






简单说明
因为要测试不同麦克风、不同的语音识别平台的语音识别效果,所以写了一个超简陋的小工具,主要是为了给公司的各位大大们提供参考。
对于声音的处理部分,集成一下之前写的《唤醒》和《语音交互》,就是一个语音对话的小项目了。
因为代码写的比较糙,懂的也不多,所以实际部署上的语音对话内容,通过语音来唤醒的内容效果是最差的,会比较慢。(在自己的开发本子上并不是这种效果,主要也确实是自己的机器比部署的物理机要好。。。哎,推脱个责任吧。。。哈哈哈。)
运行后的效果:
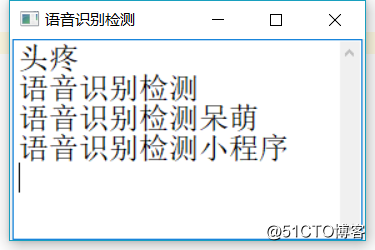
代码地址:
https://github.com/feature09/voice_test_tool
部分代码一:声音的提取
- 去掉了唤醒接入的内容。
- 去掉了长时间静默后关闭闲聊的内容。
# -*- coding: utf-8 -*-
# @Time :2018/11/22
# @Author :qpf
import time
import math
import wave
import threading
from queue import Queue
import numpy as np
import pyaudio
import asr_module
# 从配置文件加载部分数据
def get_args():
with open('args.txt', 'r', encoding='utf-8') as atr:
lines = atr.readlines()
for line in lines:
head = line.replace('\n', '').split('=')[0]
value = line.replace('\n', '').split('=')[1]
if head == 'mic_choice':
return int(value)
else:
return 1
# 选择百度1,科大讯飞2
choice = get_args()
asr = ''
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
# 输入设备的
MIC_INDEX = None
# 是否处于录音状态,默认否(0)
record_flag = 0
be_stream_data = []
frames = []
peak = np.float64(0)
# ## 控制参数
# 当唤醒后处于对话状态,静音多久后,需要重启唤醒。秒。
args_wake_second = 30
args_wake = args_wake_second * 1
# 有效声音的数值。
# 设置分贝数
args_valid_voice_db = 60
args_valid_voice = np.float64(args_valid_voice_db * 9)
# 自动关闭录音的时间数值(最长说话的录音时间)
args_auto_close_record_second = 90
args_auto_close_record = math.ceil(args_auto_close_record_second / 0.05)
# 声音被看做静音的值
args_silence_db = 30
args_silence = np.float64(args_silence_db * 9)
# 说话时允许的停顿时长
args_pause_speak_second = 0.5
args_pause_speak = args_pause_speak_second * 10
# 最小说话时间数值,time为秒
args_min_speak_second = 0.5
args_min_speak = math.ceil(args_min_speak_second / 0.05)
# 录音前的最长采集时间,单位秒
pre_record_time = 2
pre_record = math.ceil(pre_record_time / 0.05)
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
input_device_index=MIC_INDEX, # 添加输入的索引
frames_per_buffer=CHUNK)
WAVE_OUTPUT_FILENAME = "record-audio.wav"
# 监听声音并采集数据
def voice_value():
print("开启监听")
global peak
global frames
global be_stream_data
while True:
stream_data = stream.read(CHUNK)
data = np.fromstring(stream_data, dtype=np.int16)
peak = np.average(np.abs(data)) * 2
# 开启录音数据的采集
if record_flag == 1:
frames.append(stream_data)
# 需要延迟一定的时间,否则会录不清晰
time.sleep(0.05)
# 采集录音前的数据
else:
if len(stream_data) <= 0:
be_stream_data.append(b'')
else:
# 收集录音前的数据
be_stream_data.append(stream_data)
time.sleep(0.05)
if len(be_stream_data) >= pre_record:
be_stream_data.pop(0)
# 实现录音
def record(re_frames):
print("开始录音")
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(re_frames))
wf.close()
print("关闭录音")
# 控制声音处理的逻辑
def control_voice(q):
global record_flag
global frames
global be_stream_data
global asr
# 统计录音时的时间次数
peak_v = 0
# 统计不在录音时的时间
peak_t = 0
while True:
# 当不在录音状态的时候
if record_flag == 0:
# 判断声音大小
if peak > args_valid_voice:
record_flag = 1
else:
# 不在录音状态下的时间统计
peak_t = peak_t + 1
time.sleep(1)
# 当在录音状态的时候
if record_flag == 1:
peak_t = 0
# 录音时间过长则自动关闭录音
if len(frames) >= args_auto_close_record:
record_flag = 0
print("自动关闭录音")
# 执行录音功能
record(frames)
# 语音识别
asr = asr_module.main(choice)[0]
print('语音识别结果: '.format(choice), asr)
set_data(q)
time.sleep(1)
be_stream_data = [] # 清空录音前的数据
frames = []
# 当声音持续小于静默时,不开启录音数据的采集
if peak < args_silence:
# 持续多久
peak_v = peak_v + 1
time.sleep(0.1)
else:
peak_v = 0
# 当声音分贝持续没达到值的时候,就会将控制变为0
if peak_v >= args_pause_speak:
record_flag = 0
peak_v = 0
# 声音太小不会执行录音,清空声音流数据重头执行
if len(frames) >= args_min_speak:
# 执行录音功能
record(be_stream_data + frames)
print("控制器执行录音")
# 语音识别
asr = asr_module.main(choice)[0]
print('语音识别结果: '.format(choice), asr)
set_data(q)
time.sleep(1)
else:
print("时间太短不执行录音")
frames = []
be_stream_data = [] # 清空录音前的数据
def set_data(q):
if q is not None:
q.put(asr)
print('发送到队列:', asr)
class Main:
def main(self, q=None):
# 开启声音的监听
threading.Thread(target=voice_value).start()
# 对声音进行控制
threading.Thread(target=control_voice, args=(q,)).start()
def get_args():
with open('args.txt', 'r', encoding='utf-8') as atr:
lines = atr.readlines()
for line in lines:
head = line.replace('\n', '').split('=')[0]
value = line.replace('\n', '').split('=')[1]
if head == 'mic_choice':
return int(value)
else:
return 1
# 测试
if __name__ == '__main__':
q1 = Queue()
m = Main()
m.main(q=q1)
部分代码二:通过wxpython实时显示结果数据
# -*- coding: utf-8 -*-
# @Time :2019/2/25
# @Author :qpf
from threading import Thread
import wx
data = ''
class SpeechGui(wx.Frame):
def __init__(self, parent, q):
self.title = '语音识别检测'
wx.Frame.__init__(self, parent, id=-1, title=self.title,
size=(300, 200))
self.panel = wx.Panel(self)
self.box = wx.BoxSizer(wx.VERTICAL)
self.center = wx.TextCtrl(self.panel, -1, size=(280, 180), style=wx.TE_READONLY | wx.TE_MULTILINE)
font = wx.Font(pointSize=18, family=wx.FONTFAMILY_DECORATIVE, style=wx.FONTSTYLE_NORMAL,
weight=wx.FONTWEIGHT_NORMAL)
self.center.SetFont(font)
self.box.Add(self.center, 0, wx.ALIGN_CENTER)
self.panel.SetSizer(self.box)
Thread(target=recv, args=(self.center, q,)).start()
def main(q=None):
app = wx.PySimpleApp()
frame = SpeechGui(None, q=q)
frame.Show()
app.MainLoop()
def recv(obj, q=None):
global data
cache = ''
while True:
if q is not None:
if q.empty() is not True:
data = q.get()
print('接收队列数据:', data)
# 每行显示9个字
for i in range(0, len(data), 9):
str_split = data[i:i + 9]
str = str_split + '\n'
cache = cache + str
obj.AppendText(cache)
cache = ''
else:
data = '呵呵哈哈哈哈哈或'
obj.AppendText(data)
if __name__ == '__main__':
main()
转载于:https://blog.51cto.com/feature09/2355341














 3271
3271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









