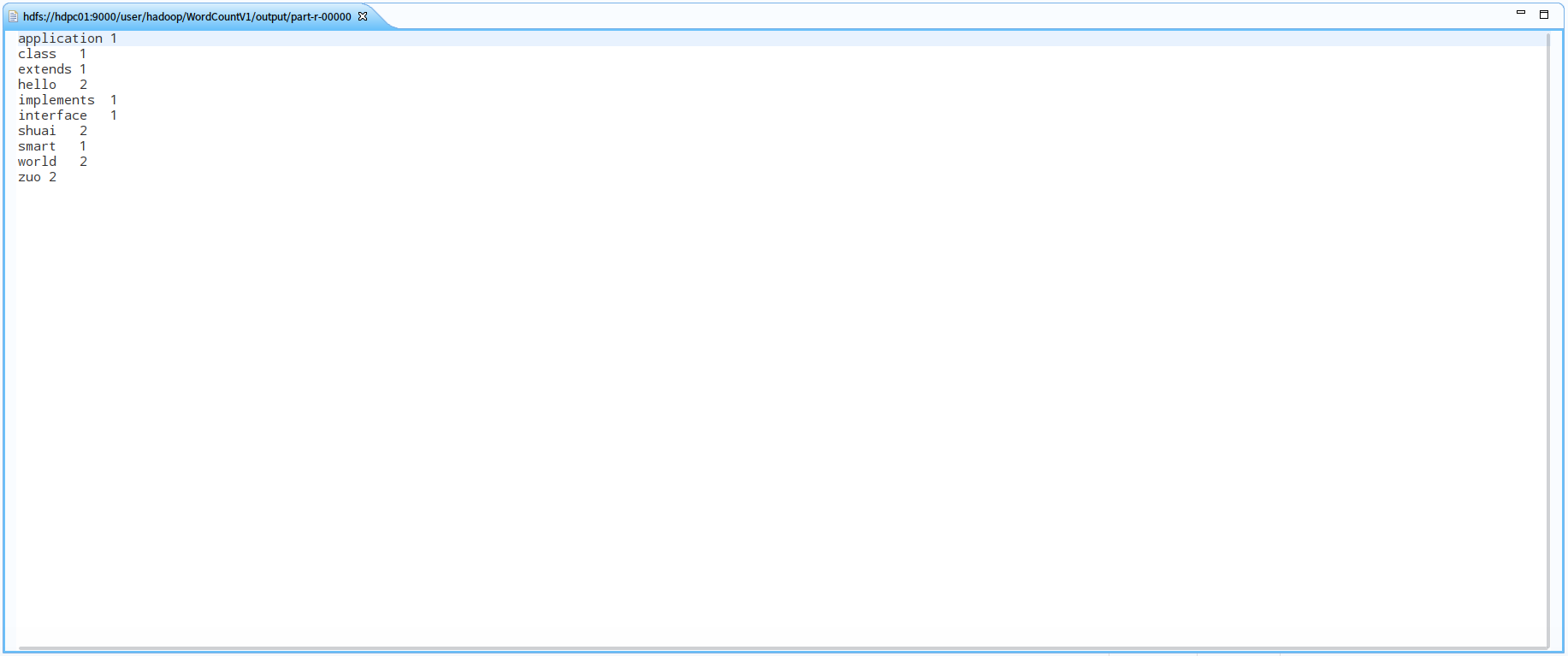
和输入的元数据进行比对,统计结果正确
五、问题反思
1.用户权限问题
Permission denied: user=hadoop, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
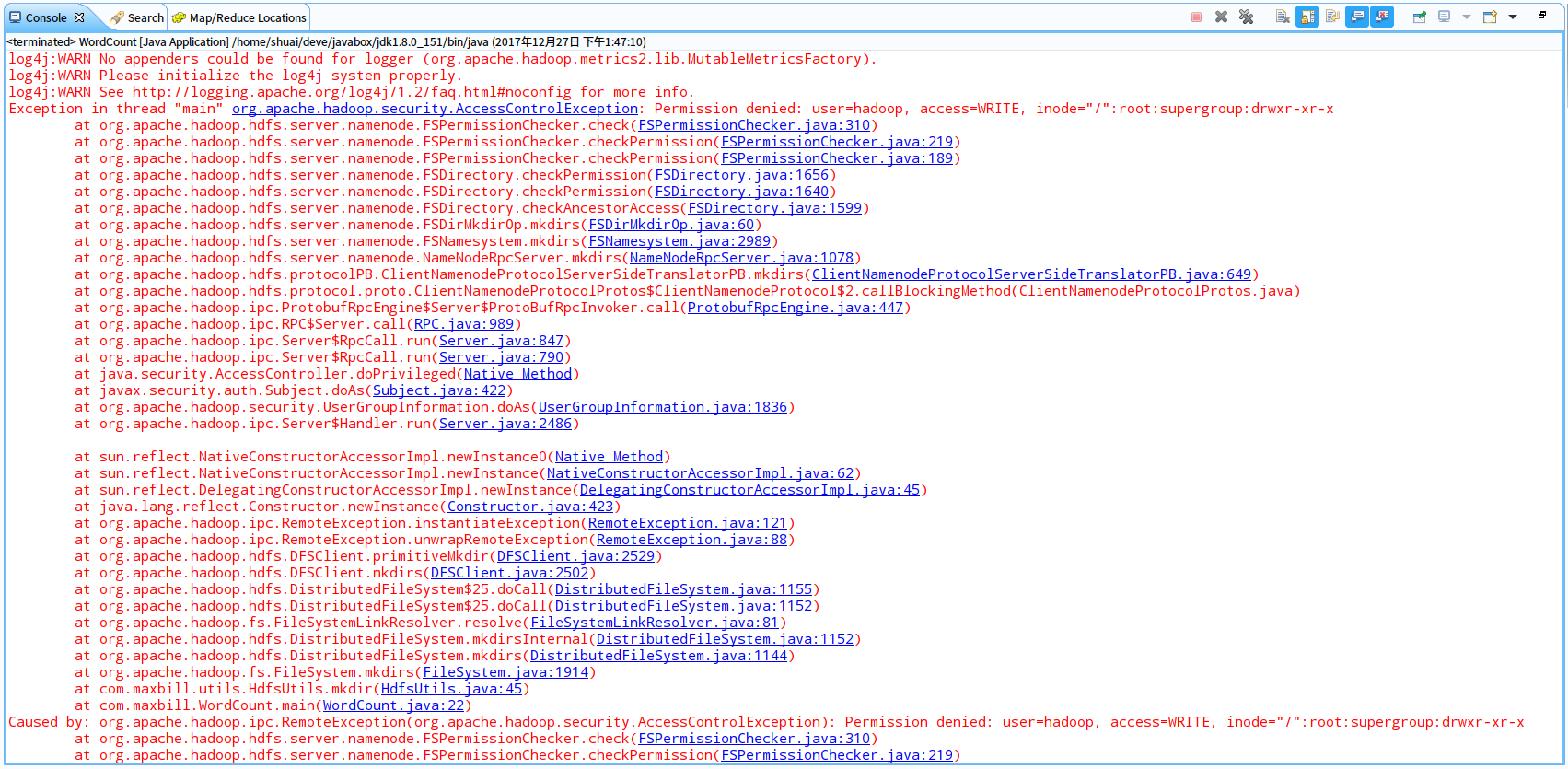
解决方案:执行 hadoop fs -chmod 777 /user/hadoop,其他的操作目录也要赋权限
2.集群格式问题
在使用hdfs namenode -format格式化namenode的时候一定要先删除各个节点下data目录下的旧数据,不然会启动集群后无法连接datanode
六、总结
本文应用对官方WordCount的例子进行改动,实践了使用Eclispe连接远程Hadoop集群操作Hdfs以及开发运行调试了一个简单的MapReduce的项目。在项目中遇到了许多问题在文中也都列了出来,通过查资料也都顺利解决了。文中介绍了两种创建MapReduce项目的方式,实际项目中一般都会采用Maven的方式来构建,虽然完整的实践了MapReduce项目的开发过程,但是MapReduce和Hdfs是什么关 系,MapReduce运行的原理是什么,在后面的文中我们详细的讨论。















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









