






一、概述
随着公司集群升级到2.x,hadoop周边的一些工具也进行了版本的更新。这次主要说说sqoop2的升级和部署,其中sqoop1和sqoop2基本框架和用法发生翻天覆地的改变,其对版本的向下兼容做的十分不好,接下来慢慢说,总之各种值得吐槽的地方。
二、sqoop2的基本框架,以及部署
(1)首先说说sqoop1和sqoop2区别
这两个版本是完全不兼容的,其具体的版本号区别为1.4.x为sqoop1,1.99x为sqoop2。sqoop1和sqoop2在架构和用法上已经完全不同。
在架构上,sqoop2引入了sqoop server(具体服务器为tomcat),对connector实现了集中的管理。其访问方式也变得多样化了,其可以通过REST API、JAVA API、WEB UI以及CLI控制台方式进行访问。另外,其在安全性能方面也有一定的改善,在sqoop1中我们经常用脚本的方式将HDFS中的数据导入到mysql中,或者反过来将mysql数据导入到HDFS中,其中在脚本里边都要显示指定mysql数据库的用户名和密码的,安全性做的不是太完善。在sqoop2中,如果是通过CLI方式访问的话,会有一个交互过程界面,你输入的密码信息不被看到。下图是sqoop1和sqoop2简单架构对比:


(2)sqoop2部署步骤
1、下载sqoop-1.99.x版本的sqoop,并进行解压。
2、配置好SQOOP_HOME等环境变量,并用source是~/.bash_profile文件即时生效。
3、配置sqoop server
修改$SQOOP_HOME/server/conf/catalina.properties,修改common.loader属性,加入hadoop2.x的各种lib包,具体指向路径为$HADOOP_HOME/share/hadoop/common/*.jar,
$HADOOP_HOME/share/hadoop/common/lib/*.jar,$HADOOP_HOME/share/hadoop/yarn/*.jar,$HADOOP_HOME/share/hadoop/hdfs/*.jar,$HADOOP_HOME,/share/hadoop/mapreduce/*.jar,没有路径用逗号分开。另外,在$SQOOP_HOME中建个文件夹例如hadoop_lib,然后将这些jar包cp到此文件夹中,最后将此文件夹路径添加到common.loader属性中,这种方法更加直观些。
修改$SQOOP_HOME/server/conf/sqoop.properties,修改org.apache.sqoop.submission.engine.mapreduce.configuration.directory属性值为$HADOOP_HOME/etc/hadoop。
另外,要主要一下$SQOOP_HOME/server/conf/server.xml中的tomcat端口问题,确保这些端口不会和你其他tomcat服务器冲突。
修改配置完毕就可以启动sqoop server了,启动命令:$SQOOP_HOME/bin/sqoop.sh server start,启动完看服务器日志如果没有错误就ok了。
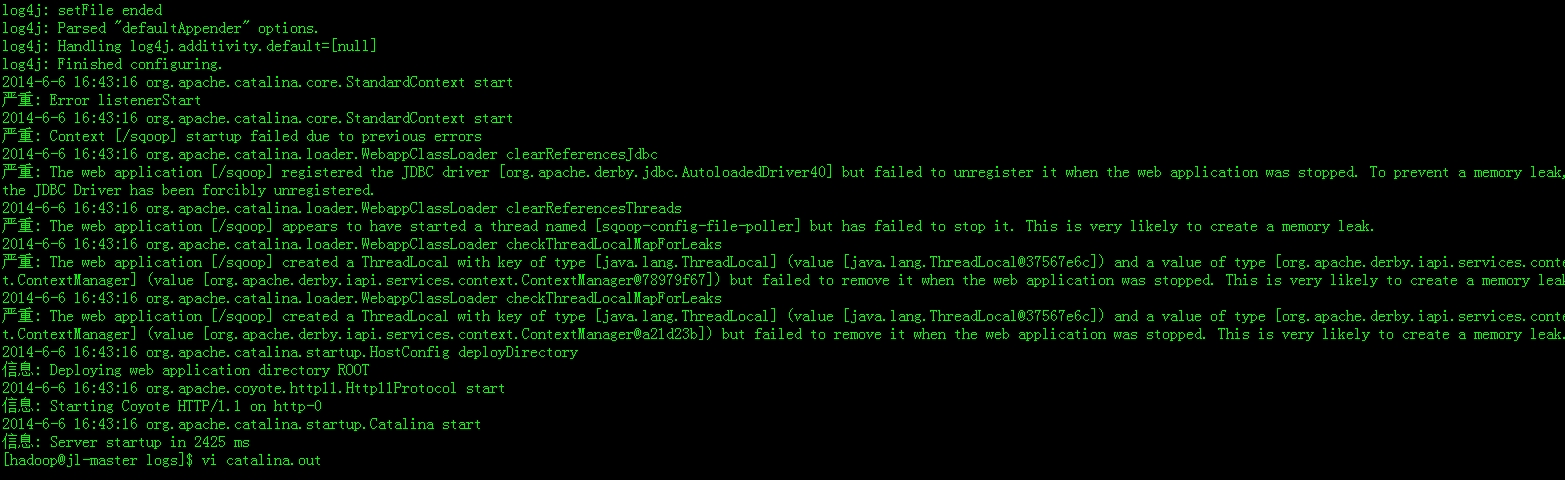
在修改sqoop server配置文件,启动过程中你可能会遇到各种问题,这些问题可能是log4j或者是tomcat的相关错误问题,还是不难解决的。其中包冲突问题我就遇到了,看sqoop server日志:

刚刚看到这个错误信息可能不容易往jar包冲突这方面想,出现这个错误的原因是刚刚$SQOOP_HOME/server/conf/catalina.properties文件common.loader属性中的hadoop2.x lib中的jar包和sqoop server的web项目中的lib中的包冲突了,解决方法可以将$SQOOP_HOME/server/webapps/sqoop/WEB-INF/lib中的log4j-1.2.16.jar删掉就ok了。
三、sqoop2的Java API使用
sqoop2中的java api使用方式和sqoop1是完全不同的。其基本流程为:
1、添加sqoop2的Dependency包。
<dependency>
<groupId>org.apache.sqoop</groupId>
<artifactId>sqoop-client</artifactId>
<version>1.99.3</version>
</dependency>
2、创建Connetion。
3、利用之前创建的ConnectionID去创建job。
4、提交job。
具体代码整理了一下:
import org.apache.sqoop.client.SqoopClient;
import org.apache.sqoop.model.MConnection;
import org.apache.sqoop.model.MConnectionForms;
import org.apache.sqoop.model.MJob;
import org.apache.sqoop.model.MJobForms;
import org.apache.sqoop.model.MSubmission;
import org.apache.sqoop.submission.counter.Counter;
import org.apache.sqoop.submission.counter.CounterGroup;
import org.apache.sqoop.submission.counter.Counters;
import org.apache.sqoop.validation.Status;
public class Sqoop2Access {
public static void main(String[] args) {
//1、--------------Initialization(创建sqoop client)-------------------
String url = "http://localhost:12000/sqoop/";
SqoopClient client = new SqoopClient(url);
client.setServerUrl(url);
//2、--------------Create Connection--------------
//Dummy connection object
MConnection newCon = client.newConnection(1);//1为指定的ConnectionID
//Get connection and framework forms. Set name for connection
MConnectionForms conForms = newCon.getConnectorPart();
MConnectionForms frameworkForms = newCon.getFrameworkPart();
newCon.setName("MyConnection");
//Set connection forms values
conForms.getStringInput("connection.connectionString").setValue("jdbc:mysql://localhost/mysqlTestDB");
conForms.getStringInput("connection.jdbcDriver").setValue("com.mysql.jdbc.Driver");
conForms.getStringInput("connection.username").setValue("root");
conForms.getStringInput("connection.password").setValue("root");
frameworkForms.getIntegerInput("security.maxConnections").setValue(0);
Status status = client.createConnection(newCon);
//检测链接的相关状态
if(status.canProceed()) {
System.out.println("Created. New Connection ID : " +newCon.getPersistenceId());
} else {
System.out.println("Check for status and forms error ");
}
//3、--------------create job(import job)--------------
//Creating dummy job object(利用connectionID去创建job)
MJob newjob = client.newJob(newCon.getPersistenceId(), org.apache.sqoop.model.MJob.Type.IMPORT);
MJobForms connectorForm = newjob.getConnectorPart();
MJobForms frameworkForm = newjob.getFrameworkPart();
newjob.setName("ImportJob");
//Database configuration
connectorForm.getStringInput("table.schemaName").setValue("");
//Input either table name or sql
connectorForm.getStringInput("table.tableName").setValue("table");
//connectorForm.getStringInput("table.sql").setValue("select id,name from table where ${CONDITIONS}");
connectorForm.getStringInput("table.columns").setValue("id,name");
connectorForm.getStringInput("table.partitionColumn").setValue("id");
//Set boundary value only if required
//connectorForm.getStringInput("table.boundaryQuery").setValue("");
//Output configurations
frameworkForm.getEnumInput("output.storageType").setValue("HDFS");
frameworkForm.getEnumInput("output.outputFormat").setValue("TEXT_FILE");//Other option: SEQUENCE_FILE
frameworkForm.getStringInput("output.outputDirectory").setValue("/output");
//Job resources
frameworkForm.getIntegerInput("throttling.extractors").setValue(1);
frameworkForm.getIntegerInput("throttling.loaders").setValue(1);
Status statusJob = client.createJob(newjob);
//检测作业状态相关信息
if(statusJob.canProceed()) {
System.out.println("New Job ID: "+ newjob.getPersistenceId());
} else {
System.out.println("Check for status and forms error ");
}
//4、--------------Job Submission--------------
//Job submission start
MSubmission submission = client.startSubmission(newjob.getPersistenceId());
System.out.println("Status : " + submission.getStatus());
if(submission.getStatus().isRunning() && submission.getProgress() != -1) {
System.out.println("Progress : " + String.format("%.2f %%", submission.getProgress() * 100));
}
System.out.println("Hadoop job id :" + submission.getExternalId());
System.out.println("Job link : " + submission.getExternalLink());
Counters counters = submission.getCounters();
if(counters != null) {
System.out.println("Counters:");
for(CounterGroup group : counters) {
System.out.print("\t");
System.out.println(group.getName());
for(Counter counter : group) {
System.out.print("\t\t");
System.out.print(counter.getName());
System.out.print(": ");
System.out.println(counter.getValue());
}
}
}
if(submission.getExceptionInfo() != null) {
System.out.println("Exception info : " +submission.getExceptionInfo());
}
//Check job status
MSubmission submission1 = client.getSubmissionStatus(newjob.getPersistenceId());
if(submission1.getStatus().isRunning() && submission1.getProgress() != -1) {
System.out.println("Progress : " + String.format("%.2f %%", submission1.getProgress() * 100));
}
//Stop a running job
//submission1.stopSubmission(jid);
}
}另外,如果你使用CLI直接访问的话请参考:http://sqoop.apache.org/docs/1.99.3/CommandLineClient.html ; REST API方式访问请参考:http://sqoop.apache.org/docs/1.99.3/RESTAPI.html 。
四、sqoop2的安装和使用总结
在sqoop2的升级部署以及使用的过程中有诸多吐槽的地方。第一,sqoop2的部署相比于sqoop1复杂的多,虽然官方网站中的install guide中的文档还是比较详细的,但是其中没有考虑到hadoop和sqoop webSite包冲突问题,以及没有对在部署过程中有可能出现的问题进行相关提示。第二,sqoop2和sqoop1的兼容性问题没有做到很好的处理,这个是我个人最不能忍受的地方。其中,体现的最明显的地方就是,之前我在公司写项目的时候是用sqoop1的import或者export脚本去实现HDFS和RDBMS之间的数据转移的,现在我将sqoop1升级到sqoop2之后,import和export脚本再也无法使用了,这样的话我不得不重新将在项目中用sqoop1中的import和export脚本实现的功能用JAVA API去重新编写,这样使得升级超级不平滑,我认为这个是sqoop2做的最不好的地方。
参考文献:http://sqoop.apache.org/docs/1.99.3/index.html
















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}