






前面两篇简要的介绍了卷积神经网络,并且讨论了卷积层的卷积算法实现及其反向传播中梯度传递及参数梯度更新,本篇讨论池化(pooling)层的推导和实现和以及对填充(Padding)的补充
之前提到过卷积层进行卷积之前会根据需求进行填充,一般填充方式有三种方式:‘VALID’、‘SAME’、‘FULL’:
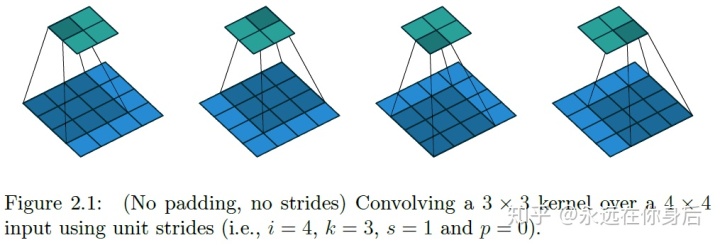
上图是‘VALID’填充,即不填充
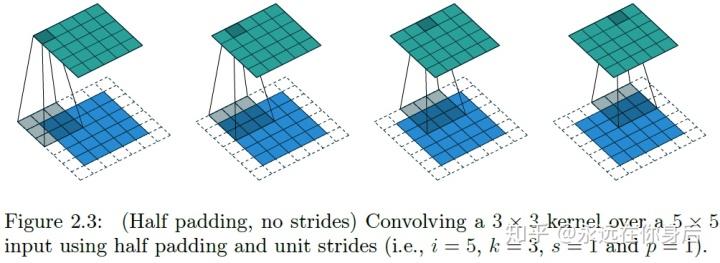
上图是‘SAME Padding’的栗子,截图中称为‘Half Padding’,不过是一回事;以这种方式填充,卷积的输出与输入大小一致,填充的宽度为卷积核大小的一半(所以是Half):
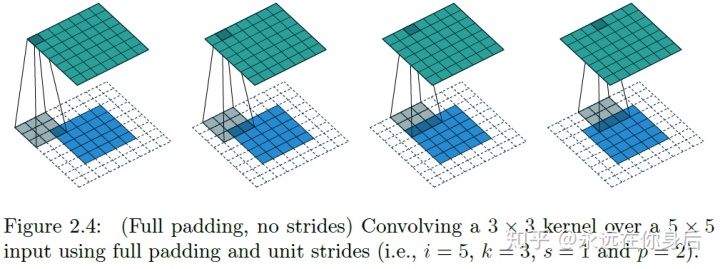
卷积的输出大小通常小于输入,但有时会有相反的需求,这时可以使用‘FULL’方式进行填充,填充宽度为卷积核大小减一:
以上是填充的三种方式,除此之外,还可以使用不同的模式(model)进行填充,常用的有:常量填充(constant),边界填充(edge),镜像填充(reflect)
常量填充是以指定的常量进行填充,例如下图:
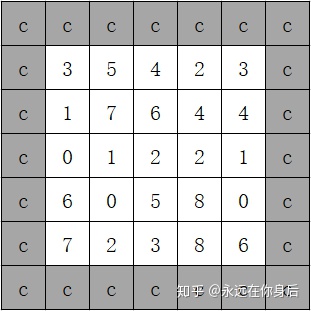
这种模式实现起来简单,numpy中自带该函数:
np.pad(array, pad_width, 'constant', constant_values=value) # constant_values不写默认为0因为对常量求导为0,所以反向计算梯度时没有影响,通常集成在卷积层中的填充就是这种模式
边界填充是指以边界值进行填充,例如4x4的二维数组是输入:
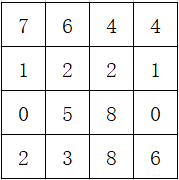
上图是填充前,下图是以边界值进行填充后的结果:
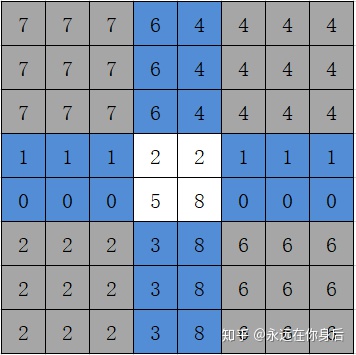
上面是以2的宽度进行边界填充,直接以边界值向外扩展2层就是结果,需要注意的是,在四个角上的处理,上图已经用灰色标出来了
与之前的常量填充不同的是,使用边界值进行填充在反向过程中需要将填充出来的梯度加到原来边界的梯度上,所以一般实现为独立的Layer
class EdgePad(Layer):
def __init__(self, pad_width, **kwargs):
self.top = self.bottom = self.left = self.right = pad_width
def forward(self, x):
# x.shape = N, H, W, C
return np.pad(x, ((0, 0), (self.top, self.bottom), (self.left, self.right), (0, 0)), 'edge')下面讨论简单介绍一下反向过程(backward)的计算步骤,沿用上面的栗子(forward输入大小为4x4),设反向过程传中输入梯度值如下:
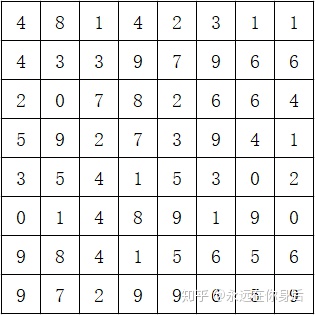
然后将1、2行的值加到第3行,倒数1、2行的值加到倒数第3行:
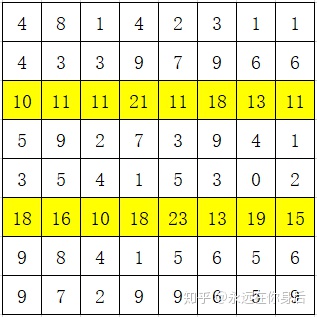
在此基础上,将1、2列的值加到第3列,倒数1、2列的值加到倒数第3列:
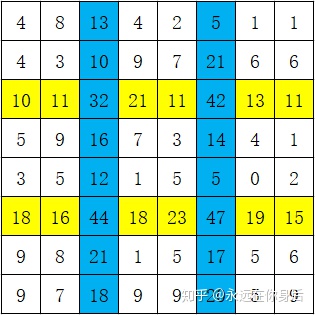
最后,取中间4x4的梯度值就是输出:
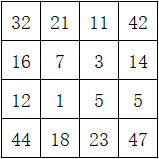
简单的说,填充的值从哪里来的,backward中就将梯度加到哪里,贴一下backward实现代码:
def backward(self, eta):
eta[:, self.top, :, :] += eta[:, :self.top, :, :].sum(axis=1)
eta[:, -self.bottom-1, :, :] += eta[:, -self.bottom:, :, :].sum(axis=1)
eta[:, :, self.left, :] += eta[:, :, :self.left, :].sum(axis=2)
eta[:, :, -self.right-1, :] += eta[:, :, -self.right:, :].sum(axis=2)
return eta[:,self.top:-self.bottom, self.left:-self.right,:] 最后,再介绍一种镜像填充,其前向过程的计算步骤为,以最外一圈为轴对需要填充的位置进行镜像复制,设要填充的输入如下图:
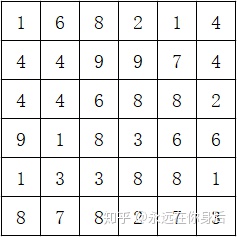
同样,分两步,先对横轴方向进行操作:
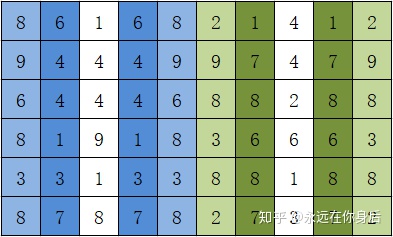
如上图所示,镜像填充以最边缘的列(或行)为轴,对需要填充的部位进行镜像复制,上图中复制与被复制的列都标了相同的颜色以更好理解;然后,在此基础上对纵轴方向进行同样的操作,就得到填充结果:
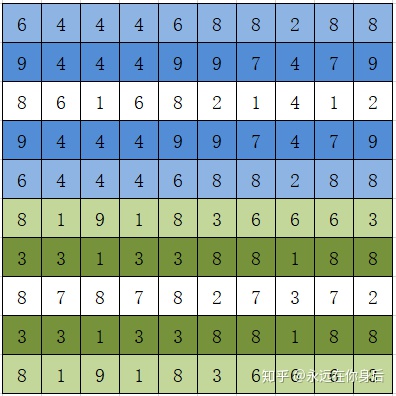
同样也是实现为独立的Layer:
class EdgePad(Layer):
def __init__(self, pad_width, **kwargs):
self.top = self.bottom = self.left = self.right = pad_width
def forward(self, x):
return np.pad(x, ((0, 0), (self.top, self.bottom), (self.left, self.right), (0, 0)), 'edge')至于反向过程的原理也是和前面的EdgePad雷同,填充的值是从哪复制过来的,那么在backward中就将梯度给加到哪里,这里就不举例了,直接贴代码:
def backward(self, eta):
eta[:,self.top+1:2*self.top+1,:,:] += eta[:,self.top-1::-1,:,:]
eta[:,-1-2*self.bottom:-1-self.bottom,:,:] += eta[:,:-self.bottom-1:-1,:,:]
eta[:,:,self.left+1:2*self.left+1,:] += eta[:,:,self.left-1::-1,:]
eta[:,:,-1-2*self.right:-1-self.right,:] += eta[:,:,:-self.right-1:-1,:]
return eta[:,self.top:-self.bottom, self.left:-self.right,:]在第(八)篇开头有个栗子,说明了池化层可以为输入提供少量的平移不变性(translation invariance),除此之外还有旋转不变性(rotation invariance)和缩放不变性(scale invariance),具体的栗子可以看这个回答:CNN网络的pooling层有什么用?
池化层作为一个独立的层,它自然有前向和反向过程,并且含有两个超参数:窗口大小和步长
在前向过程中,按照窗口大小和步长将输入
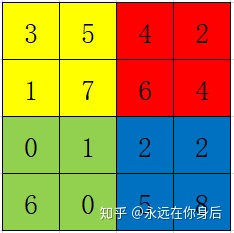

这里,一般有两种方式对每个小块进行计算:取均值、取最大值(最常用);首先是取均值,那么上面的结果就是:
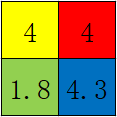
因为实际中步长与窗口大小基本上是一样的,所以统一为一个参数,可以用下面的公式进行表示:
如果是取最大值的话,还要记录最大值的位置,因为之后反向传播计算会用到:
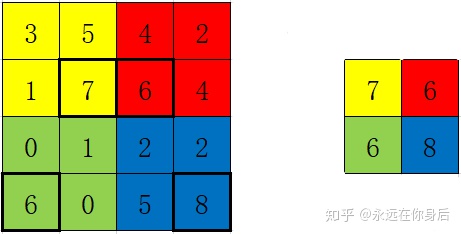
公式为:
以上是池化层前向过程的简要介绍,栗子中的输入输出都是二维数组(2个维度分别是
下面贴一下实现代码,因为通常窗口大小和步长都是一样的,所以统一为一个参数
class MaxPooling(Layer):
def __init__(self, size, **kwargs):
self.size = size # 窗口大小
def forward(self, x):
# x是一个4维数组的输入,并且x.shape = N, H, W, C
out = x.reshape(x.shape[0], x.shape[1]//self.size, self.size, x.shape[2]//self.size, self.size, x.shape[3])
out = out.max(axis=(2, 4))
self.index = out.repeat(self.size, axis=1).repeat(self.size, axis=2) == x # 记录最大值的位置
return out上面MaxPooling的实现,基本MeanPooling只用修改2行代码就行了:
out = out.mean(axis=(2, 4)) # 由out.max改为out.mean
# self.index = out.repeat(self.size, axis=1).repeat(self.size, axis=2) == x # mean pooling不需要这行
return out以上,是池化层的前向过程,不过Maxpooling的实现中记录最大值的位置有一些小小的‘问题’,在下面结合反向过程一起讨论
池化层的反向过程较简单,因为它没有需要学习的参数,所以只需要将上一层传进来的梯度做适当的计算然后输出即可;设前向过程中的输入为

所以对应的反向过程就是根据上一层传进来的梯度
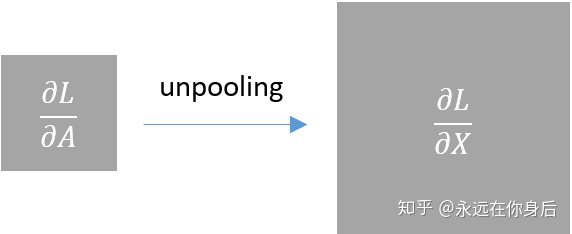
具体到前面的栗子就是:
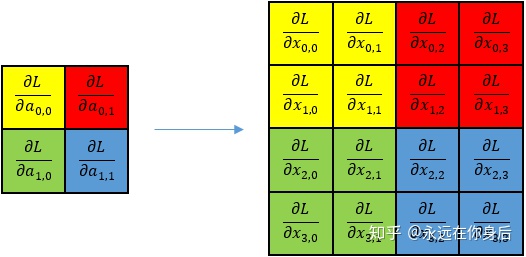
因为具体的实现里将步长和窗口大小统一了,所以计算梯度的时会,各个窗口可以独立计算,例如第一个窗口(黄色的):
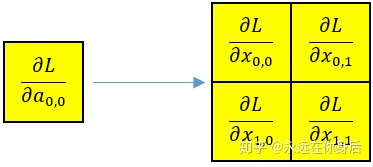
前向过程有Maxpooling和Meanpooling的区别,反向过程同样如此,当使用均值进行池化时,
所以:
具体到上面的栗子就是:
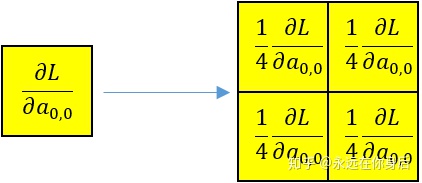
其他窗口的计算也是一样的,就不画图了,下面贴上完整的实现代码:
class MeanPooling(Layer):
def __init__(self, size, **kwargs):
self.size = size
def forward(self, x):
out = x.reshape(x.shape[0], x.shape[1]//self.size, self.size, x.shape[2]//self.size, self.size, x.shape[3])
return out.mean(axis=(2, 4))
def backward(self, eta):
# 先除以self.size**2再进行repeat以减少计算
return (eta / self.size**2).repeat(self.size, axis=1).repeat(self.size, axis=2)与Meanpooling不同的是,Maxpooling在反向过程中只有前向过程中最大值的那个元素会得到梯度,其余都为0,例如Maxpooling前向过程输入如下:
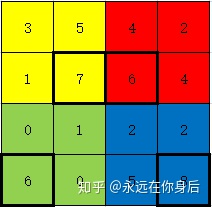
根据前面的实现,在forward中会产生一个index数组用来记录最大值的位置:

所以在backward中先将
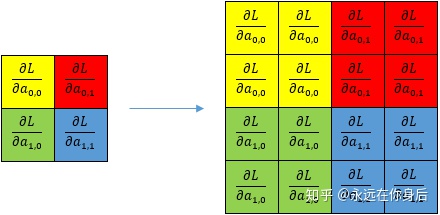
然后将之与index数组相乘,就得到了
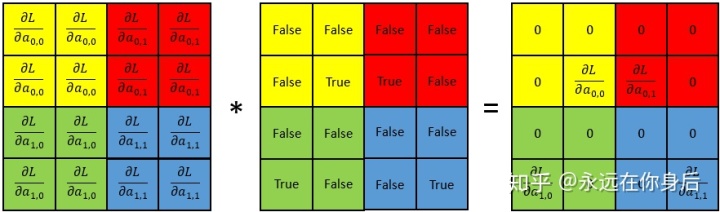
然后贴一下完整的代码:
class MaxPooling(Layer):
def __init__(self, size, **kwargs):
self.size = size
def forward(self, x):
out = x.reshape(x.shape[0], x.shape[1]//self.size, self.size, x.shape[2]//self.size, self.size, x.shape[3])
out = out.max(axis=(2, 4))
self.index = out.repeat(self.size, axis=1).repeat(self.size, axis=2) == x
return out
def backward(self, eta):
return eta.repeat(self.size, axis=1).repeat(self.size, axis=2) * self.index最后的最后,前面讨论Maxpooling的前向过程时提起过一个问题,就在于index数组上,或者说在于去最大值的过程中,看具体的栗子,设Maxpooling前向过程输入如下:
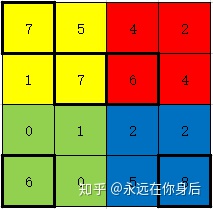
该栗子中某些(一个或多个)窗口最大值并不是唯一的,那么反向过程中该如何取舍,是只将梯度传递给其中一个,还是同时传递,或者其他处理方法?
在上面的实现中我选择将梯度同时传递给并列最大值的元素,因为并不能确定这些并列最大值中哪一个的特征信息是最有价值的,所以为了保(fang)险(bian)起见就将梯度同时传递给它们;所以,这种情况的index数组值如下(前面的代码不用改):

参考文献:
[1] A guide to convolution arithmetic for deep learning
完整实现github.com














 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









