






近日,美图云视觉技术部门与中科院自动化所共同合作研发,提出一种基于类脑智能的无监督的视频特征学习和行为识别的方法NOASSOM (Nonlinear Orthogonal Adaptive-Subspace Self-Organizing Map),该方法不依赖于标签信息,可以自适应地、无监督地学到视频的特征表示,相关成果已发表在AAAI2018。
大数据文摘就NOASSOM算法对美图云相关负责人进行了采访,针对NOASSOM效率问题,美图云告诉大数据文摘,NOASSOM由于引入核函数,在模型训练时的计算复杂度比ASSOM(Adaptive-Subspace Self-Organizing Map))略高,但在提取特征时NOASSOM与ASSOM并无速度差异。
美图云强调,NOASSOM的优势是无监督特征提取。
除了论文中提及NOASSOM可以提升识别率之外,NOASSOM是无监督特征提取方法,训练数据不需要标签信息。而ASSOM是有监督学习,训练数据需要标签信息。
此外,美图云表示,该成果计划被应用到美拍短视频相关业务场景中。
以下是论文部分内容:
基于类脑智能的无监督的视频特征学习和行为识别的方法
摘要
视频语义理解一直是学术界的研究热点之一。近两年随着短视频领域的火爆发展,围绕短视频的业务场景应用也在增长,工业界应用场景都对视频内容理解提出了迫切的落地需求。
与学术界用的确定性数据集不同,工业界业务产生的视频数据具有如下特点:首先,数据量大,每天都会有成千上百万的视频被上传;其次,内容未知,现实生活中的场景是很复杂的,尤其对于UGC内容,无法确定用户上传的视频中的主体和场景,行为更是无法预测;再次,时效性,在不同的时间段内视频的主题、场景以及行为是不同的,它可能会随着时间发生变化进行转移。
因此,在这样的数据集上人工建立标签体系非常困难。NOASSOM算法的提出有效解决了算法模型在训练过程中无标签输入的问题。
NOASSOM算法原理
NOASSOM是通过模拟视觉皮层中表面区域的结构来构建的,以数据驱动自组织更新,恢复基本视觉皮层中的神经元对输入刺激的反应。
NOASSOM是对ASSOM方法的改进。ASSOM是一种特征提取方法,它可以从输入数据中学习统计模式,并对学到的模式进行自组织排列,从而进行特征表示。但是ASSOM只能处理有标签的数据,并且只对线性化的数据有效,无法胜任其他复杂情形。
NOASSOM的提出解决了ASSOM对数据的限制问题。首先,NOASSOM通过引入一个非线性正交映射层,处理非线性的输入数据,并使用核函数来避免定义该映射的具体形式。其次,通过修改ASSOM的损失函数,使输入数据的每个样本可以独立地贡献于损失函数,而不需要标签信息。下图示意了NOASSOM与ASSOM的网络结构区别。
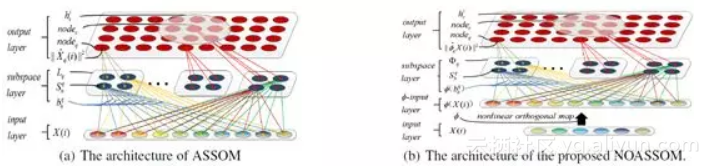
NOASSOM与ASSOM网络结构
NOASSOM算法模型
ASSOM由输入层、子空间层、输出层组成。NOASSOM比ASSOM增加一个非线性正交映射层,用于实现输入层和子空间层的非线性正交映射。为保证映射后的子空间基向量仍然保持正交性,NOASSOM采用正交约束的核函数:
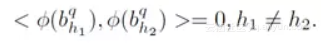
输出层使用输入在子空间的投影表示:
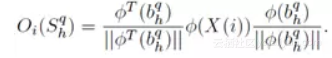
使用投影残差构建损失函数:
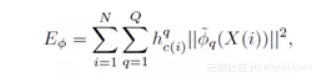
原始的ASSOM的损失函数表示如下:
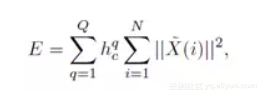
通过修改损失函数使每个样本独立地贡献于损失函数,而不必使用Class-specific 的数据进行有监督训练。NOASSOM使用随机梯度下降法对网络进行训练。
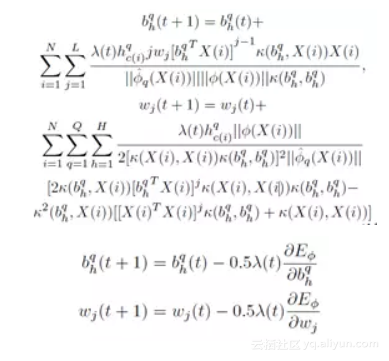
在每次迭代之后,重新对基向量进行正交化处理。算法流程图如下:

本文还提出一个层级的NOASSOM来提取高层的抽象特征,有效地描述视频中行为轨迹的表观和运动信息,构建了一个层级的NOASSOM结构提取视频中的局部行为特征,并使用FISHER VECTOR进行聚合编码,采用SVM进行分类,如下图所示:
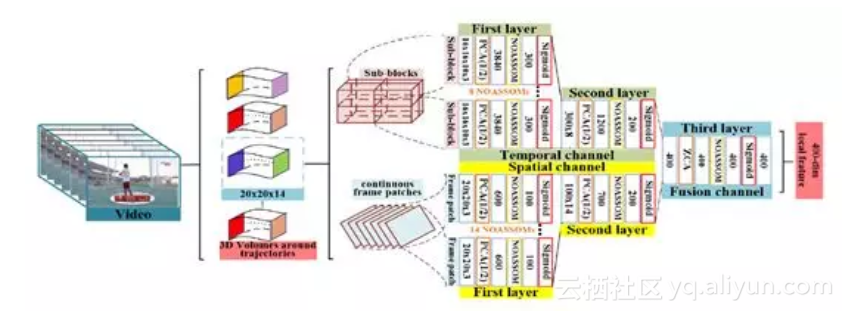
层级NOASSOM 特征提取框架
实验及结果
NOASSOM在国际公开大型数据集UCF101, HMDB51和小型数据集KTH上进行了评测,识别获得了93.8%,69.3%和98.2%的识别率。不同算法识别率如下表所示:
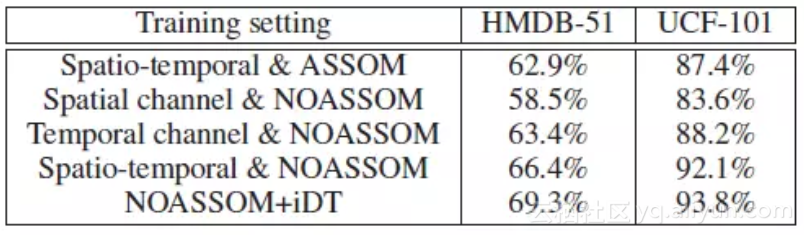
在UCF101数据集上,与手工特征(iDt)+HSV基准方法和iDt+CNN方法相比,NOASSOM的识别率分别高出5.9%和2.3%;在HMDB51数据上,NOASSOM的识别率分别高出8.2%和3.4%。公开数据集上的实验结果表明,这种方法优于之前基于手工特征的方法和大多基于深度特征的方法。
NOASSOM算法评估
NOASSOM中训练得到的基向量的可视化结果如下图所示,左边是表观信息滤波器,右边是运动信息滤波器。表观信息滤波器通过学习可以检测到图像一些边缘信息,进而利用其对图像的水平边沿和垂直边沿进行检测,从而提取良好的轮廓纹理信息。右边的运动信息滤波器学到了一些类似Gabor滤波器学到的信息,这样的滤波器对运动信息更加敏感,实现对运动信息地鲁棒性提取。

NOASSOM中基向量的可视化结果
结论
NOASSOM方法的独特优势在于,可以从大量没有标签的数据进行更加快速的训练,并且获得和其他基于有标签数据方法性能相当甚至更加优越的性能。
基于这项技术的输出将被应用于美拍短视频多个业务场景中,如相似视频的推荐和大规模视频检索,基于短视频内容的用户聚类和画像,以及基于短视频内容的运营标签挖掘等等。
原文发布时间为:2018-03-21
本文作者:文摘菌














 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









