






梯度裁剪
减少梯度爆炸问题的一种常用技术是在反向传播过程中简单地剪切梯度,使它们不超过某个阈值(这对于递归神经网络是非常有用的;参见第 14 章)。 这就是所谓的梯度裁剪。一般来说,人们更喜欢批量标准化,但了解梯度裁剪以及如何实现它仍然是有用的。
在 TensorFlow 中,优化器的minimize()函数负责计算梯度并应用它们,所以您必须首先调用优化器的compute_gradients()方法,然后使用clip_by_value()函数创建一个裁剪梯度的操作,最后 创建一个操作来使用优化器的apply_gradients()方法应用裁剪梯度:
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
像往常一样,您将在每个训练阶段运行这个training_op。 它将计算梯度,将它们裁剪到 -1.0 和 1.0 之间,并应用它们。 threhold是您可以调整的超参数。
复用预训练层
从零开始训练一个非常大的 DNN 通常不是一个好主意,相反,您应该总是尝试找到一个现有的神经网络来完成与您正在尝试解决的任务类似的任务,然后复用这个网络的较低层:这就是所谓的迁移学习。这不仅会大大加快训练速度,还将需要更少的训练数据。
例如,假设您可以访问经过训练的 DNN,将图片分为 100 个不同的类别,包括动物,植物,车辆和日常物品。 您现在想要训练一个 DNN 来对特定类型的车辆进行分类。 这些任务非常相似,因此您应该尝试重新使用第一个网络的一部分(请参见图 11-4)。
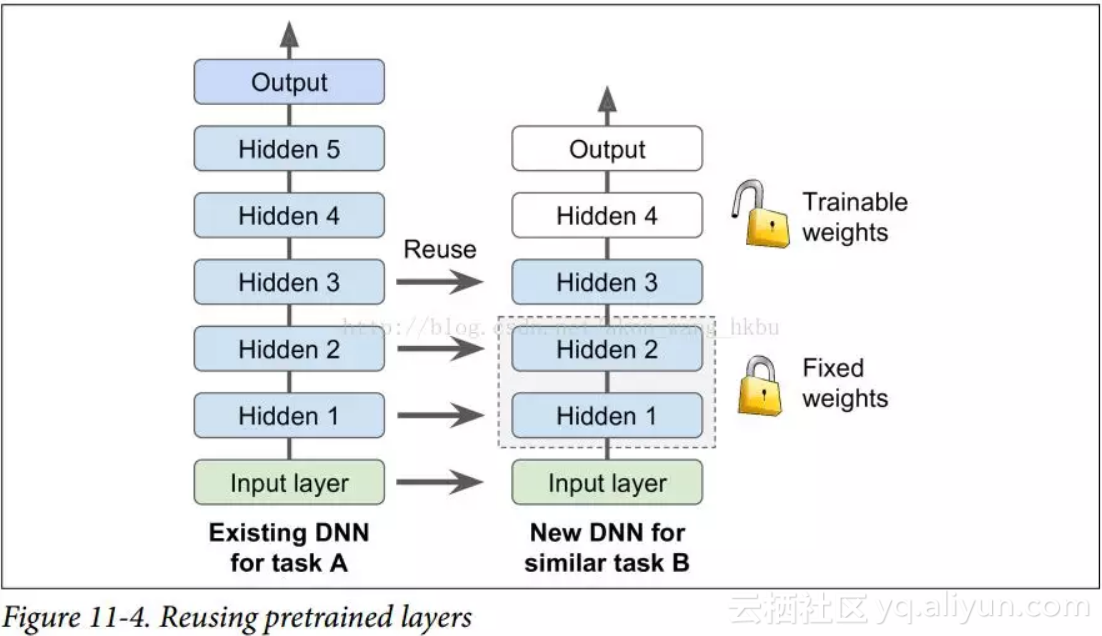
如果新任务的输入图像与原始任务中使用的输入图像的大小不一致,则必须添加预处理步骤以将其大小调整为原始模型的预期大小。 更一般地说,如果输入具有类似的低级层次的特征,则迁移学习将很好地工作。
复用 TensorFlow 模型
如果原始模型使用 TensorFlow 进行训练,则可以简单地将其恢复并在新任务上进行训练:
[...] # construct the original model
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
# continue training the model...
完整代码:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden3 = 50
n_hidden2 = 50 n_hidden4 = 50
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
n_outputs = 10
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
logits = tf.layers.dense(hidden5, n_outputs, name="outputs") with tf.name_scope("loss"): loss = tf.reduce_mean(xentropy, name="loss") with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits, y, 1)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy") learning_rate = 0.01 threshold = 1.0 optimizer = tf.train.GradientDescentOptimizer(learning_rate) grads_and_vars = optimizer.compute_gradients(loss) for grad, var in grads_and_vars]
saver = tf.train.Saver()
training_op = optimizer.apply_gradients(capped_gvs)
init = tf.global_variables_initializer()
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) y: mnist.test.labels})
save_path = saver.save(sess, "./my_new_model_final.ckpt")
print(epoch, "Test accuracy:", accuracy_val)
但是,一般情况下,您只需要重新使用原始模型的一部分(就像我们将要讨论的那样)。 一个简单的解决方案是将Saver配置为仅恢复原始模型中的一部分变量。 例如,下面的代码只恢复隐藏的层1,2和3:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden3 = 50 # reused
n_hidden2 = 50 # reused n_hidden4 = 20 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
n_outputs = 10 # new!
with tf.name_scope("dnn"):
y = tf.placeholder(tf.int64, shape=(None), name="y")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
correct = tf.nn.in_top_k(logits, y, 1)
with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss") with tf.name_scope("eval"):
training_op = optimizer.minimize(loss)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy") with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
[...] # build new model with the same definition as before for hidden layers 1-3
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
restore_saver.restore(sess, "./my_model_final.ckpt")
init = tf.global_variables_initializer() saver = tf.train.Saver() with tf.Session() as sess: init.run()
for iteration in range(mnist.train.num_examples // batch_size): # not shown
for epoch in range(n_epochs): # not shown in the book X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
y: mnist.test.labels}) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # not shown accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
print(epoch, "Test accuracy:", accuracy_val) # not shown
首先我们建立新的模型,确保复制原始模型的隐藏层 1 到 3。我们还创建一个节点来初始化所有变量。 然后我们得到刚刚用trainable = True(这是默认值)创建的所有变量的列表,我们只保留那些范围与正则表达式hidden [123]相匹配的变量(即,我们得到所有可训练的隐藏层 1 到 3 中的变量)。 接下来,我们创建一个字典,将原始模型中每个变量的名称映射到新模型中的名称(通常需要保持完全相同的名称)。 然后,我们创建一个Saver,它将只恢复这些变量,并且创建另一个Saver来保存整个新模型,而不仅仅是第 1 层到第 3 层。然后,我们开始一个会话并初始化模型中的所有变量,然后从原始模型的层 1 到 3中恢复变量值。最后,我们在新任务上训练模型并保存。
任务越相似,您可以重复使用的层越多(从较低层开始)。 对于非常相似的任务,您可以尝试保留所有隐藏的层,只替换输出层。
复用来自其它框架的模型
如果模型是使用其他框架进行训练的,则需要手动加载权重(例如,如果使用 Theano 训练,则使用 Theano 代码),然后将它们分配给相应的变量。 这可能是相当乏味的。 例如,下面的代码显示了如何复制使用另一个框架训练的模型的第一个隐藏层的权重和偏置:

冻结较低层
第一个 DNN 的较低层可能已经学会了检测图片中的低级特征,这将在两个图像分类任务中有用,因此您可以按照原样重新使用这些层。 在训练新的 DNN 时,“冻结”权重通常是一个好主意:如果较低层权重是固定的,那么较高层权重将更容易训练(因为他们不需要学习一个移动的目标)。 要在训练期间冻结较低层,最简单的解决方案是给优化器列出要训练的变量,不包括来自较低层的变量:

第一行获得隐藏层 3 和 4 以及输出层中所有可训练变量的列表。 这留下了隐藏层 1 和 2 中的变量。接下来,我们将这个受限制的可列表变量列表提供给optimizer的minimize()函数。当当! 现在,层 1 和层 2 被冻结:在训练过程中不会发生变化(通常称为冻结层)。
缓存冻结层
由于冻结层不会改变,因此可以为每个训练实例缓存最上面的冻结层的输出。 由于训练贯穿整个数据集很多次,这将给你一个巨大的速度提升,因为每个训练实例只需要经过一次冻结层(而不是每个迭代一次)。 例如,你可以先运行整个训练集(假设你有足够的内存):
hidden2_outputs = sess.run(hidden2, feed_dict={X: X_train})然后在训练过程中,不再对训练实例建立批次,而是从隐藏层2的输出建立批次,并将它们提供给训练操作:
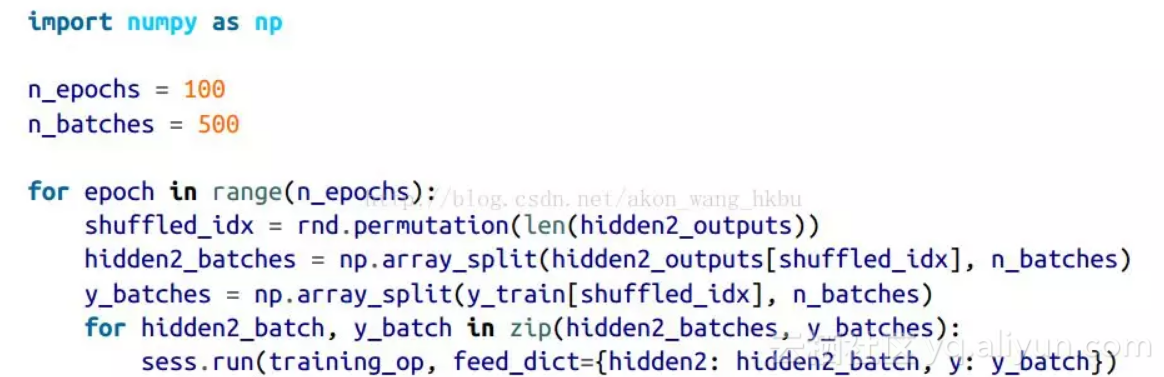
最后一行运行先前定义的训练操作(冻结层 1 和 2),并从第二个隐藏层(以及该批次的目标)为其输出一批输出。 因为我们给 TensorFlow 隐藏层 2 的输出,所以它不会去评估它(或者它所依赖的任何节点)。
调整,删除或替换较高层
原始模型的输出层通常应该被替换,因为对于新的任务来说,最有可能没有用处,甚至可能没有适合新任务的输出数量。
类似地,原始模型的较高隐藏层不太可能像较低层一样有用,因为对于新任务来说最有用的高层特征可能与对原始任务最有用的高层特征明显不同。 你需要找到正确的层数来复用。
尝试先冻结所有复制的层,然后训练模型并查看它是如何执行的。 然后尝试解冻一个或两个较高隐藏层,让反向传播调整它们,看看性能是否提高。 您拥有的训练数据越多,您可以解冻的层数就越多。
如果仍然无法获得良好的性能,并且您的训练数据很少,请尝试删除顶部的隐藏层,并再次冻结所有剩余的隐藏层。 您可以迭代,直到找到正确的层数重复使用。 如果您有足够的训练数据,您可以尝试替换顶部的隐藏层,而不是丢掉它们,甚至可以添加更多的隐藏层。
Model Zoos
你在哪里可以找到一个类似于你想要解决的任务训练的神经网络? 首先看看显然是在你自己的模型目录。 这是保存所有模型并组织它们的一个很好的理由,以便您以后可以轻松地检索它们。 另一个选择是在模型动物园中搜索。 许多人为了各种不同的任务而训练机器学习模型,并且善意地向公众发布预训练模型。
TensorFlow 在 https://github.com/tensorflow/models 中有自己的模型动物园。 特别是,它包含了大多数最先进的图像分类网络,如 VGG,Inception 和 ResNet(参见第 13 章,检查model/slim目录),包括代码,预训练模型和 工具来下载流行的图像数据集。
另一个流行的模型动物园是 Caffe 模型动物园。 它还包含许多在各种数据集(例如,ImageNet,Places 数据库,CIFAR10 等)上训练的计算机视觉模型(例如,LeNet,AlexNet,ZFNet,GoogLeNet,VGGNet,开始)。 Saumitro Dasgupta 写了一个转换器,可以在 https://github.com/ethereon/caffetensorflow。
无监督的预训练
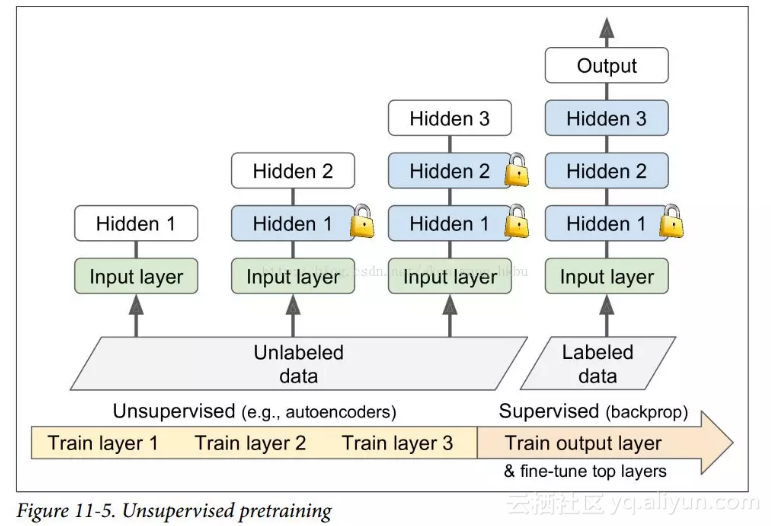
假设你想要解决一个复杂的任务,你没有太多的标记的训练数据,但不幸的是,你不能找到一个类似的任务训练模型。 不要失去所有希望! 首先,你当然应该尝试收集更多的有标签的训练数据,但是如果这太难或太昂贵,你仍然可以进行无监督的训练(见图 11-5)。 也就是说,如果你有很多未标记的训练数据,你可以尝试逐层训练层,从最低层开始,然后上升,使用无监督的特征检测算法,如限制玻尔兹曼机(RBM;见附录 E)或自动编码器(见第 15 章)。 每个层都被训练成先前训练过的层的输出(除了被训练的层之外的所有层都被冻结)。 一旦所有层都以这种方式进行了训练,就可以使用监督式学习(即反向传播)对网络进行微调。
这是一个相当漫长而乏味的过程,但通常运作良好。 实际上,这是 Geoffrey Hinton 和他的团队在 2006 年使用的技术,导致了神经网络的复兴和深度学习的成功。 直到 2010 年,无监督预训练(通常使用 RBM)是深度网络的标准,只有在梯度消失问题得到缓解之后,纯训练 DNN 才更为普遍。 然而,当您有一个复杂的任务需要解决时,无监督训练(现在通常使用自动编码器而不是 RBM)仍然是一个很好的选择,没有类似的模型可以重复使用,而且标记的训练数据很少,但是大量的未标记的训练数据。(另一个选择是提出一个监督的任务,您可以轻松地收集大量标记的训练数据,然后使用迁移学习,如前所述。 例如,如果要训练一个模型来识别图片中的朋友,你可以在互联网上下载数百万张脸并训练一个分类器来检测两张脸是否相同,然后使用此分类器将新图片与你朋友的每张照片做比较。)
在辅助任务上预训练
最后一种选择是在辅助任务上训练第一个神经网络,您可以轻松获取或生成标记的训练数据,然后重新使用该网络的较低层来完成您的实际任务。 第一个神经网络的较低层将学习可能被第二个神经网络重复使用的特征检测器。
例如,如果你想建立一个识别面孔的系统,你可能只有几个人的照片 - 显然不足以训练一个好的分类器。 收集每个人的数百张照片将是不实际的。 但是,您可以在互联网上收集大量随机人员的照片,并训练第一个神经网络来检测两张不同的照片是否属于同一个人。 这样的网络将学习面部优秀的特征检测器,所以重复使用它的较低层将允许你使用很少的训练数据来训练一个好的面部分类器。
收集没有标签的训练样本通常是相当便宜的,但标注它们却相当昂贵。 在这种情况下,一种常见的技术是将所有训练样例标记为“好”,然后通过破坏好的训练样例产生许多新的训练样例,并将这些样例标记为“坏”。然后,您可以训练第一个神经网络 将实例分类为好或不好。 例如,您可以下载数百万个句子,将其标记为“好”,然后在每个句子中随机更改一个单词,并将结果语句标记为“不好”。如果神经网络可以告诉“The dog sleeps”是好的句子,但“The dog they”是坏的,它可能知道相当多的语言。 重用其较低层可能有助于许多语言处理任务。
另一种方法是训练第一个网络为每个训练实例输出一个分数,并使用一个损失函数确保一个好的实例的分数大于一个坏实例的分数至少一定的边际。 这被称为最大边际学习.
更快的优化器
训练一个非常大的深度神经网络可能会非常缓慢。 到目前为止,我们已经看到了四种加速训练的方法(并且达到更好的解决方案):对连接权重应用良好的初始化策略,使用良好的激活函数,使用批量规范化以及重用预训练网络的部分。 另一个巨大的速度提升来自使用比普通渐变下降优化器更快的优化器。 在本节中,我们将介绍最流行的:动量优化,Nesterov 加速梯度,AdaGrad,RMSProp,最后是 Adam 优化。
剧透:本节的结论是,您几乎总是应该使用Adam_optimization,所以如果您不关心它是如何工作的,只需使用AdamOptimizer替换您的GradientDescentOptimizer,然后跳到下一节! 只需要这么小的改动,训练通常会快几倍。 但是,Adam 优化确实有三个可以调整的超参数(加上学习率)。 默认值通常工作的不错,但如果您需要调整它们,知道他们怎么实现的可能会有帮助。 Adam 优化结合了来自其他优化算法的几个想法,所以先看看这些算法是有用的。
动量优化
想象一下,一个保龄球在一个光滑的表面上平缓的斜坡上滚动:它会缓慢地开始,但是它会很快地达到最终的速度(如果有一些摩擦或空气阻力的话)。 这是 Boris Polyak 在 1964 年提出的动量优化背后的一个非常简单的想法。相比之下,普通的梯度下降只需要沿着斜坡进行小的有规律的下降步骤,所以需要更多的时间才能到达底部。
回想一下,梯度下降只是通过直接减去损失函数J(θ)相对于权重θ的梯度,乘以学习率η来更新权重θ。 方程是: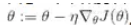 。它不关心早期的梯度是什么。 如果局部梯度很小,则会非常缓慢。
。它不关心早期的梯度是什么。 如果局部梯度很小,则会非常缓慢。

动量优化很关心以前的梯度:在每次迭代时,它将动量矢量m(乘以学习率η)与局部梯度相加,并且通过简单地减去该动量矢量来更新权重(参见公式 11-4)。 换句话说,梯度用作加速度,不用作速度。 为了模拟某种摩擦机制,避免动量过大,该算法引入了一个新的超参数β,简称为动量,它必须设置在 0(高摩擦)和 1(无摩擦)之间。 典型的动量值是 0.9。
您可以很容易地验证,如果梯度保持不变,则最终速度(即,权重更新的最大大小)等于该梯度乘以学习率η乘以1/(1-β)。 例如,如果β = 0.9,则最终速度等于学习率的梯度乘以 10 倍,因此动量优化比梯度下降快 10 倍! 这使动量优化比梯度下降快得多。 特别是,我们在第四章中看到,当输入量具有非常不同的尺度时,损失函数看起来像一个细长的碗(见图 4-7)。 梯度下降速度很快,但要花很长的时间才能到达底部。 相反,动量优化会越来越快地滚下山谷底部,直到达到底部(最佳)。
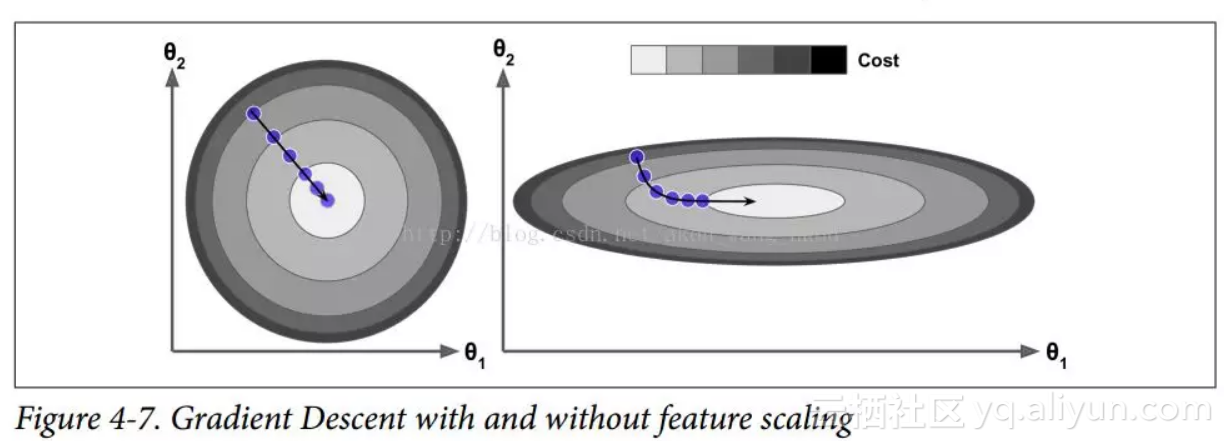
在不使用批标准化的深层神经网络中,较高层往往会得到具有不同的尺度的输入,所以使用动量优化会有很大的帮助。 它也可以帮助滚过局部最优值。
由于动量的原因,优化器可能会超调一些,然后再回来,再次超调,并在稳定在最小值之前多次振荡。 这就是为什么在系统中有一点摩擦的原因之一:它消除了这些振荡,从而加速了收敛。
在 TensorFlow 中实现动量优化是一件简单的事情:只需用MomentumOptimizer替换GradientDescentOptimizer,然后躺下来赚钱!
![]()
动量优化的一个缺点是它增加了另一个超参数来调整。 然而,0.9 的动量值通常在实践中运行良好,几乎总是比梯度下降快。
Nesterov 加速梯度
Yurii Nesterov 在 1983 年提出的动量优化的一个小变体几乎总是比普通的动量优化更快。 Nesterov 动量优化或 Nesterov 加速梯度(Nesterov Accelerated Gradient,NAG)的思想是测量损失函数的梯度不是在局部位置,而是在动量方向稍微靠前(见公式 11-5)。 与普通的动量优化的唯一区别在于梯度是在θ+βm而不是在θ处测量的。

这个小小的调整是可行的,因为一般来说,动量矢量将指向正确的方向(即朝向最优方向),所以使用在该方向上测得的梯度稍微更精确,而不是使用 原始位置的梯度,如图11-6所示(其中∇1代表在起点θ处测量的损失函数的梯度,∇2代表位于θ+βm的点处的梯度)。
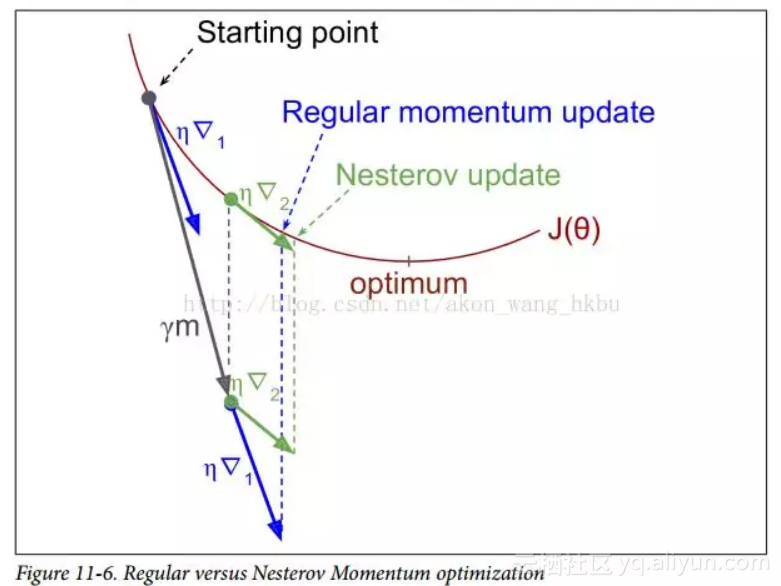
正如你所看到的,Nesterov 更新稍微靠近最佳值。 过了一段时间,这些小的改进加起来,NAG 最终比常规的动量优化快得多。 此外,请注意,当动量推动权重横跨山谷时,▽1继续推进越过山谷,而▽2推回山谷的底部。 这有助于减少振荡,从而更快地收敛。
与常规的动量优化相比,NAG 几乎总能加速训练。 要使用它,只需在创建MomentumOptimizer时设置use_nesterov = True:
![]()
AdaGrad
再次考虑细长碗的问题:梯度下降从最陡峭的斜坡快速下降,然后缓慢地下到谷底。 如果算法能够早期检测到这个问题并且纠正它的方向来指向全局最优点,那将是非常好的。
AdaGrad 算法通过沿着最陡的维度缩小梯度向量来实现这一点(见公式 11-6):

简而言之,这种算法会降低学习速度,但对于陡峭的尺寸,其速度要快于具有温和的斜率的尺寸。 这被称为自适应学习率。 它有助于将更新的结果更直接地指向全局最优(见图 11-7)。 另一个好处是它不需要那么多的去调整学习率超参数η。
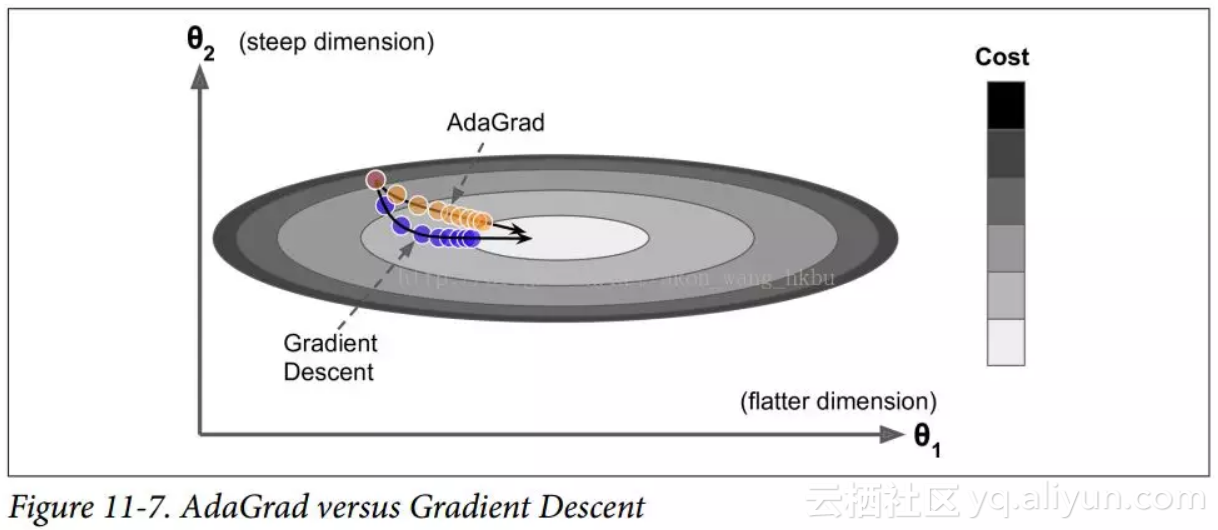
对于简单的二次问题,AdaGrad 经常表现良好,但不幸的是,在训练神经网络时,它经常停止得太早。 学习率被缩减得太多,以至于在达到全局最优之前,算法完全停止。 所以,即使 TensorFlow 有一个AdagradOptimizer,你也不应该用它来训练深度神经网络(虽然对线性回归这样简单的任务可能是有效的)。
RMSProp
尽管 AdaGrad 的速度变慢了一点,并且从未收敛到全局最优,但是 RMSProp 算法通过仅累积最近迭代(而不是从训练开始以来的所有梯度)的梯度来修正这个问题。 它通过在第一步中使用指数衰减来实现(见公式 11-7)。

他的衰变率β通常设定为 0.9。 是的,它又是一个新的超参数,但是这个默认值通常运行良好,所以你可能根本不需要调整它。
正如您所料,TensorFlow 拥有一个RMSPropOptimizer类:
![]()
除了非常简单的问题,这个优化器几乎总是比 AdaGrad 执行得更好。 它通常也比动量优化和 Nesterov 加速梯度表现更好。 事实上,这是许多研究人员首选的优化算法,直到 Adam 优化出现。
Adam 优化
Adam,代表自适应矩估计,结合了动量优化和 RMSProp 的思想:就像动量优化一样,它追踪过去梯度的指数衰减平均值,就像 RMSProp 一样,它跟踪过去平方梯度的指数衰减平均值 (见方程式 11-8)。

T 代表迭代次数(从 1 开始)。
如果你只看步骤 1, 2 和 5,你会注意到 Adam 与动量优化和 RMSProp 的相似性。 唯一的区别是第 1 步计算指数衰减的平均值,而不是指数衰减的和,但除了一个常数因子(衰减平均值只是衰减和的1 - β1倍)之外,它们实际上是等效的。 步骤 3 和步骤 4 是一个技术细节:由于m和s初始化为 0,所以在训练开始时它们会偏向0,所以这两步将在训练开始时帮助提高m和s。
动量衰减超参数β1通常初始化为 0.9,而缩放衰减超参数β2通常初始化为 0.999。 如前所述,平滑项ε通常被初始化为一个很小的数,例如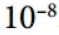 。这些是 TensorFlow 的
。这些是 TensorFlow 的
AdamOptimizer类的默认值,所以你可以简单地使用:
![]()
实际上,由于 Adam 是一种自适应学习率算法(如 AdaGrad 和 RMSProp),所以对学习率超参数η的调整较少。 您经常可以使用默认值η= 0.001,使 Adam 更容易使用相对于梯度下降。
迄今为止所讨论的所有优化技术都只依赖于一阶偏导数(雅可比矩阵)。 优化文献包含基于二阶偏导数(海森矩阵)的惊人算法。 不幸的是,这些算法很难应用于深度神经网络,因为每个输出有n ^ 2个海森值(其中n是参数的数量),而不是每个输出只有n个雅克比值。 由于 DNN 通常具有数以万计的参数,二阶优化算法通常甚至不适合内存,甚至在他们这样做时,计算海森矩阵也是太慢了。
原文发布时间为:2018-06-24
本文作者:ApacheCN【翻译】
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。














 2775
2775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









