






1.KNN算法介绍
KNN算法的思想:在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
2.例子:KNN实现鸢尾数据集分类
鸢尾数据集一共有150个数据样本,并且均匀分布在3个不同的亚种;每个数据样本被4个不同的花瓣、花萼的形状特征所描述。
数据集包含了三类分别为:setosa, versicolor, virginica
数据集测量了所有150个样本的4个特征,分别是:
- sepal length(花萼长度)
- sepal width(花萼宽度)
- petal length(花瓣长度)
- petal width(花瓣宽度)
以上四个特征的单位都是厘米(cm)
样本特征:
[5. 2.3 3.3 1. ]
[4.9 3.1 1.5 0.1]
[6.3 2.3 4.4 1.3]
[5.8 2.6 4. 1.2]
[6.2 2.9 4.3 1.3]
[4.7 3.2 1.3 0.2]
[4.6 3.4 1.4 0.3]
。。。。
标签:0,1,2
代码:
#coding=utf-8 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import classification_report #1.数据获取 iris = load_iris() print iris.data.shape #2.数据预处理:训练集测试集分割,数据标准化 X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.25,random_state=33) # 对训练和测试的特征数据进行标准化 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) # 3.使用K临近分类器对测试数据进行类别预测 knc = KNeighborsClassifier() knc.fit(X_train,y_train) y_predict = knc.predict(X_test) #4.获取结果报告 print 'The Accuracy of K-Nearest Neighbor Classifier is', knc.score(X_test,y_test) print classification_report(y_test,y_predict,target_names=iris.target_names)
结果:
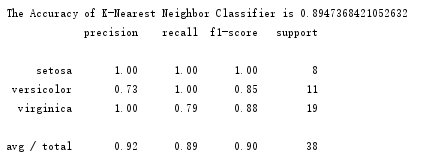
特点:K近邻模型没有参数训练过程,而是根据测试样本在训练数据的分布直接作出分类决策。
缺点是非常高的计算复杂度和内存消耗:需要遍历每个训练样本、逐一计算相似度并排序。














 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









