






工作流程:
在数据科学竞赛的解决问题的七个步骤:
1.问题或问题的定义。(理解题目)
2.获得培训和测试数据。(获取数据)
3.争论,准备清理数据。(初步清洗数据)
4.分析、识别模式,并探索数据。(特征工程)
5.模型,预测和解决问题。(机器学习算法介入)
6.可视化报告,并提出解决问题的步骤和最终的解决方案。(调参、优化)
7.供应或提交结果。
涉及相关算法:
线性回归、逻辑回归、随机森林、模型融合。
问题回顾:
1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。翻译成32%的存活率。
海难导致生命损失的原因之一是没有足够的救生艇给乘客和机组人员。
虽然幸存下来的运气有一些因素,但一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。
数据分析
数据共891行,12列数据,有用特征11列,还有1个标签列,其中PassengerId只是数据标号,"Survivrd"特征是标签
Survived:是否生存 1表示存活,0表示未生存
1.PassengerId:乘客编号,无用数据
2.Pclass:乘客等级 1/2/3等舱
3.Name:乘客姓名
4.Sex:性别 male:男性,female:女性
5.Age:年龄
6.SibSp:堂兄/妹个数
7.Parch:父母与小孩个数
8.Ticket:船票信息
9.Fare:票价
10.Cabin:客舱
11.Embarked:登船港口
相关算法及参数说明:
random_state
作为每次产生随机数的种子
作为随机种子对于调参过程是很重要的,如果每次都用不同的随机种子。即使参数值没变,每次出来的结果也会不同,不利于比较不同模型的结果
任一个随机样本都有可能导致过度你和,可以用不同的随机样本建模来减少过拟合到的可能
n_estimators
定义了需要用到的决策树的数量
min_samples_split
定义了书中一个节点所需要用来分裂的最少样本数,可以避免过拟合,如果用于分类的样本数太小,模型可能只试用于用来训练样本的分类,而用较多的样本数则可以避免这个问题
如果设定的值过大,就可能出现欠拟合现象,所以可以用cv值(离散数量)考量调节效果
min_samples_leaf
定义了树中终点节点所需要用来分裂的最少样本数,同样可以防止过度拟合
不均等分类问题中,一般这个参数需要设定为较小的值。因为大部分少数类别含有的样本都比较小
min_weight_fraction_leaf
和上面的min_simples_leaf 很像,不同的是这个参数需要被设定为较小的值,因为大部分少数类别含有的样本都比较小
max_depth
定义和树的最大深度,也可以控制过拟合,树越深,越容易过拟合,也可以用CV值检验
max_leaf_nodes
定义了决策树里最多能有多少个终点节点,这个属性可能在上面的max_depth里就被定义了,深度为n的二叉树就有最多2的n次方的终点节点
如果定义max_leaf_nodes GBM就会忽略前面的 max_depth
max_features
决定了用于分类的特征树,是认为随机定义的
开始进入正题:python版本3.7
#导入数据
import pandas as pd
titanic = pd.read_csv('titanic_train.csv')
titanic.head()
print (titanic.describe())
#数据预处理, 填充缺失值以及将特征中含有字符的转换为数值型
#将年龄这一列的数据缺失值按均值进行填充
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
print(titanic.describe())
#查看Sex种类
print(titanic["Sex"].unique())
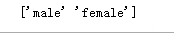
#将性别中的男女设置为0 1 值 把机器学习不能处理的自字符值转换成能处理的数值
#loc定位到哪一行,将titanic['Sex'] == 'male'的样本Sex值改为0
titanic.loc[titanic['Sex'] =='male','Sex'] = 0
titanic.loc[titanic['Sex'] =='female','Sex'] = 1
#查看港口种类,发现有缺失值
print(titanic['Embarked'].unique())
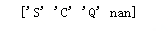
#将登船地点同样转换成数值,缺失值用‘S’填充
titanic['Embarked']=titanic['Embarked'].fillna('S')
titanic.loc[titanic['Embarked'] == 'S','Embarked'] = 0
titanic.loc[titanic['Embarked'] == 'C','Embarked'] = 1
titanic.loc[titanic['Embarked'] == 'Q','Embarked'] = 2
#线性模型
#导入线性回归包
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
alg = LinearRegression()
#将m个样本分成三份 n_folds 代表的是交叉验证划分几层(几份)
kf = KFold(titanic.shape[0], n_folds=3, random_state=1)
predictions = []
for train, test in kf:
#将训练数据拿出来,对原始数据取到建立好的特征 然后取出用于训练的那一部分
train_predictors = (titanic[predictors].iloc[train,:])
train_target = titanic["Survived"].iloc[train]
#进行训练
alg.fit(train_predictors, train_target)
#用test集对模型进行验证
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)
import numpy as np
predictions = np.concatenate(predictions, axis=0)
predictions[predictions > .5] = 1
predictions[predictions <=.5] = 0
titanic["Survived"] = titanic["Survived"].astype(float)
print("测试数据总数量",len(predictions))
print("正确的数量:",sum(predictions == titanic["Survived"]))
accuracy = sum(predictions == titanic["Survived"]) / len(predictions)
#准确率
print( accuracy)

#逻辑回归模型
#导入逻辑回归包
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
alg = LogisticRegression(random_state=1)
#使用逻辑回归做交叉验证3次
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic['Survived'],cv=3)
print(scores.mean())
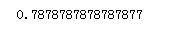
可以看出这里单纯的逻辑回归的准确率提升不是很明显
测试表做同样的数据处理
titanic_test = pd.read_csv("test.csv")
titanic_test["Age"] = titanic_test["Age"].fillna(titanic["Age"].median())
titanic_test["Fare"] = titanic_test["Fare"].fillna(titanic_test["Fare"].median())
titanic_test.loc[titanic_test["Sex"] == "male", "Sex"] = 0
titanic_test.loc[titanic_test["Sex"] == "female", "Sex"] = 1
titanic_test["Embarked"] = titanic_test["Embarked"].fillna("S")
titanic_test.loc[titanic_test["Embarked"] == "S", "Embarked"] = 0
titanic_test.loc[titanic_test["Embarked"] == "C", "Embarked"] = 1
titanic_test.loc[titanic_test["Embarked"] == "Q", "Embarked"] = 2
#随机森林模型
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
#特征列表
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
print(scores.mean())
#因为10颗树太少,分数提高的不明显

#对树进行构造多一点
alg = RandomForestClassifier(random_state=1, n_estimators=25, min_samples_split=4, min_samples_leaf=2)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
kf = cross_validation.KFold(titanic.shape[0], 3, random_state=1)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
#交叉验证3次平均分
print(scores.mean())
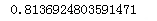
#可以看出分数提升了不少
#构造特征,玄学分析名字长度和家庭成员数对获救的影响
titanic["FamilySize"] = titanic["SibSp"] + titanic["Parch"]
titanic["NameLength"] = titanic["Name"].apply(lambda x: len(x))
import re
#正则表达式提取姓名
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
#新构建特征
titles = titanic["Name"].apply(get_title)
print(pd.value_counts(titles))
#将str特征转换为数值类型
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2}
for k,v in title_mapping.items():
titles[titles == k] = v
#打印称呼特征总计数
print(pd.value_counts(titles))
#添加新的特征
titanic["Title"] = titles
#对特征进行画图,直方图显示特征权重对最终结果的影响
import numpy as np
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
#特征列表
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize", "Title", "NameLength"]
selector = SelectKBest(f_classif, k=5)
selector.fit(titanic[predictors], titanic["Survived"])
# Get the raw p-values for each feature, and transform from p-values into scores
scores = -np.log10(selector.pvalues_)
# Plot the scores. See how "Pclass", "Sex", "Title", and "Fare" are the best?
plt.bar(range(len(predictors)), scores)
plt.xticks(range(len(predictors)), predictors, rotation='vertical')
plt.show()
#只保留权重大的特征,并依然只做三次交叉验证。比较结果发现确实和上面多特征结果大致无变化。
predictors = ["Pclass", "Sex", "Fare", "Title"]
alg = RandomForestClassifier(random_state=1, n_estimators=25, min_samples_split=4, min_samples_leaf=2)
kf = cross_validation.KFold(titanic.shape[0], n_folds=3, random_state=1)
scores = cross_validation.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=kf)
print(scores.mean())


#堆叠算法(模型融合)
#将两个算法结合着使用,Boosting和逻辑回归结合使用
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
#GradientBoostingClassifier看成一个森林
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title",]],
[LogisticRegression(random_state=1), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
kf = KFold(titanic.shape[0], n_folds=3, random_state=1)
predictions = []
for train, test in kf:
train_target = titanic["Survived"].iloc[train]
full_test_predictions = []
#对每一个算法进行验证
for alg, predictors in algorithms:
#训练模型
alg.fit(titanic[predictors].iloc[train,:], train_target)
#模型预测,并转换为float避免预测值失真
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1]
full_test_predictions.append(test_predictions)
#对两种算法的结果相加求均值作为最终结果
test_predictions = (full_test_predictions[0] + full_test_predictions[1]) / 2
#小于等于0.5则未获救 大于0.5则获救
test_predictions[test_predictions <= .5] = 0
test_predictions[test_predictions > .5] = 1
predictions.append(test_predictions)
#将结果转为一维数组
predictions = np.concatenate(predictions, axis=0)
#森林参数没有调优的情况下求出准确率 大约提升了0.08个点
accuracy = sum(predictions == titanic["Survived"]) / len(predictions)
print(accuracy)
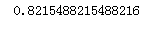
#测试表做同样的特征工程处理
titles = titanic_test["Name"].apply(get_title)
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2, "Dona": 10}
for k,v in title_mapping.items():
titles[titles == k] = v
titanic_test["Title"] = titles
print(pd.value_counts(titanic_test["Title"]))
titanic_test["FamilySize"] = titanic_test["SibSp"] + titanic_test["Parch"]
#终极预测方案
predictors = ["Pclass", "Sex", "Age", "Fare", "Embarked", "FamilySize", "Title"]
algorithms = [
[GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=3), predictors],
[LogisticRegression(random_state=1), ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]]
]
#用堆叠算法对测试表进行预测
full_predictions = []
for alg, predictors in algorithms:
alg.fit(titanic[predictors], titanic["Survived"])
predictions = alg.predict_proba(titanic_test[predictors].astype(float))[:,1]
full_predictions.append(predictions)
#随机森林3倍权重+逻辑回归结果均值作为最终预测值
predictions = (full_predictions[0] * 3 + full_predictions[1]) / 4
predictions















 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









