







1. 前言
在2016年6月份的苹果全球开发者大会(Worldwide Developers Conference,WWDC)提到了差分隐私技术(Differential Privacy),其作用是能够通过密码学算法对用户的数据进行“加密”上传到苹果服务器。苹果能通过这些“加密”过的数据计算出用户群体的行为模式,但是对每个用户个体的数据却无法解析。
以上这段话摘自知乎的一个讨论问题:苹果的 Differential Privacy 差分隐私技术是什么原理?
注意这里“加密”二字加了双引号。因为严格来说这不是加密技术,只是误称了。加密,是以某种特殊算法对原有信息数据进行处理,使得攻击者A 即使获得已加密的信息c ,但不知道解密方法Dec(·)或者密钥k,以可忽略概率negl猜出原文m。
接下来,我们来看一下究竟什么是差分隐私技术。本文是在 龙星计划-2016年课程-隐私保护理论与实践 的启发下,通过阅读一些学术资料及博客文章,整理出来的。首先,非常感谢课程的主讲者 李宁辉 教授及其他各位老师,以及承办单位 复旦大学,本次学习让我受益匪浅!

2. 差分隐私概念
2.1 数学定义
我们来看一下复旦大学各位老师用心编写的教材Differential Privacy: From Theory to Practice 中,对差分隐私的数学定义:
Definition 2.1 (ϵ-Differential Privacy) An algorithm A satisfies ϵ-differential privacy (ϵ-DP) if and only if for any datasets D and D' that differ on one element, we have
![]() (2.1)
(2.1)
The condition (2.1) is equivalent to
![]() (2.2)
(2.2)
2.2 相邻数据集
章节2.1 中的数据集D 和D' 是相邻数据集(Adjacent Dataset),它们具有相同的属性结构,即在数据库中具有相同的Schema。
在无界DP(Unbounded DP,UDP)中,若D 可以通过从D' 中增加或删除一个元素(或条目)得到,那么D 和D' 是相邻的(neighboring)。在有界DP(Bounded DP,BDP)中, 若D 可以通过从D' 中替换一个元素(或条目)得到, 那么D 和D' 是相邻的。
我们可以留意到,若一个算法在UDP 环境下满足 ϵ-DP ,那么它在BDP 环境下满足 2ϵ-DP ,因为替换操作可以通过先删除后添加操作得到。
2.3 具体案例
那么差分隐私到底是什么呢?为什么Apple 可以用它来实现信息安全?这里举一个例子来帮助理解,考虑一个医疗数据场景:

上图显示了一个医疗数据集D,其中每条记录表示一个患者是否患有癌症,当数据集作为科研数据或者社会调研被发布出来时,他对用户仅提供前n 行的统计查询服务,这里选取计数查询,用count (n) 表示前n 行里有多少个人患有癌症。
这里攻击者A 知道Jack 排在第3行(医疗数据记录一般按一定顺序排列,例如身份证号等),由于不能直接访问D(注意 D 仅提供 count (n) 查询服务), A 一开始并不知道Jack 的第二列属性值是否为1,但是A 可以通过如下攻击获取Jack 的个人隐私信息(是否患有癌症):count (3) - count (2)。
那么差分隐私技术在该案例中是如何保证信息安全的呢?我们可以把删除掉Jack 一行的数据集(或修改)看成D',要求A 根据D 获取的count 值,与根据D' 获取的count 值的概率分布差不多,假设count (3) 的输出可能来自{1.5, 2},那么count (2) 以近似的概率输出{1.5, 2} 中的任意值,具体证明与分析看下面的Laplace 机制。 ϵ-DP 的 ϵ 值就是用来控制概率分布的相似性,当 ϵ 越小时,exp( ϵ ) 越接近于1。
2.4 为什么要用DP
数据集D 发布时,通过删除标识符属性(例如姓名、ID号等)能够在一定程度上保护个人隐私,但这远远不够,要特别注意到,数据集中还有其他属性,例如:生日、性别、居住地、是否抽烟、是否饮酒等,用这些信息来猜测个人身份,是不是类似数据挖掘中的分类?即将一个没有类别标签的条目识别归类,训练集看成敌手A 从其它地方获得的具有标识符属性的与 D 有属性交集的数据集T,类别标签当然就是某个人。在这方面,美国曾经有几个经典案例,被起诉方通常都是赔了几百万。
在隐私保护方面,k-anonymity 及其扩展模型影响深远且被广泛研究,但随着研究的深入,该系列模型也面临着许多新型攻击的挑战,于是2006年就出现了DP 。DP 在攻击者A 在拥有最大背景知识条件下,仍能抵御各种攻击,为什么这里说 A 拥有最大背景知识呢?参考章节2.3 中的案例,即使 A 拥有了除Jack 外的数据集D' ,仍以negl + 1/2 的概率猜Jack 是否患有癌症。这时,对比 k-anonymity 等技术,就可以知道DP 的优越处(最大背景知识)。
3. 差分隐私技术实现机制
3.1 Laplace 机制
对数值型计算(numerical function),使用Laplace 机制就可以实现DP。例如章节2.3 中的案例,假设函数f 是一个提供 ϵ-DP 的查询函数,f (n) = count (i) + noise,其中noise 是服从某种随机分布的噪声。记X = noice,那么有
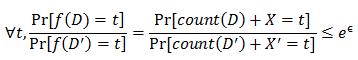
记d = count (D) - count (D'),那么有

为了保证上述式子恒成立,我们需要保证d ≤ △f,△f (敏感度)的定义如下:
![]()
到这里就可以看出,其实噪音的分布就是拉普拉斯分布![]() ,记
,记![]() ,有
,有
![]()
则有 ,满足差分隐私的数学定义。总而言之,Laplace 机制就是,在原本函数输出值上加上
,满足差分隐私的数学定义。总而言之,Laplace 机制就是,在原本函数输出值上加上 ![]() 噪声。我们来看一幅图加深理解,
噪声。我们来看一幅图加深理解,

当f 噪声为0时,即输出count 时,Pr 概率是最高的;当f(D) 以Pr 概率产生噪声noise,f(D') 以Pr' 概率产生噪声noise',两者输出值相同为count' 时, Pr 与 Pr' 的比值控制在exp( ϵ ) 内。
3.2 Exponential 机制
龙星计划-2016年课程-隐私保护理论与实践 教材Differential Privacy: From Theory to Practice 一书中提到:While the Laplace mechanism provides a solution to handle numeric queries, it cannot be applied in non-numeric valued queries. This motivates the development of the exponential mechanism, which can be applied whether a function's output is numerical or categorical.
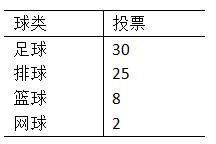
Laplace 机制仅适用于数值型查询结果,而在许多应用中,查询结果为非数值型的,例如一种方案的选择。我们举个例子,在一个数据集D 中,我们想要得到出现次数最多的条目o;或者举一个更形象的例子,拟举办一场球类比赛,候选项目有{ 足球,排球,篮球,网球 },参赛者们对此进行投票,以投票次数最多的项目为最终决策,我们不能说[ f (D) = '足球' + noise ] 概率分布近似于[f (D') = ' 足球' + noise' ],非数值型的值相加没有意义,这时就出现了指数机制(exponential mechanism)。
我们记O 为候选项目集合,o 为候选项目,函数q(D, o) 输出条目o 在D 中的出现次数,一个算法![]() 输出 o∈O 的概率正比于
输出 o∈O 的概率正比于![]() ,则说M 是满足 ϵ-DP 的指数机制。其中
,则说M 是满足 ϵ-DP 的指数机制。其中![]() ,称为敏感度。上述案例中△q = 1。
,称为敏感度。上述案例中△q = 1。
接下来证明指数机制是满足 ϵ-DP 的,记D' 为D 的相邻数据集,有

即 ,
,
由于D 与D' 的对称性可知, ,接下来为整个证明的重点,
,接下来为整个证明的重点,
 证毕。
证毕。
这里贴出《熊 平等:差分隐私保护及其应用》综述一文中的一幅图表,我们来看一下指数机制的应用示例:
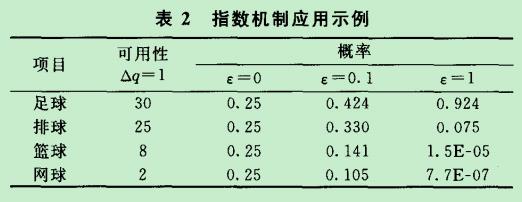
原文讲到,在 ε 较大时(如 ε =1),可用性最好的选项被输出的概率被放大;当 ε 较小时,各选项在可用性上的差异被平抑,其被输出的概率也随着 ε 的减小而趋于相等。
3.3 DP 中的 ε 值
差分隐私中的 ε 值控制隐私保护水平。回想差分隐私的数学定义,当 ε 值越小时,隐私保护水平越高,当 ε = 0 时,相邻数据集以一样的概率分布输出,当然这样也就丧失了数据可用性,因此 ε 值的选取通常需要衡量考虑信息安全性与数据可用性。
3.4 DP 中的敏感度(sensitivity)
差分隐私中的敏感度用来控制噪声大小,而当噪声过大时,则会影响数据可用性,敏感度分为全局敏感度(Global Sensitivity)和局部敏感度(Local Sensitivity), 接下来我们来看这是怎么一回事。
全局敏感度定义如下:

局部敏感度定义如下:

我们来举一个例子,设f (D) = median(x1, x2, ..., xn) 为求已排序序列向量D 的中位数,其中0 ≤ xi ≤ k。考虑以下极端情况:


那么GS f (D) = k,注意全局敏感度的定义中的“任意的相邻数据集”,然后取max,那么我们就直接考虑极端情况。
我们再来看局部敏感度,注意定义,指定了“输入为数据集D ”,我们来看

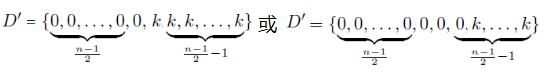
那么此时LS f (D) = 0,而

此时 LS f (D) = k,从而可知 GS f (D) = max( LS f (D) ) 。
当指定了数据集D,如果采用全局敏感度,则会导致需要加入很大的噪声,从而使得数据可用性不好;而采用局部敏感度时,在一定程序上又泄露数据分布信息。这时就有了平滑敏感度(Smooth Sensitivity)。

后记
本文是在 龙星计划-2016年课程-隐私保护理论与实践 的启发下 ,通过搜索博客资料,阅读综述 《熊 平等:差分隐私保护及其应用》 一文整理出来,差分隐私查询的组合性质、数据发布以及在数据挖掘方面的应用可以阅读该综述文章。这里非常感谢各位科研人员,让我受益匪浅!
Reference
Differential Privacy: From Theory to Practice (Ninghui Li, Wei-Yen Day, Min Lv, Dong Su, Weining Yang July 1, 2016)
熊平, 朱天清, 王晓峰. 差分隐私保护及其应用[J]. 计算机学报, 2014, 37(01):101-122.
Differential Privacy: a short tutorial















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









