






代价函数有助于我们弄清楚如何把最有可能的函数与我们的数据相拟合。比如在模型训练中我们有训练集(x,y),x表示房屋的面积,y表示房屋的价格,我们要通过线性回归得到一个函数hθ(x)(被称为假设函数),以x作为自变量,y作为因变量,用函数来预测在给定的房屋面积下的价格。
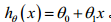
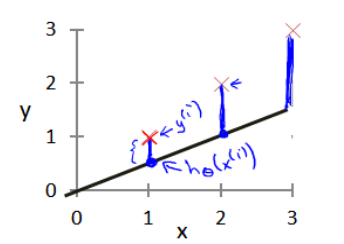
参数θ0和θ1的变化会引起假设函数的变化,参数的选择决定了我们得到的直线相对于训练集的准确度,用得到的模型预测的值与训练集中值的差距称为建模误差(即下图中的蓝色线)
我们的目标是选择出使建模误差的平方和最小的参数,在回归分析中我们取代价函数为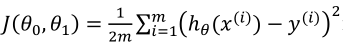 ,即使J(θ0,θ1)的值最小。
,即使J(θ0,θ1)的值最小。
我们绘制一个等高线图,三个坐标分别为θ0 和θ1和J(θ0,θ1 ):
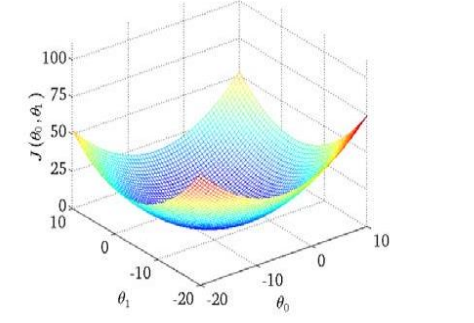
则可以看出在三维空间中存在一个使代价函数J(θ0,θ1)最小的点(即图中的最低点)
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数是解决回归问题最常用的手段了。
机器学习中代价函数有很多,根据不同的问题,选用不同的代价函数,比如逻辑回归使用对数代价函数,分类问题使用交叉熵作为代价函数。常用的损失函数如下:

那么是不是代价函数越小越好呢?答案是 No
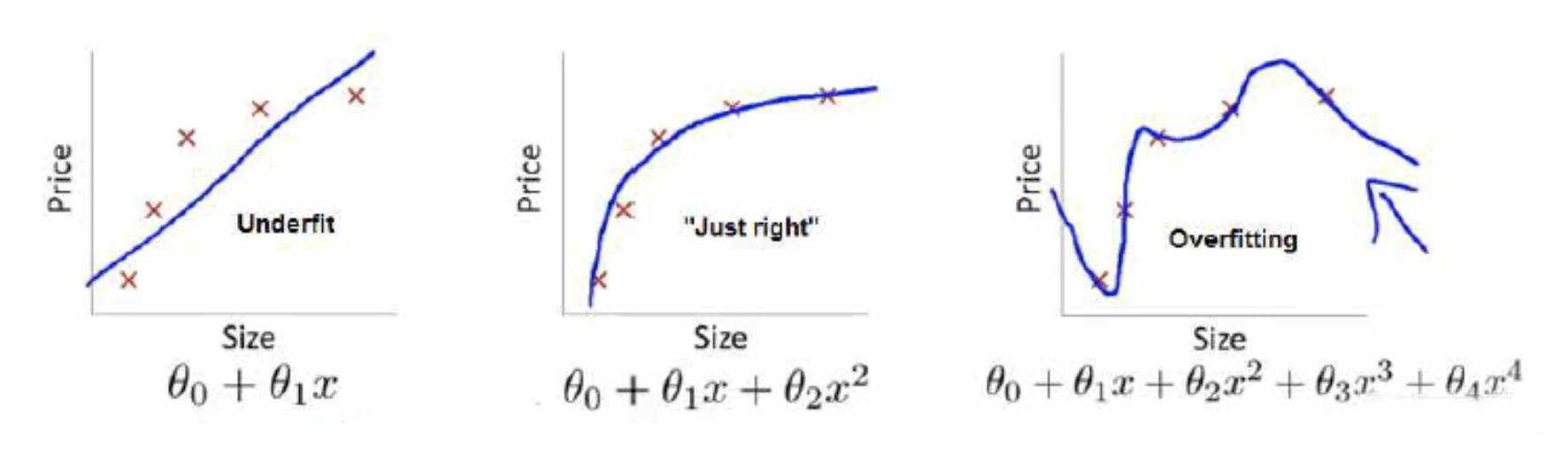
上面三个图的函数依次为f1(x),f2(x),f3(x) 。我们是想用这三个函数分别来拟合真实值Y,从上图中我们可以看出图三的函数f3(x) 拟合效果最好,因为其代价函数值最低。这时我们还要考虑经验风险和结构风险。
那么什么是经验风险和结构风险呢?
f(x)关于训练集(X,Y)的平均损失称作经验风险(empirical risk),即 。“结构风险”度量的是模型的某些性质,例如模型的复杂度或惩罚项等,结构风险引入在机器学习中称为“正则化”,常用的有
,
范数。
最后来看,为什么图三中的函数f3(x)不是最好的,因为图三的函数对训练集数据过度拟合,造成过拟合现象,导致它真正的预测效果 并不是很好。换句话说,虽然它的拟合效果很好,经验风险低,但是其函数复杂度好,结构风险很高,所以它不是最终获取的函数。而图二函数对经验风险和结构风险进行了折中,所以该函数才是理想的函数。
怎么求解代价函数最小值呢?梯度下降法,这里不赘述 ,后面会详细讲解
最后附上简单的matlab线性拟合程序
x=[1:0.3:4];y=x*0.1+0.5+unifrnd(-0.5,0.5,1,11); p=polyfit(x,y,1); x1=linspace(min(x),max(x)); y1=polyval(p,x1); plot(x,y,'*',x1,y1);















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









