







问题
互联网发展到现在,信息不是缺乏,而是信息泛滥。互联网用户如今经常碰到的问题是:
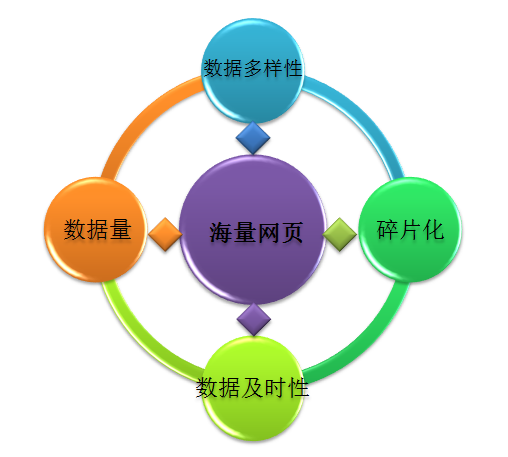
- 面对海量数据,不知道于何时,到何处取得自己想要的信息
× 数据的多样性。比如音频,视频。
× 数据的量太大了
× 数据时效性。比如折扣,金融信息
× 数据太分散, 碎片化。 原始数据需要后续处理
- 不知道如何如何将网页数据结构化,以利于后续分析和处理。
网页HTML数据不是结构化数据!!!
痛点
为了有效率的收集网页数据,爬虫技术应运而生。但是当前爬虫技术也是有弱点的
- 爬虫技术看起来高大上,不是普通人能掌握的
- 爬虫工程师的工资不错, 反过来,请一个爬虫工程师是 比较贵的哟
下面的信息来自于51job,2015年11月
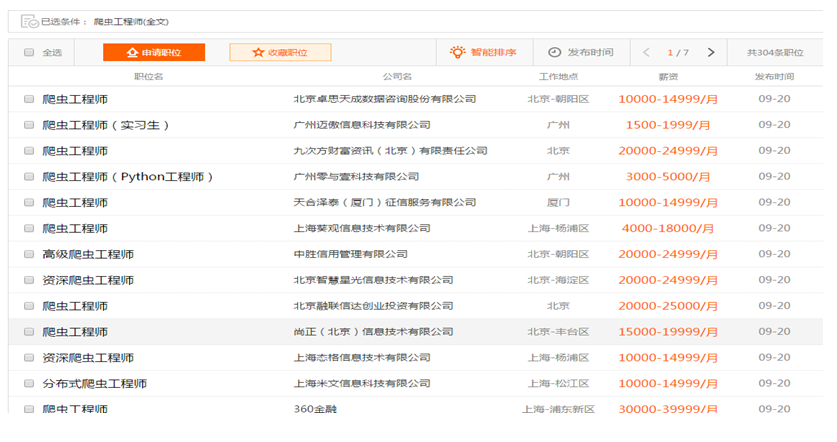
- 爬虫后续维护工作量巨大: 众所周知,网页是经常变化的
产品介绍
DIYPA是一款小而美的工具,大大降低爬虫工作的难度和强度,减轻维护工作量。实现人人可做爬虫工程师的理想
方案图
DIYPA创造性的将爬虫工作分为两阶段:标记和爬取。
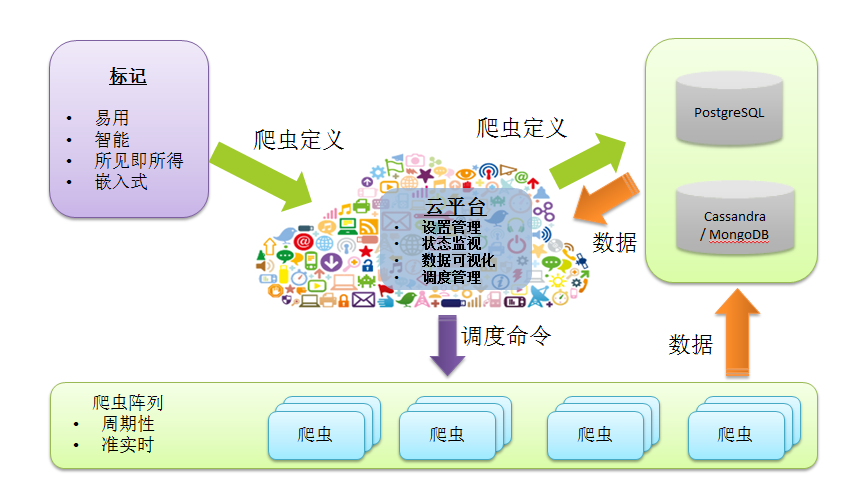
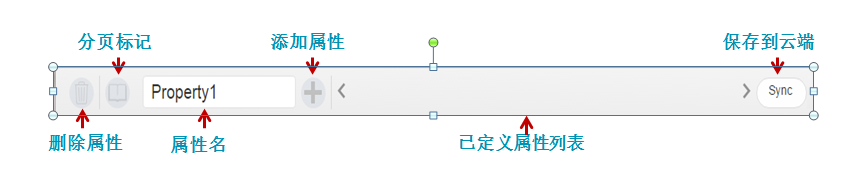
标记阶段/工具
标记工具用Javascript开发而成。以浏览器插件和bookmarklet形式部署到用户的浏览器
- 采用内嵌式,几乎可以嵌入任何网页
- 以所见即所得的方式,让用户定义需要爬取网页信息的位置(PlaceHolder)
- 点击热点(Hotspot),智能猜测用户的意图
- 允许用户定义爬虫属性:比如爬取时间,频率,通知方式等等
爬取阶段/云爬虫阵列
使用Django+ python + AngularJS + Scrapy+ Selenim + DRF开发而成。用户可以
- 创建,编辑,删除爬虫定义
- 查看/处理爬取到的数据
- 数据可视化
- 查看/管理爬取精度
产品家族
标准版
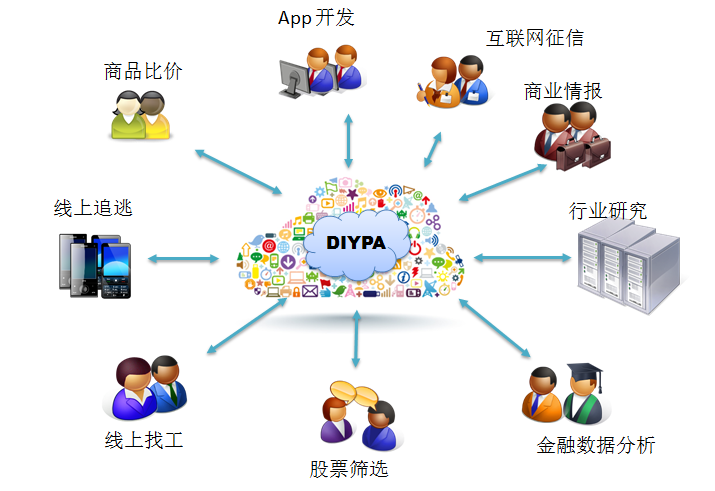
适用于普通用户。可以应用于
- 商品比价
- 网上求租/出租房子
- 网上上招工
专业版
适用于有相应能力的用户。比如分析师,工程师,数据科学家等。可用来做
- 收集金融数据
- 商业行业分析
- Vale at Risk (VaR) 计算
- 各种各样的桌面和移动App的二次开发

企业版
面向企业。主要处理AJAX。可应用于
- 互联网征信
- 舆情分析
- 网上追逃
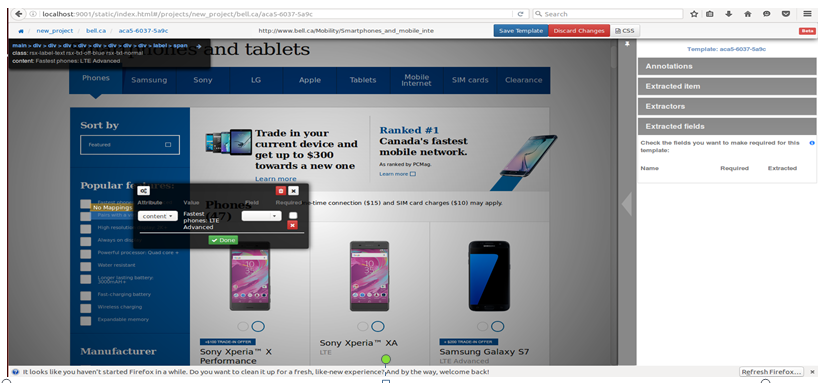
特点场景
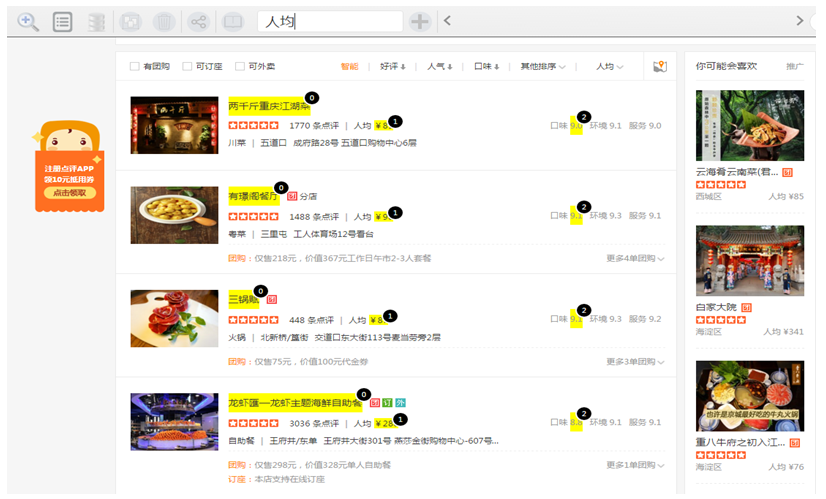
下图中黑色的圆圈 - 热点(Hotspot) 点击可动态切换标记元素
下图中黄色 - 点亮(Highlight) 表示用户当前标记的元素集
标记Redflagdeal (加拿大最大的折扣网站)
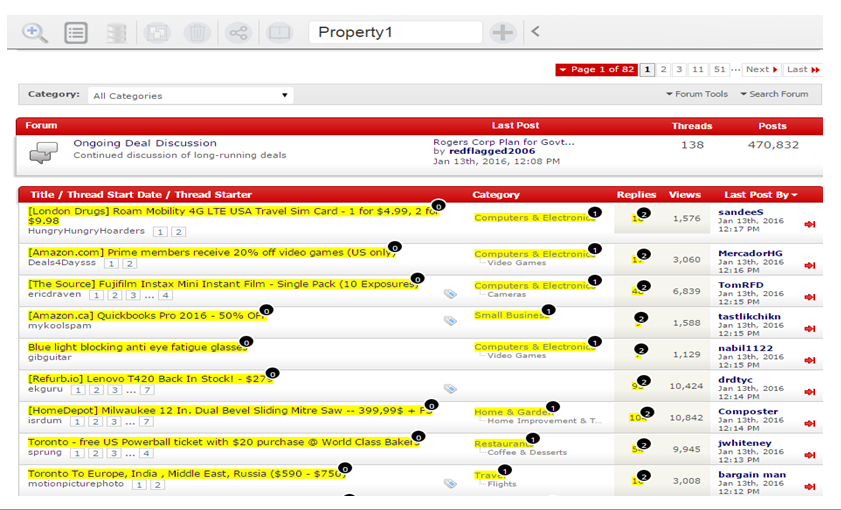
标记大众点评
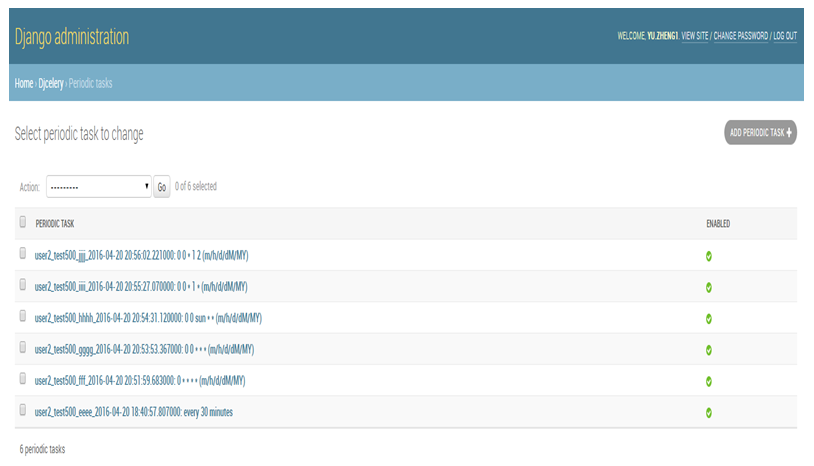
管理定时任务
应用案例
北京一家众筹公司已经用DIYPA开发了一款热门投资指数的产品。
特点

笔者微信二维码

注: 原创,转载请注明出处















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









