







Hive基础SQL语法
1:DDL操作
DDL是数据定义语言,与关系数据库操作相似,
创建数据库
CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name
显示数据库
SHOW databases;
查看数据库详情
DESC DATABASE|SCHEMA database_name
切换数据库
USE database_name
修改数据库
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value,...)
删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|
CASCADE];
Hive在创建表时默认创建内部表,将数据移动到数据仓库指向的路径,而创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变,Hive删除表时,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据,创建表的语法如下
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
复制数据表
语法只会复制表的结构,不会复制表中的数据。另外,如果创建的表名已经存在,与创建数据仓库一样会抛出异常,用户可以使用“IF NOT EXISTS”选项来忽略这个异常。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path];
分区表是按照属性在文件夹层面给文件更好的管理,实际上就是对应一个HDFS文件系统上的独立文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。
创建Hive表
CREATE TABLE teacher_partition
(id string,
name string)
PARTITIONED BY (country string, state string);
set hive.exec.dynamic.partition=true; #开启动态分区,默认是false
set hive.exec.dynamic.partition.mode=nonstrict; #开启允许所有分区都是动态的,否则必须要有静态分区才能使用
set hive.exec.max.dynamic.partitions.pernode=1000; #动态分区最大数量
向分区表插入数据,准备文件data.txt,内容如下
1,tom,US,CA
2,jack,US,CB
3,mike,CA,BB
4,ariana ,CA,BC
创建中间表teacher,并将data.txt数据导入到teacher表中,利用dfs -ls /hive/warehouse/bigdata.db/teacher 命令查看teacher表在hadoop中的存储信息,可以看到建立的内部表teacher将data.txt移动到数据仓库指向的路径。
执行以下命令向分区表中插入数据。
INSERT INTO TABLE teacher_partition PARTITION (country, state) SELECT id,name,city,state FROM teacher;
创建桶表
表分区的基础上,按某一列的值将记录进行分桶存放,即分文件存放,即将大表分解成一系列小表,这样,涉及到Join操作时,可以在桶与桶间关联即可,大大减小Join的数据量,提高执行效率
1:开启分桶功能
hive> set hive.enforce.bucketing = true;
hive> set mapreduce.job.reduces=4;
2:创建桶表
create table teacher_bucket(
id string,
name string,
country string,
state string)
clustered by(id) into 4 buckets;
桶表不能通过load的方式直接加载数据,只能从另一张表中插入数据,执行如下命令insert into teacher_bucket select * from teacher,在创建桶表之前,要先通过“set hive.enforce.bucketing=true;”命令开启分桶的功能
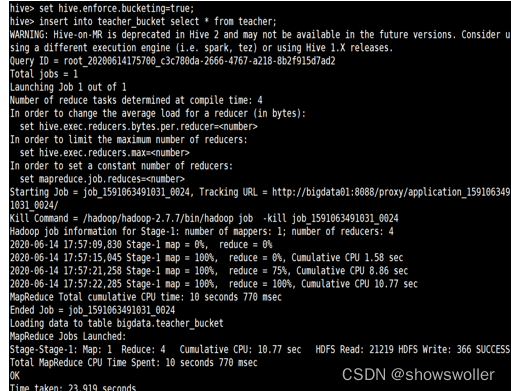
2:DML操作
DML即数据操作语言,是用来对Hive数据库中的数据进行操作的语言,数据操作主要是如何向表中装载数据和如何将表中的数据导出,主要操作命令有load insert等等基本与标准SQL相同
3:DQL操作
DQL即数据查询语言,实现数据的简单查询,主要操作命令有select where等,可以在查询时对数据进行排序,分组等操作
创作不易 觉得有帮助请点赞关注收藏~~~
















 3978
3978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











