






研一课程要求写一份小论文,顺便拿出来分享一下。比较粗浅,若存在错误还望见谅
1 介绍
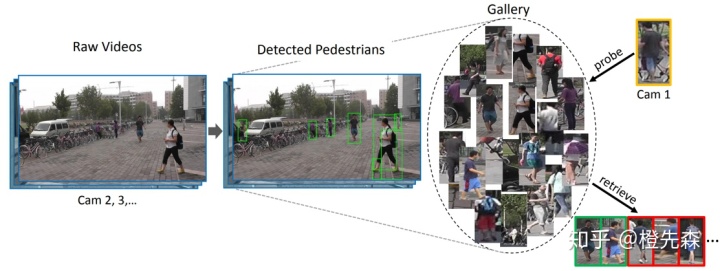
行人重识别(Person Re-identification)又被称为行人再识别,如今被视为图像检索的一类关键子问题。它是利用计算机视觉算法对跨设备的行人图像或视频进行匹配,即给定一个查询图像,在不同监控设备的图像库检索出同一个行人,如图1.1所示。由于对智能安防、视频监控等方面有巨大的应用前景,行人重识别已经成为计算机视觉领域的研究焦点。
然而,当前的行人重识别研究存在诸多难点[1]。① 行人图像的分辨率低。受限于监控设备的成像质量以及行人与设备之间的距离,很大一部分的行人图像非常模糊,无法通过人脸识别技术进行匹配,如图1.2(a)所示,因此需要提取人体的衣着、体型、步态等特征信息进行判断。② 监控环境变化。由于不同的行人视频或者图像拍摄地点和时间不同,行人的视角、光照、姿态等方面存在差异,同一行人的特征信息也会存在巨大的偏差,如图1.2(b)所示。③ 行人部位受到遮挡。在现实场景中,行人通常处在人流量大、背景复杂的环境下,很难避免行人部位受到遮挡的情况,如图1.2(c)所示。

2 行人重识别的发展现状
2.1 行人重识别研究方向分类
行人重识别的相关概念被提出至今已过去十余年时间,新方法、新思路不断涌现,如今已发展成计算机视觉领域的热门问题[1]。当前提出的行人重识别方法,可按4种分类方法进行分类,如下图2.1所示。按照识别的对象类型来区分,可以划分为基于图像的行人重识别和基于视频的行人重识别;按照方法类型来区分,大致可以划分为深度学习方法、度量学习方法[2-3];按是否有监督区分,可以划分为有监督方法和无监督方法;按应用场景来区分,大致可以划分为常规行人重识别、遮挡场景行人重识别、跨分辨率行人重识别、领域适应行人重识别、跨模态行人重识别、换衣行人重识别。

由于不同的划分方法之间存在范围的交叉,接下来仅对各个分类的各分支的代表性工作做总结介绍。(注:范围交叉的内容不再重复阐述,如基于图像的ReID会在深度学习ReID中有所介绍。)
2.2 基于度量学习的行人重识别
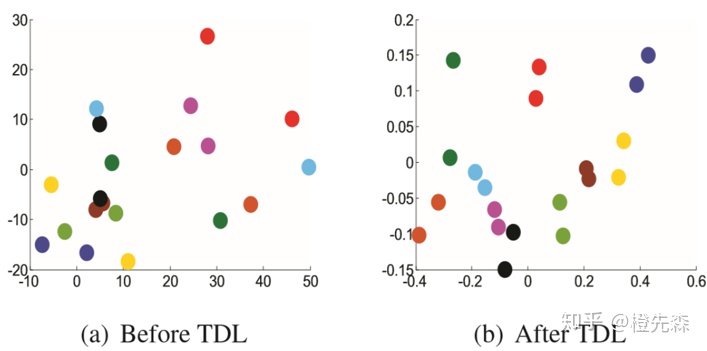
基于度量学习的方法目的在于将各类行人特征投影到同一个更有判别能力的度量空间,在这个度量空间内,相同的标签的行人图像距离更近,不同标签的行人图像距离更远。Top-push Distance Learning (TDL)[4]是一个经典的用度量学习解决行人重识别的方法,同时它也是一个基于视频的行人重识别方法,如图2.2所示。其核心思想是,让正样本对之间的距离小于负样本对距离的最小值,同时也要让正样本间的距离缩小。TDL中定义两个行人特征向量间的距离采用了马氏距离,即:
2.3 基于深度学习的行人重识别
深度学习是目前解决行人重识别问题的主流方法,其在大型数据集上的性能显著高于度量学习方法。随着近几年神经网络的快速发展,在常规的行人重识别领域也涌现出了一批经典的神经网络框架。其中比较经典的方法分为如下几类:局部特征提取框架、基于注意力的网络框架、基于语义分割或属性学习的框架和基于GAN的框架。
Part-based Convolutional Baseline (PCB) + Refined Part Pooling (RPP)[5]是一个利用图像局部特征的行人重识别方法,如图2.3.1所示。PCB核心思想在于将行人的特征映射划分成若干区域,提取局部的特征。然而直接的横向硬分割往往是不够准确的,为此设计了RPP模块,计算了各个像素的特征向量和局部平均的特征向量之间的相似度,调整了各个像素划分区域的归属,使得分割得到的特征更加具有判别力。

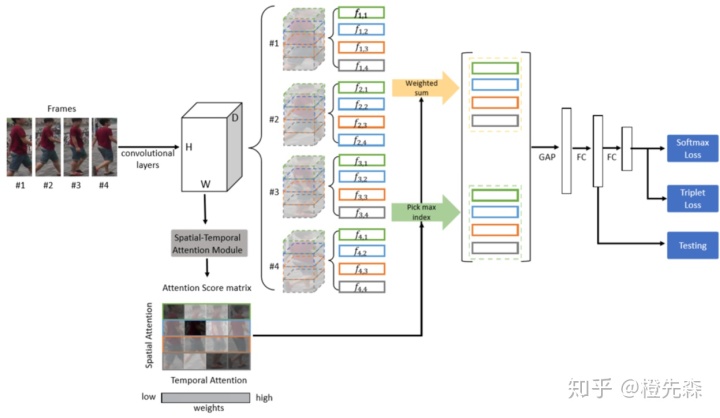
基于注意力的网络框架可以细分为三类:空间注意力、时间注意力(只针对基于视频的ReID)、通道注意力。Spatial-Temporal Attention (STA)[6]是一个将空间注意力和时间注意力结合的基于视频的行人重识别方法,如图2.3.2所示。先通过ResNet50提取特征映射,再将特征映射通过时空注意力模块生成空间-时间维度的注意力得分矩阵。为了降低视频内各帧的差异,采用了正则化项评估视频内相似度。采用空间权重最大化、时间权重平均化的策略获得行人视频的特征。
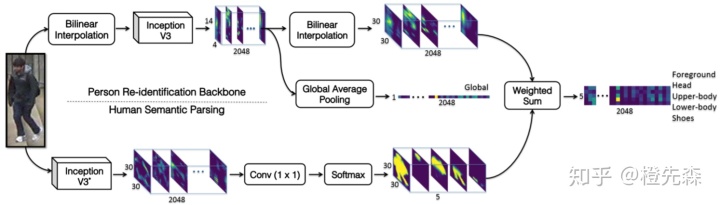
结合语义分割或者属性学习的方法通常需要额外的预训练模型,虽然加大了模型的复杂度,但有着显著的效果。Human Semantic Parsing for Person Re-identification (SPReID)[7]框架结合了语义分割模型,如图2.3.3所示。通过语义分割,得到行人5个部位(前景、头、上半身、下半身、鞋)的概率映射图,在与行人的特征映射相加权,得到各个局部的特征。
目前行人重识别数据集的数据量非常有限,通常只包含了几十到几百个行人的ID,训练样本的不足限制了模型训练的精度。在目前的一些方法中,图像翻转、图像裁剪、随机擦除等数据增强技巧被广泛使用。除此之外,Discriminative and Generative Learning for ReID (DG-Net)[8]对行人的姿态特征和衣着颜色特征进行了分解,利用了GAN网络生成一系列新样本,这些样本对不同的姿态特征和衣着颜色特征进行了组合,如下图2.3.4所示。该方法极大的丰富了训练样本,生成的图像更为真实,同时训练的模型对衣着变化也有一定鲁棒性。

2.4 无监督行人重识别
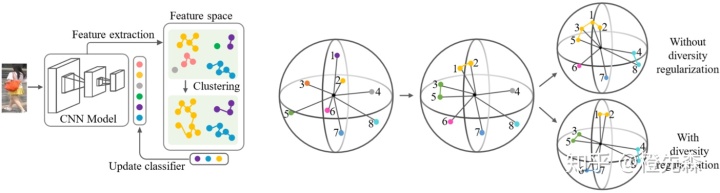
由于大量标记行人数据会带来过高的成本,因此在行人重识别领域,无监督方法受到越来越多的关注。Bottom-Up Clustering (BUC)[9]框架是无监督行人重识别的代表性成果,如下图2.4所示。BUC的框架是一个不断迭代的过程,一次的迭代包含如下步骤:首先对行人采用CNN训练;根据类间距离合并若干个类;然后对样本标签进行计算,得到各图像属于各聚类的概率值,即新标签;应用新标签再次训练CNN。每次前向传播时计算各聚类之间的余弦相似度,反向传播时更新查找表中聚类的质心。并且BUC提出了一个多样性正则项,用于避免出现聚类过多的情况。
2.5 遮挡场景行人重识别
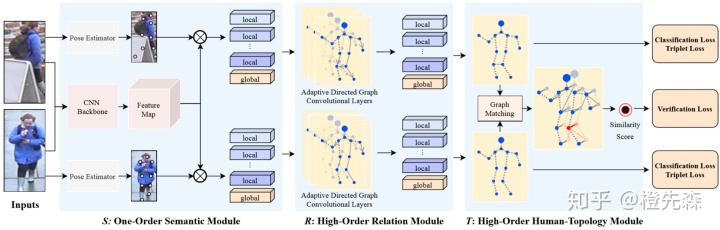
遮挡场景行人重识别是一项更加富有挑战性的任务,受到遮挡的影响,图像的判别信息减少,更难得到正确的匹配结果。High-Order Network (HONet)[10]框架很好的解决了遮挡下的行人特征提取,如图2.5所示。该框架包含了3个部分。第一部分为一阶语义模块,利用人体关键点估计模型获取关键点,再提取关键点的语义信息;第二部分为高阶关系模块,采用了一个图卷积模块学习关键点之间的关系特征,得到包含语义、关系信息的节点;第三部分为高阶拓扑模块,将两个关系图输入到一个跨图对齐层中,利用图匹配策略学习两者之间的对应关系,将对其信息嵌入到特征中。
2.6 跨分辨率行人重识别
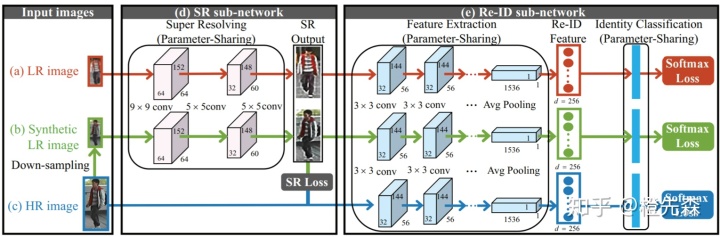
受到摄像头画面像素、行人距离远近等影响,拍摄到的行人分辨率参差不齐,高低分辨率图像的特征空间往往不一致,如何解决跨分辨率行人图像的匹配是当下需要解决的问题。Super-Resolution and Identity Joint Learning (SING)[11]框架首次将超分辨率网络与行人重识别网络进行结合,如图2.6所示。框架首先对HR(高分辨率)图像进行下采样,得到LR(低分辨率)图像,将LR和HR图像输入到超分辨率子网络中,采用MSE损失函数训练。再将恢复分辨率后的图像传入到行人重识别子网络中,采用Softmax损失训练。
2.7 领域适应行人重识别
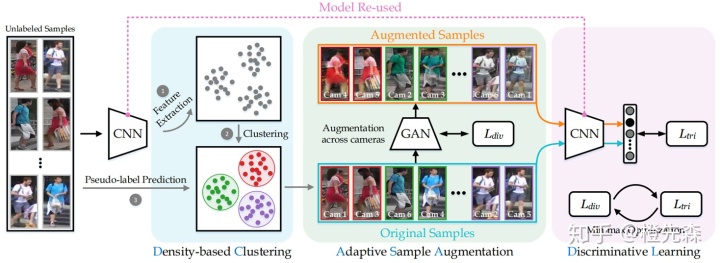
训练样本和测试样本的差异(相机风格、穿衣风格等差异)会影响到模型的实际效果,因此行人重识别中领域适应逐渐受到研究者的关注。Augmented Discriminative Clustering (AD-Cluster)[12]框架通过增加目标域样本的聚类点,同时扩张数据,来提高模型的域适应能力,如下图2.7所示。该方法先在无标签的目标域上先进行聚类,将所有数据的特征提取,然后再利用GAN生成新的样本数据,重新将所有数据(新+旧)输入CNN进行特征提取以及再次聚类,根据max-min(样本生成多样性最大化和类内距离最小化)迭代优化。
2.8 跨模态行人重识别
跨模态行人重识别目前主要分为两类:RGB-IR跨模态和Text-Image跨模态。在现实场景中,摄像头会因为故障或者在夜视场景下会呈现灰白色。灰度图像由8位存储,而彩色图像由24位存储。在节省存储空间的同时,也带来了信息丢失的问题,增加了行人重识别的难度。相比之下,文本与图像样本之间的跨度更大,在安防的一些场景中,用户只能获取到行人特征的文本描述,如穿着黑色上衣,头戴蓝色棒球帽等,而如何通过文本信息来匹配特定的行人,也是目前跨模态行人重识别需要研究的问题。
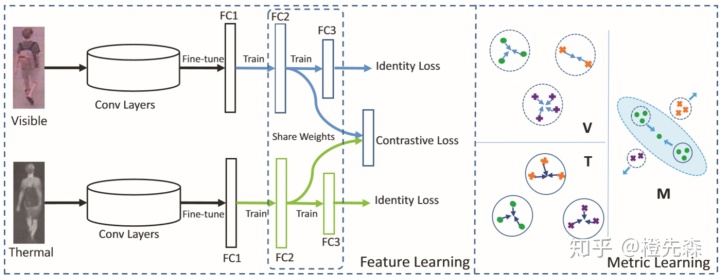
Visible Thermal (VT-REID)[13]框架是一个将深度学习和度量学习结合的方法,如图2.8.1所示。该框架先采用了双分支的CNN分别对两种模态的行人图像进行特征提取,在后续的全连接层上共享参数,学习得到跨模态共享特征,并使用一个约束损失让两种模态之间的特征距离更小。在度量学习上,使得同模态之间的特征距离更近,不同模态之间的特征距离更远。
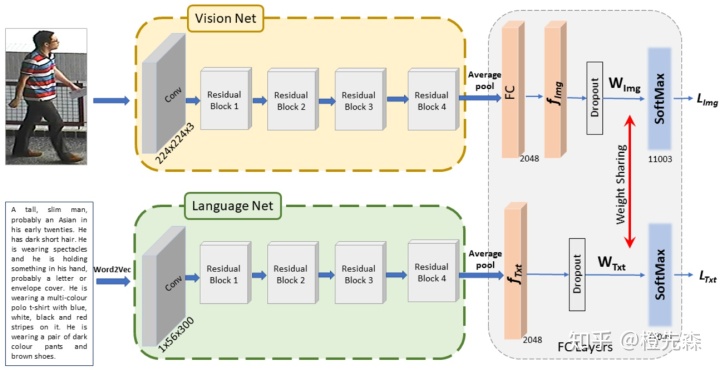
Vision-Language ReID Baseline (VL-Baseline)[14]提出了一个解决Text-Image跨模态行人重识别基准网络,如下图2.8.2所示。该网络采用了双分支结构:视觉特征提取采用了基本的ResNet50网络;文本特征提取采用了改进的ResNet50,在输入的第一层采用了特殊的单词投影网络,提取最多56个300维的词向量。对于提取的两类特征采用了参数共享的分类器,并用交叉熵损失训练,使得两种模态的特征能够匹配相同的行人。
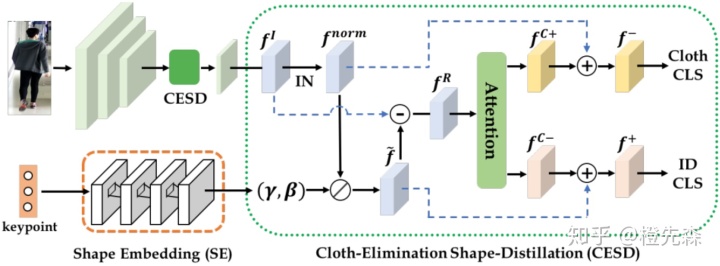
2.9 换衣行人重识别
换衣行人重识别是当前最新的子方向之一,主要面向长时间间隔情况下的行人识别。由于同一个人在一定时间间隔后的衣着会有显著变化,以往提出的网络框架主要针对颜色纹理等特征进行提取,在换衣后这些方法将不再适用。Long-Term Cloth-Changing (LTCC ReID)[15]认为换衣的情况下,需要关注行人的轮廓形状等生物特征,如下图2.9所示。该框架首先对行人的关键点进行提取,再将关键点的特征输入到关系网络中探索不同点之间的关系,所有关键点输入到GMP提取出关键点映射特征。对行人的图像提取整体的特征映射后,对其进行正则化,抑制原始的衣着信息。两种特征进行一系列计算后,将其输入到自注意力网络中,让网络自行提取出衣着特征和判别特征。
3 总结
目前传统的基于图像、视频的行人重识别算法已经在主流数据集上取得较高的准确率。近两年来,跨模态、跨分辨率、无监督等子方向蓬勃发展,受到了越来越多的关注。作为面向落地的计算机视觉任务,行人重识别依然面临众多挑战,例如大规模数据的有效训练、行人外貌变化下的鲁棒性、无限制场景(遮挡、光照等变化)下的应用等等,也为研究者留下了巨大的进步空间。
参考文献
[1] 宋婉茹, 赵晴晴, 陈昌红, 等. 行人重识别研究综述[J]. 智能系统学报, 2017, 12(6): 770-780.
[2] 罗浩, 姜伟, 范星, 等. 基于深度学习的行人重识别研究进展[J]. 自动化学报, 2019, 45(11): 2032-2049.
[3] Zheng L, Yang Y, Hauptmann A G. Person re-identification: Past, present and future[J]. arXiv preprint arXiv:1610.02984, 2016.
[4] You J, Wu A, Li X, et al. Top-push video-based person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1345-1353.
[5] Sun Y, Zheng L, Yang Y, et al. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline)[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 480-496.
[6] Fu Y, Wang X, Wei Y, et al. Sta: Spatial-temporal attention for large-scale video-based person re-identification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 8287-8294.
[7] Kalayeh M M, Basaran E, Gökmen M, et al. Human semantic parsing for person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1062-1071.
[8] Zheng Z, Yang X, Yu Z, et al. Joint discriminative and generative learning for person re-identification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2019: 2138-2147.
[9] Lin Y, Dong X, Zheng L, et al. A bottom-up clustering approach to unsupervised person re-identification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 8738-8745.
[10] Wang G, Yang S, Liu H, et al. High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6449-6458.
[11] Jiao J, Zheng W S, Wu A, et al. Deep low-resolution person re-identification[J]. 2018.
[12] Zhai Y, Lu S, Ye Q, et al. Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9021-9030.
[13] Ye M, Lan X, Li J, et al. Hierarchical discriminative learning for visible thermal person re-identification[C]//AAAI. 2018.
[14] Farooq A, Awais M, Yan F, et al. A Convolutional Baseline for Person Re-Identification Using Vision and Language Descriptions[J]. arXiv preprint arXiv:2003.00808, 2020.
[15] Qian X, Wang W, Zhang L, et al. Long-Term Cloth-Changing Person Re-identification[J]. arXiv preprint arXiv:2005.12633, 2020.














 5373
5373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









