







因为数据是 Stream 的形式,所以来一条就计算分裂不仅让模型很重,同时信息增益也不确定;然而,堆积很多的数据再计算明显不适用于online learning,所以应该选择一个 临界值,这个值又能够最大程度的表现样本分布,同时又不至于使模型很重,VFDT就是这样的模型,借助了Hoffding bound来解决上述问题。
Hoeffding bound可以描述为如下:

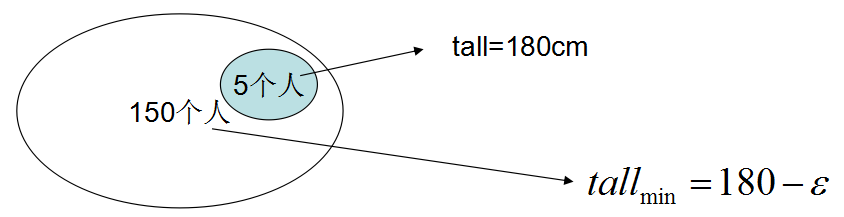
使用更为通俗的语言描述的话:有15000个人的集合,要测这15000人的平均身高,那么使用抽样的方法,不需要测试每一个人的身高。随机抽样50人,测得身高180cm,那么霍夫丁不等式人为,这15000人的均身高最低是180-e,如图:
那将上述Hoeffding bound的思想应用于 Decision tree同样,DT的关键是选择分裂点,选择分裂点的方式是用G( Information Gain ),
如果G(A) - G(any)>0,那么就认为 A 作为当前 node 的分裂点最好。 但是这仅仅是在抽样 dataSet 中成立,要是让其在同样分布无穷大的 DS 中同样成立,只要让 G(A) - G(any) 的最小值是 >0 即可,
根据 Hoeffding bound,G最小值为= G(A) - G(any) - e,那么根据上面的 e 公式:
R是 classLabel的取值范围,若是 discrete attri 则R=log2|class|,这是根据信息论里得来,若是 continuous attri ,R=最大-最小。
δ:错误率,则置信度=1-δ。
n:就是要的样本数,In other words, in order to make the correct decision with error probability δ, it is sufficient to observe enough examples to make e smaller than G(A) - G(any)。
最后上一张流程图 和 pseudo-code:


总结:
VFDT是一种基于Hoeffding不等式建立决策树的方法,透过不断地将叶节点替换为决策节点而生成,其中每个叶节点都保存有关于属性值的统计信息。
当一个新样本到达后,在树的每个节点都进行划分测试(判断?),根据不同的属性取值进入不同的分支最终到达树的叶节点。
在数据到达叶节点后,节点上的统计信息会被更新,同时该节点基于属性的测试值将重新计算。
http://blog.sina.com.cn/s/blog_6292266201018xjt.html
信息增益” (Information Gain)来衡量一个属性区分以上数据样本的能力。信息增益量越大,这个属性作为一棵树的根节点就能使这棵树更简洁,比如说一棵树可以这么读成,如果风力 弱,就去玩;风力强,再按天气、温度等分情况讨论,此时用风力作为这棵树的根节点就很有价值。如果说,风力弱,再又天气晴朗,就去玩;如果风力强,再又怎 么怎么分情况讨论,这棵树相比就不够简洁了。















 6174
6174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









