






上周Spark1.2刚公布,周末在家没事,把这个特性给了解一下,顺便分析下源代码,看一看这个特性是怎样设计及实现的。
/** Spark SQL源代码分析系列文章*/
(Ps: External DataSource使用篇地址:Spark SQL之External DataSource外部数据源(一)演示样例 http://blog.csdn.net/oopsoom/article/details/42061077)
一、Sources包核心
Spark SQL在Spark1.2中提供了External DataSource API。开发人员能够依据接口来实现自己的外部数据源,如avro, csv, json, parquet等等。
在Spark SQL源代码的org/spark/sql/sources文件夹下,我们会看到关于External DataSource的相关代码。
这里特别介绍几个:
1、DDLParser
专门负责解析外部数据源SQL的SqlParser。解析create temporary table xxx using options (key 'value', key 'value') 创建载入外部数据源表的语句。
protected lazy val createTable: Parser[LogicalPlan] =
CREATE ~ TEMPORARY ~ TABLE ~> ident ~ (USING ~> className) ~ (OPTIONS ~> options) ^^ {
case tableName ~ provider ~ opts =>
CreateTableUsing(tableName, provider, opts)
}2、CreateTableUsing
一个RunnableCommand。通过反射从外部数据源lib中实例化Relation。然后注冊到为temp table。
private[sql] case class CreateTableUsing(
tableName: String,
provider: String, // org.apache.spark.sql.json
options: Map[String, String]) extends RunnableCommand {
def run(sqlContext: SQLContext) = {
val loader = Utils.getContextOrSparkClassLoader
val clazz: Class[_] = try loader.loadClass(provider) catch { //do reflection
case cnf: java.lang.ClassNotFoundException =>
try loader.loadClass(provider + ".DefaultSource") catch {
case cnf: java.lang.ClassNotFoundException =>
sys.error(s"Failed to load class for data source: $provider")
}
}
val dataSource = clazz.newInstance().asInstanceOf[org.apache.spark.sql.sources.RelationProvider] //json包DefaultDataSource
val relation = dataSource.createRelation(sqlContext, new CaseInsensitiveMap(options))//创建JsonRelation
sqlContext.baseRelationToSchemaRDD(relation).registerTempTable(tableName)//注冊
Seq.empty
}
}2、DataSourcesStrategy
在 Strategy 一文中。我已讲过Streategy的作用,用来Plan生成物理计划的。
这里提供了一种专门为了解析外部数据源的策略。
最后会依据不同的BaseRelation生产不同的PhysicalRDD。
不同的BaseRelation的scan策略下文会介绍。
private[sql] object DataSourceStrategy extends Strategy {
def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {
case PhysicalOperation(projectList, filters, l @ LogicalRelation(t: CatalystScan)) =>
pruneFilterProjectRaw(
l,
projectList,
filters,
(a, f) => t.buildScan(a, f)) :: Nil
......
case l @ LogicalRelation(t: TableScan) =>
execution.PhysicalRDD(l.output, t.buildScan()) :: Nil
case _ => Nil
}
该文件定义了一系列可扩展的外部数据源接口,对于想要接入的外部数据源,我们仅仅需实现该接口就可以。
里面比較重要的trait RelationProvider 和 BaseRelation,下文会具体介绍。
4、filters.scala
该Filter定义了怎样在载入外部数据源的时候,就进行过滤。注意哦,是载入外部数据源到Table里的时候,而不是Spark里进行filter。
这个有点像hbase的coprocessor,查询过滤在Server上就做了,不在Client端做过滤。
5、LogicalRelation
封装了baseRelation,继承了catalyst的LeafNode,实现MultiInstanceRelation。
二、External DataSource注冊流程
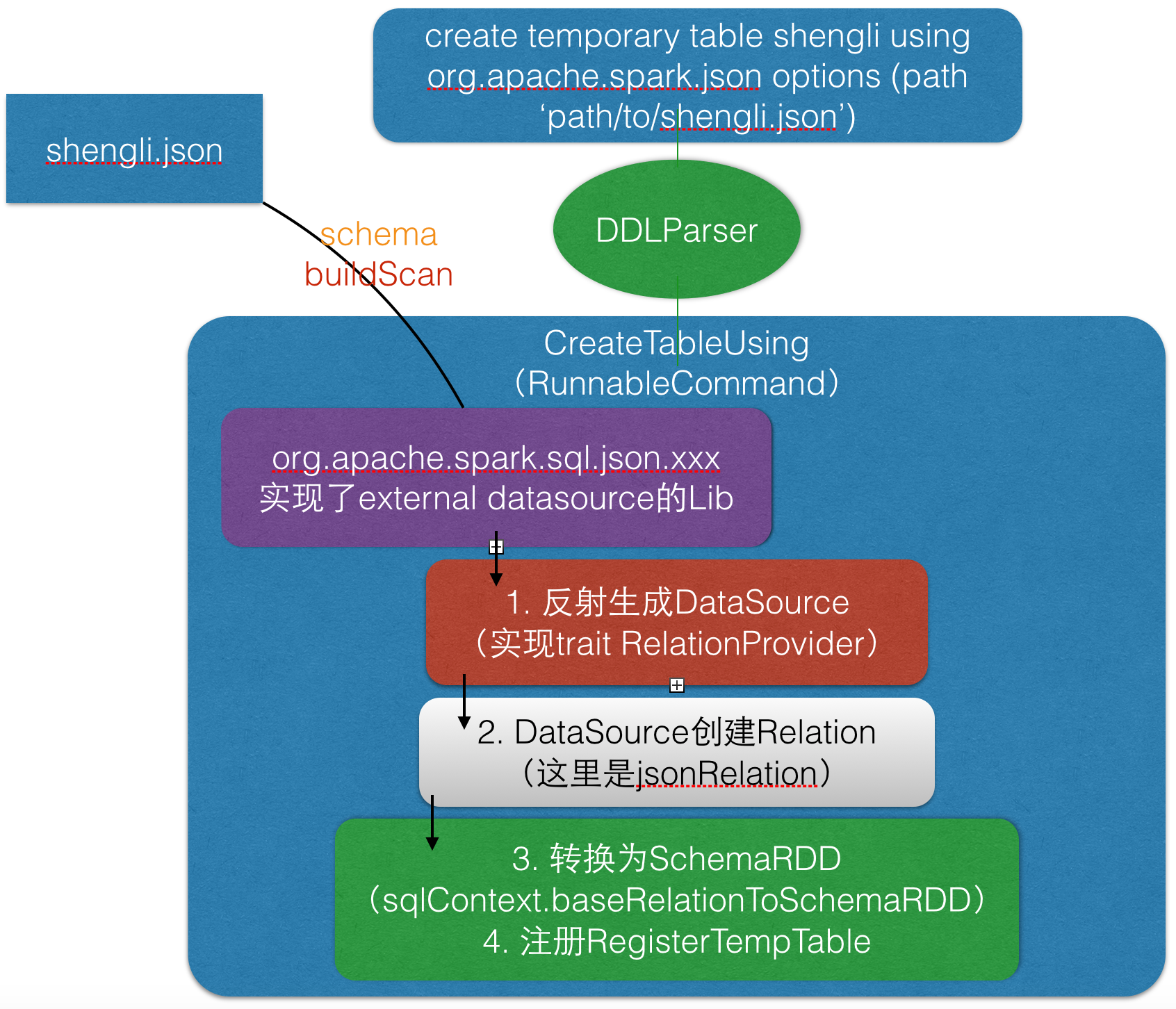
该类是一个RunnableCommand,其run方法会直接运行创建表语句。
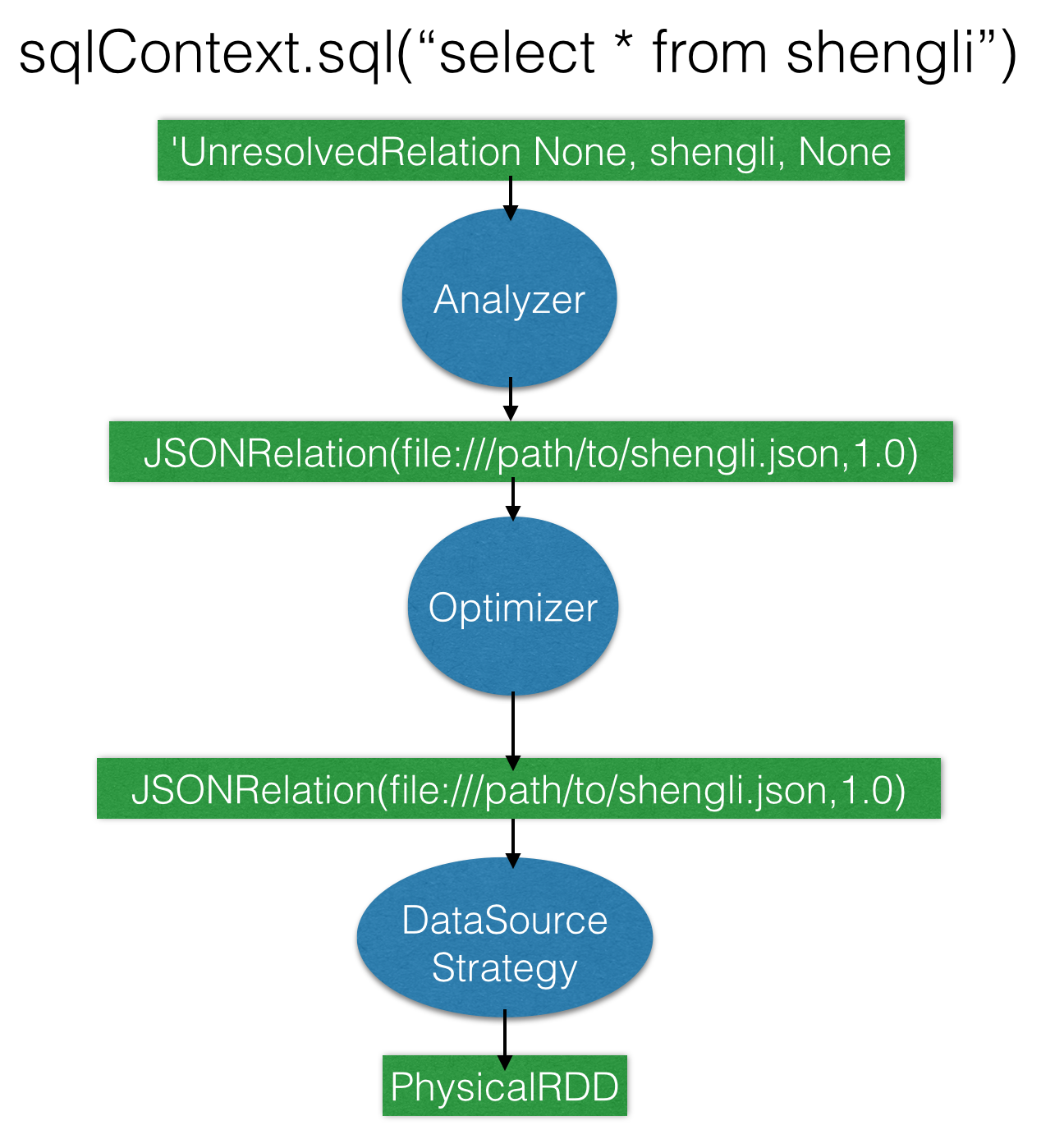
三、External DataSource解析流程
四、External Datasource Interfaces
那么久必须定义AvroRelation来继承BaseRelation。同一时候也要实现一个RelationProvider。

abstract class BaseRelation {
def sqlContext: SQLContext
def schema: StructTypeabstract class PrunedFilteredScan extends BaseRelation {
def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row]
}trait RelationProvider {
/**
* Returns a new base relation with the given parameters.
* Note: the parameters' keywords are case insensitive and this insensitivity is enforced
* by the Map that is passed to the function.
*/
def createRelation(sqlContext: SQLContext, parameters: Map[String, String]): BaseRelation
}五、External Datasource定义演示样例

private[sql] case class JSONRelation(fileName: String, samplingRatio: Double)(
@transient val sqlContext: SQLContext)
extends TableScan {
private def baseRDD = sqlContext.sparkContext.textFile(fileName) //读取json file
override val schema =
JsonRDD.inferSchema( // jsonRDD的inferSchema方法。能自己主动识别json的schema。和类型type。
baseRDD,
samplingRatio,
sqlContext.columnNameOfCorruptRecord)
override def buildScan() =
JsonRDD.jsonStringToRow(baseRDD, schema, sqlContext.columnNameOfCorruptRecord) //这里还是JsonRDD,调用jsonStringToRow查询返回Row
}private[sql] class DefaultSource extends RelationProvider {
/** Returns a new base relation with the given parameters. */
override def createRelation(
sqlContext: SQLContext,
parameters: Map[String, String]): BaseRelation = {
val fileName = parameters.getOrElse("path", sys.error("Option 'path' not specified"))
val samplingRatio = parameters.get("samplingRatio").map(_.toDouble).getOrElse(1.0)
JSONRelation(fileName, samplingRatio)(sqlContext)
}
}原创文章。转载请注明:
转载自:OopsOutOfMemory盛利的Blog。作者: OopsOutOfMemory
本文链接地址:http://blog.csdn.net/oopsoom/article/details/42064075
注:本文基于署名-非商业性使用-禁止演绎 2.5 中国大陆(CC BY-NC-ND 2.5 CN)协议,欢迎转载、转发和评论,可是请保留本文作者署名和文章链接。如若须要用于商业目的或者与授权方面的协商,请联系我。
![]()
















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









