







现在深度学习各种技术,概念,模型让人眼花撩乱,每次进展日新月异。但其实不用担心,关键点就那么几个,卷积算一个,lstm/rnn算一个。其实换个loss function,加几个层,改一个优化函数,或者换个训练数据集,都在不停的刷论文罢了。
但注意力模型不一样,这个是有生产力的。
一个最直观的说明,啥是注意力。想想我们在人群中,无意间看到一个多年认识的一个老朋友,或者说找一个人吧,我们不用一张张脸去扫描吧。或者你过马路的时候,你会从街左边一直扫描到街右边么,更多注意红绿灯和来往车辆。这就是人类观察事物的注意力分配(人类是为了省能量)。
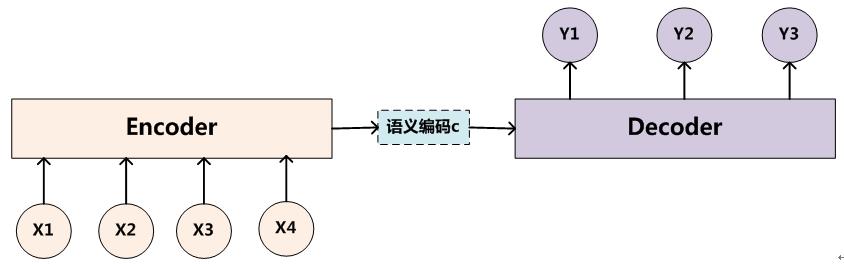
上面是传统的seq2seq模型,encoder产生了语义编码信息c(其实就是RNN产生的hidden_state)。然后y用这个hidden做为输入状态。
先直观理解一下seq2seq。
输入是一个单词序列,输出也是一个单词序列。可以是同一种语言,比如做文摘,或者不同语言,那就是做翻译。所以seq2seq是一个较通用的模型框架。

encoder就是对输入X序列进行编码。
C = F(X) = F(x1,x2,x3...,xn),编码保存在C里。
然后把C传递给解码器进行解码:Y=G(C,y1,y2....,yn-1)。这里可以看到,对于每一步yi,我们使用的C都是一样的,这显然是不合理的。在翻译一个句子的时候,每个时刻需要关注的词肯定是有所区别的。而且rnn/lstm最后的输入是权重最大,这就更不合理了。所以google有一个模型里,把词序倒过的效果会更好,其实就有这样的原因。
没有注意力模型,相当于我们读了一个英文句子Tom chase jerry,我们记录它的语义在C里。然后我们开始翻译成中文,第一个词“汤姆”,但第二词的时候G(C,汤姆),还是用C的语义。但在翻译杰瑞的时候,jerry的权重应该更高才对。
![]()
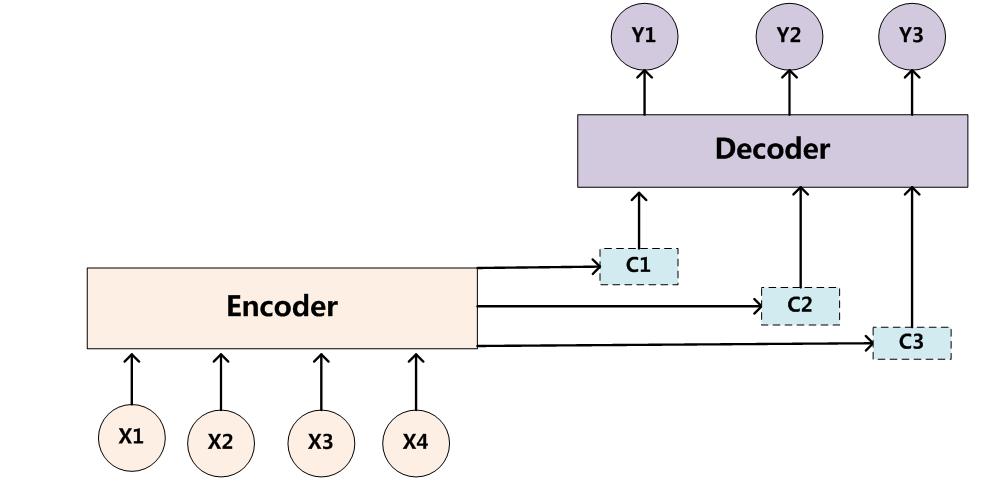
就是每一步翻译的时候,输入的语义编码是有权重上的区别的。
![]()

如果用的rnn,这里f2输出就是编码器hidden_state(注意不是最终的,是中间态,其实就是每个input的output)。
那这个概率权值怎么来,就是注意力模型的关键所在了。
很多论文里都会定义这么一个函数:F(hj,Hi),就是需要对齐单词。
pytorch的代码实现片段如下:
def forward(self, input, hidden, encoder_output, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
#这里计算注意力权重,input和encode的context线性
#把hidden和input cat之后,线性组合成softmax概率
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)))
#和每个output做bmm,不广播,encoder提供的每个output中间态做加权,得到新的hidden
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
#这一步也是常规的,embedded+hidden之后做线性
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
就是这样,就实现了权重注意力的分配。明天继续在这个问题上深化一下,写一个从输出到输出计算的过程,这样看得更直观一些。
关于作者:魏佳斌,互联网产品/技术总监,北京大学光华管理学院(MBA),特许金融分析师(CFA),资深产品经理/码农。偏爱python,深度关注互联网趋势,人工智能,AI金融量化。致力于使用最前沿的认知技术去理解这个复杂的世界。
扫描下方二维码,关注:AI量化实验室(ailabx),了解AI量化最前沿技术、资讯。















 3193
3193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









