







近年来,使用深度学习技术的图像超分辨率(SR)取得了显着进步。一般可以将现有的SR技术研究大致分为三大类:监督SR,无监督SR和特定领域SR(人脸)。
先说监督SR。
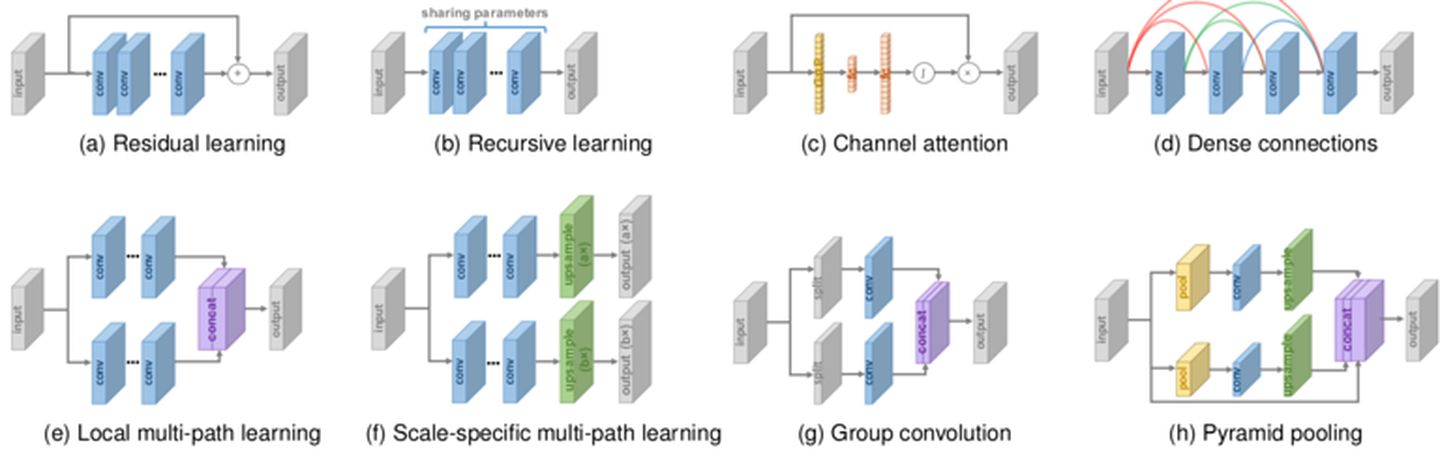
如今已经有各种深度学习的超分辨率模型。这些模型依赖于有监督的超分辨率,即用LR图像和相应的基础事实(GT)HR图像训练。 虽然这些模型之间的差异非常大,但它们本质上是一组组件的组合,例如模型框架,上采样方法,网络设计和学习策略等。从这个角度来看,研究人员将这些组件组合起来构建一个用于拟合特定任务的集成SR模型。
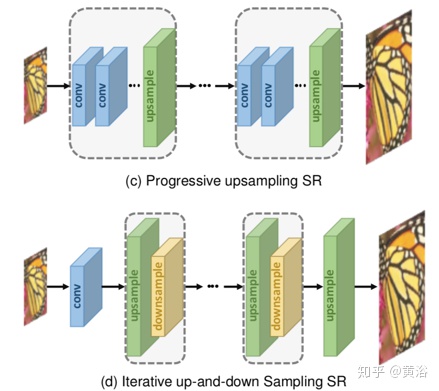
由于图像超分辨率是一个病态问题,如何进行上采样(即从低分辨率产生高分辨率)是关键问题。基于采用的上采样操作及其在模型中的位置,SR模型可归因于四种模型框架:预先采样SR,后上采样SR,渐进上采样SR和迭代上下采样SR,如图所示。

除了在模型中的位置之外,上采样操作如何实现它们也非常重要。为了克服插值法的缺点,并以端到端的方式学习上采样操作,转置卷积层(Transposed Convolution Layer)和亚像素层(Sub-pixel Layer)可以引入到超分辨率中。
转置卷积层,即反卷积层,基于尺寸类似于卷积层输出的特征图来预测可能的输入。具体地说,它通过插入零值并执行卷积来扩展图像,从而提高了图像分辨率。为了简洁起见,以3×3内核执行2次上采样为例,如图所示。首先,输入扩展到原始大小的两倍,其中新添加的像素值被设置为0(b)。然后应用大小为3×3、步长1和填充1的内核卷积(c)。这样输入特征图实现因子为2的上采样,而感受野最多为2×2。
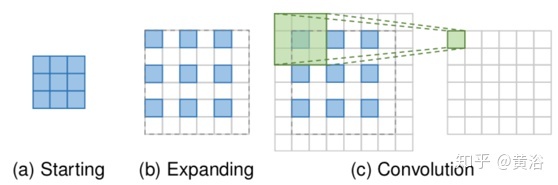
由于转置卷积层可以以端到端的方式放大图像大小,同时保持与vanilla卷积兼容的连接模式,因此它被广泛用作SR模型的上采样层。然而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









