




 本文介绍了智能音箱的语音交互系统,包括唤醒、ASR、NLP、TTS和Skill等流程。讨论了唤醒词的选择、误唤醒的压制策略,以及ASR的声学和语言模型。此外,还概述了NLP的自然语言理解、技能处理以及TTS的语音合成技术,强调了测试指标的重要性。
本文介绍了智能音箱的语音交互系统,包括唤醒、ASR、NLP、TTS和Skill等流程。讨论了唤醒词的选择、误唤醒的压制策略,以及ASR的声学和语言模型。此外,还概述了NLP的自然语言理解、技能处理以及TTS的语音合成技术,强调了测试指标的重要性。
随着AI技术的发展,智能语音交互技术也得到了巨大的发展和应用。由于语音是最自然的交互形态之一,有着输入效率高、门槛低、方便解放双手以及能有效进行情感交流的优势,使得智能音箱成为语音交互的典型应用产品。智能音箱的背后是一套智能语音交互系统平台,由于笔者最近参与了公司内的智能语义平台与智能音箱的测试开发项目,对这一系统有了基本的认知和理解,本文就语音交互平台的相关概念和基本测试指标进行一下讲解和介绍。

一个完整的语音交互流程

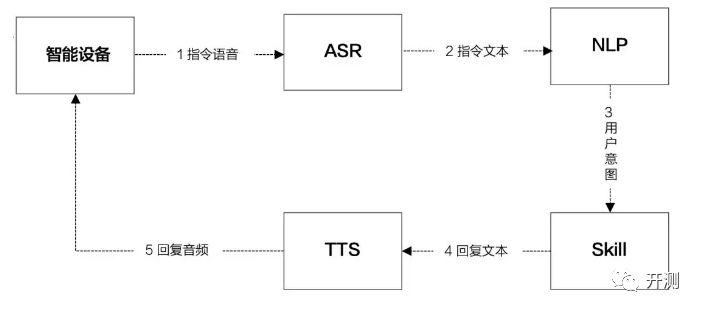
如下图所示,一次完整的语音交互,包含:唤醒→ASR→NLP→TTS→Skill的流程。
下面主要对系统中的主要流程进行讲解。
唤醒
唤醒即激活音箱设备,智能音箱有别于智能手机的语音交互,需要先激活音箱,激活的办法有两类。
传统的方式是**:**通过按键激活,例如:锤子的大卫和Siri音箱,增加了外设的按钮,可以点击按钮激活音箱进行说话。
业界的普遍做法是**:**通过设置激活词来唤醒音箱,例如:“小宝小宝”,“小爱同学”,“小雅小雅”。
为什么唤醒词普遍是4音节,而不是中国人更习惯的3音节或者2音节?
这是因为音节越短,误唤醒的问题就会越严重。
**误唤醒是指:**设备被环境音错误激活。
误唤醒的压制是行业难题,除了模型优化,还有几种普遍的做法:
01
云端2次校验——即将用户的语音上传到云端进行2次确认,再决定本地是否响应,但是带来的弊端就是唤醒响应时间被拉长。
一般设备的唤醒检测模块都是放在本地的,这是为了可以快速响应,本地响应可以将响应时间控制在300-700ms之间。如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









