






说到机器学习,不得不提及一下随机森林算法,随机森林是一种灵活且易于使用的机器学习算法,即便没有超参数调优,也可以在大多数情况下得到很好的结果。它也是最常用的算法之一,因为它很简易,既可用于分类也能用于回归任务。在此,IT培训网给大家谈谈随机森林算法的工作原理及重要性。
随机森林算法工作原理及重要性?
1、随机森林算法的工作原理
随机森林是一种有监督学习算法。 就像你所看到的它的名字一样,它创建了一个森林,并使它拥有某种方式随机性。 所构建的“森林”是决策树的集成,大部分时候都是用“bagging”方法训练的。 bagging方法,即bootstrap aggregating,采用的是随机有放回的选择训练数据然后构造分类器,最后组合学习到的模型来增加整体的效果。
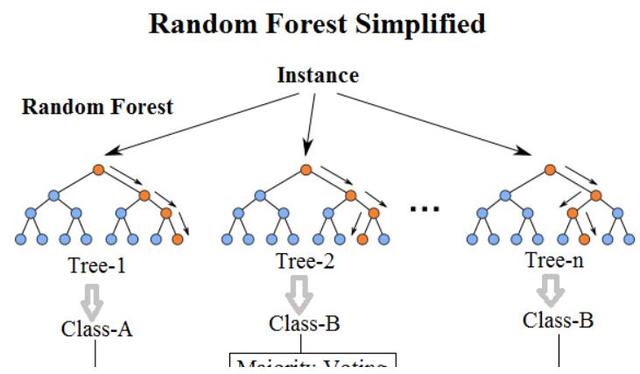
简而言之:随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测。随机森林的一大优势在于它既可用于分类,也可用于回归问题,这两类问题恰好构成了当前的大多数机器学习系统所需要面对的。 接下来,将探讨随机森林如何用于分类问题,因为分类有时被认为是机器学习的基石。 下图,你可以看到两棵树的随机森林是什么样子的:
除了少数例外,随机森林分类器使用所有的决策树分类器以及bagging 分类器的超参数来控制整体结构。 与其先构建bagging分类器,并将其传递给决策树分类器,您可以直接使用随机森林分类器类,这样对于决策树而言,更加方便和优化。要注意的是,回归问题同样有一个随机森林回归器与之相对应。
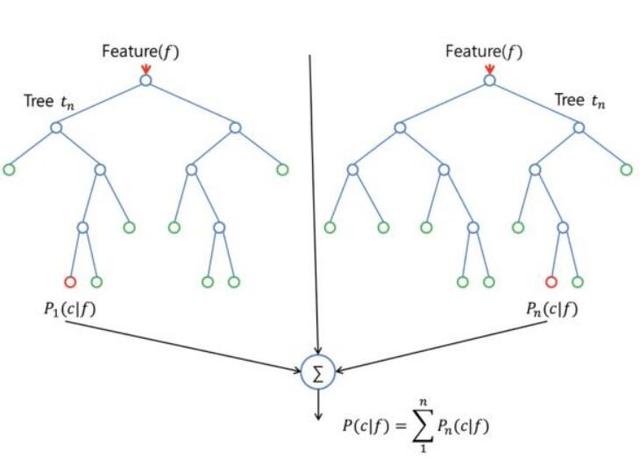
随机森林算法中树的增长会给模型带来额外的随机性。与决策树不同的是,每个节点被分割成最小化误差的最佳特征,在随机森林中我们选择随机选择的特征来构建最佳分割。因此,当您在随机森林中,仅考虑用于分割节点的随机子集,甚至可以通过在每个特征上使用随机阈值来使树更加随机,而不是如正常的决策树一样搜索最佳阈值。这个过程产生了广泛的多样性,通常可以得到更好的模型。
2、机器学习算法之随机森林算法的特征的重要性
随机森林算法的另一个优点是可以很容易地测量每个特征对预测的相对重要性。 Sklearn为此提供了一个很好的工具,它通过查看使用该特征减少了森林中所有树多少的不纯度,来衡量特征的重要性。它在训练后自动计算每个特征的得分,并对结果进行标准化,以使所有特征的重要性总和等于1。
如果你不了解决策树是如何工作对,也不知道什么是叶子或节点,可以参考百科的描述:在决策树中,每个内部节点代表对一类属性的“测试”(例如,抛硬币的结果是正面还是反面),每个分支代表测试的结果,每个叶节点代表一个类标签(在计算所有属性之后作出的决定)。叶子就是没有下一分支的节点。

通过查看特征的重要性,您可以知道哪些特征对预测过程没有足够贡献或没有贡献,从而决定是否丢弃它们。这是十分重要的,因为一般而言机器学习拥有的特征越多,模型就越有可能过拟合,反之亦然。















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









