






 本文介绍了如何利用SSD作为群晖NAS的缓存,提高读写速度和整体效率。通过读取数据时的缓存机制和写入时的数据处理,实现了兼顾性能和性价比的解决方案。在选择SSD时,考虑兼容性、传输效能和耐写度三个关键因素,并提及了端对端数据保护和断电保护等额外功能的重要性。在安装缓存后,避免频繁拔插以保障数据安全。
本文介绍了如何利用SSD作为群晖NAS的缓存,提高读写速度和整体效率。通过读取数据时的缓存机制和写入时的数据处理,实现了兼顾性能和性价比的解决方案。在选择SSD时,考虑兼容性、传输效能和耐写度三个关键因素,并提及了端对端数据保护和断电保护等额外功能的重要性。在安装缓存后,避免频繁拔插以保障数据安全。
好久没和大家做科普啦
今天晖姑娘掐指一算
决定和大家讲一讲
SSD 缓存的那些事
近年来,SSD 因为它的
高性能、低延迟、无噪音等优势
越来越被大众所青睐
但是对于主打存储的 NAS 来说
经济大空间往比极致速度更重要
毕竟以 T 为单位的 SSD
价格也和它的速度一样酸爽
(顶级极客/土豪就当我没说)

这时候,HDD+SSD 缓存
就成为了一个比较优秀的解决方案
既兼顾效率,又有较高的性价比
那么它是怎么运作的呢?
在读取硬盘数据时
NAS 会将所需数据同时缓存在 SSD中
当你再次用到这一部分数据时
就可以直接从 SSD 中获取
大幅优化传输速度
而在写入数据时
先将数据缓存入 SSD 中
再由 SSD 适时传输给 HDD
可以减少用户上传文件的等待时间
平衡 HDD 的工作负载
不过需要注意的是:
只读缓存(仅加速读取)1个 SSD 就能实现
而读写缓存(读写均加速)需要至少 2 个
因为读写缓存的故障会引起数据丢失
所以需要构建具有冗余功能的 RAID
来提升数据的安全性
说了这么多原理
可能大家感受还不太明显
下面晖姑娘就来讲讲
它在群晖 NAS 中的效果
欢迎大家对号入座

当你在办公室/工作室
大家都需要下载相同的素材/图包/表格时
当与多位家庭成员分享某一次出游的影集时
当你导入了大量文件、照片进行索引时
当爱折腾的你搭建了虚拟机、网站时
甚至你在与 DSM 中进行每一次交互时
SSD 缓存都会潜移默化地
提升这些步骤的效率
那么如何为你的群晖 NAS
选择合适的SSD作为缓存呢?
晖姑娘总结了“三步走”
一看兼容性,二看传输效能,三看耐写度
01
兼容性
这个真的很重要!!!技术小哥目睹了无数血与泪的教训
使用了不兼容的 SSD
轻则反向优化传输效能,系统卡顿
中则系统莫名报错、重启,小哥不知所措
重则空间损毁、数据丢失,小哥爱莫能助

不多说了,买 SSD 之前大伙儿先自己
点击文末阅读原文查看兼容列表吧
02
传输效能
作为 SSD,4K 的 IOPS 自然是越高越好但是在查看效能数据时
需要注意区分 FOB(出厂状态)和 Steady State(稳定状态)
这两个数据通常有着较大的差距
(具体可以看下图,感谢 koolshare 的大佬)
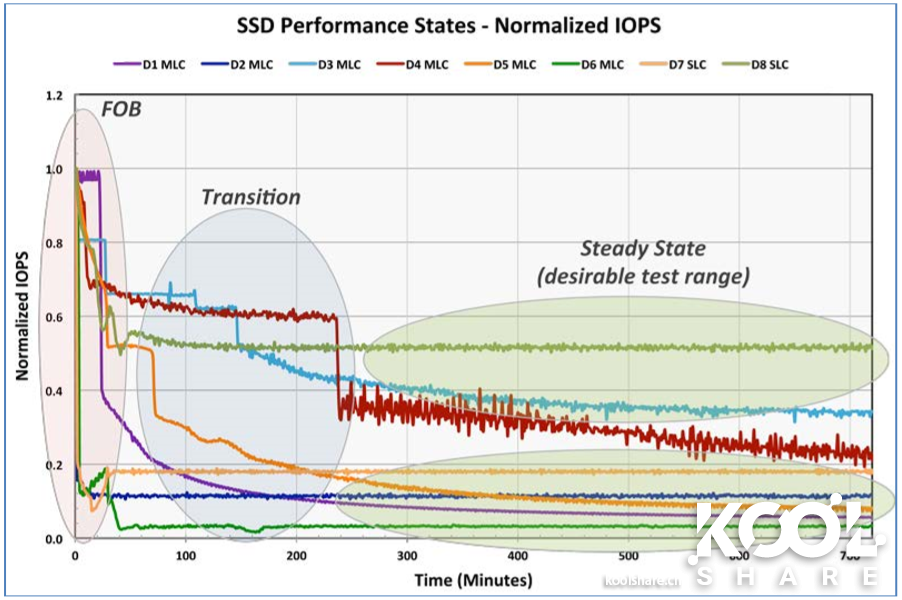
群晖 NAS 作为一个需要长时间运行的设备
稳定、安全肯定是第一要义
稳定状态的数据往往更具有参考意义
尽量选择稳定且高速的 SSD
03
耐写度
主要分为两个指标
TBW(太字节写入,在整个生命周期内写入 SSD 的累计数据量)
DWPD (每天驱动器写入,在保修期内每天可以写入整个 SSD 的次数)
这个两个数据可以相互换算
看起来也简单直观
越高代表 SSD 越耐用
可以伴随你的群晖 NAS 度过更漫长的岁月
如果上述指标都很优秀
那你基本能安心下单了
剩下还有一些加分项
晖姑娘也来说一说
端对端(end to end)数据保护
一些 SSD 会加入数据校验功能
以确保数据在传输过程中的完整性
有了这个功能,你的NAS在进行读写操作时
就能更加的稳定
断电保护
大多数企业级 SSD 都会
额外增加供电电容或小电池
以确保在突然断电时
主控依然有足够供电时间
将未完成的写入操作完成
从而降低数据丢失风险
最后的最后
晖姑娘再和安装了 SSD 缓存的同学们提醒一句
没事就不要拔下来了
如果一定要拔
记得在【存储空间管理员】中
先【卸载 SSD 缓存】哦~
↓ 买了NAS不会用,那么就来看教程 ↓ ↓ 在线咨询技术工程师 ↓
↓ 在线咨询技术工程师 ↓

















 3234
3234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









