







想要试试中文 OCR?这个项目可以考虑,轻量模型,不需要 GPU 也能跑得动。
机器之心报道,参与:肖清、思。

光学字符识别(OCR)现在已经有很广泛的应用了,很多开源项目都会嵌入已有的 OCR 项目来扩展能力,例如 12306 开源抢票软件,它就会调用其它开源 OCR 服务来识别验证码。很多流行的开源项目,其背后或多或少都会出现 OCR 的身影。
如果要说到中文 OCR,像身份证识别、火车票识别都是常规操作,它也可以实现更炫酷的功能,例如翻译笔在书本上滑动一行,自动获取完整的图像,并识别与翻译中文。
目前比较常用的中文 OCR 开源项目是 chineseocr,它基于 YOLO V3 与 CRNN 实现中文自然场景文字检测及识别,目前该项目已经有 2.5K 的 Star 量。而本文介绍的是另一个新 开源的中文 OCR 项目,它基于 chineseocr 做出改进,是一个超轻量级的中文字符识别项目。
项目地址:https://github.com/ouyanghuiyu/chineseocr_lite
该 chineseocr_lite 项目表示,相比 chineseocr,它采用了轻量级的主干网络 PSENet,轻量级的 CRNN 模型和行文本方向分类网络 AngleNet。尽管要实现多种能力,但 chineseocr_lite 总体模型只有 17M。
目前 chineseocr_lite 支持任意方向文字检测,在识别时会自动判断行文本方向。我们可以先看看项目作者给出的效果示例:


可以看到,chineseocr_lite 在横排文字和竖排文字的识别上都有不错的效果,而且它提供的交互式网页端能直接在页面插入图像与调用识别模型。为了进一步挖掘该轻量级模型的效果,机器之心也上手测试了一番。
项目实测
由于Docker能够提供一个不依赖主机操作系统的隔离空间,并且兼具良好的安全性与可移植性,我们决定在Docker下对该轻量级模型进行测试。至于测试过程中的环境配置与采坑过程,后文会一一道来。
先看看使用作者项目里自带图片的测试效果。识别结果与项目里提供的类似,这里耗时较长主要是由于我们测试时没有使用 GPU 的缘故。

下面我们找一些其它图片来测试一下它的效果。

可以看到该模型对于常规印刷字体的识别效果还是很好的。接下来我们决定找一个书法图片为难一下它,竟然一个也没有识别对?不过对于这样一个主打超轻量,总模型大小不超过 20M 的 OCR 项目来说,还要啥自行车。

Docker 环境搭建
我们的运行环境
- Ubuntu 18.04
- Python 3.6.9
- Pytorch 1.5.0.dev20200227+cpu(作者推荐 1.2.0)
首先下载 Docker 镜像。这里推荐使用咱们中国人自己做的镜像 deepo,一行代码傻瓜式安装 tensorflow、pytorch、darknet 等目前最新的深度学习框架。
deepo 链接:https://hub.docker.com/r/ufoym/deepo
当安装好 Docker 后,用以下代码获取包含所有深度学习框架的镜像:
docker pull ufoym/deepo在这里我们使用猪厂提供的国内源来加速下载:
docker pull hub-mirror.c.163.com/ufoym/deepo在高校的小伙伴推荐使用如下中科大的源,尽享丝般顺滑,10M/s 不是梦!
docker pull docker.mirrors.ustc.edu.cn/ufoym/deepo拉取完镜像后我们新建一个容器开始配置环境,使用如下命令新建容器并进入交互模式:
docker run -it -p 6666:8080 -v ~/Desktop/data/:/data --name ocr 18824ddf5d2d这里 docker run 表示创建容器,-it 表示创建容器后立刻进入交互模式,-p 表示进行端口映射,这里我们将主机 6666 的端口映射到容器的 8080 端口。
-v 表示共享数据,我们将主机桌面上名为 data 的文件夹与容器共享,并将其在容器上挂载为/data,--name 表示将新建的容器命名为 ocr,18824ddf5d2d 为刚才下载镜像的 ID,可使用 docker images 命令进行查看。
现在我们就进入到容器里了,输入 ls 就可看到我们与容器共享的文件夹/data 了。

cd 到/data 文件夹下拉取 chineseocr_lite 项目:
git clone https://github.com/ouyanghuiyu/chineseocr_lite作者很 nice 得提供了运行程序的依赖环境,cd 到 chineseocr_lite 下进行安装:
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt这里我们使用了清华的源进行加速。依赖环境装好了,python3 app.py 8080 走起!出现以下输出表示网页服务已成功启动。
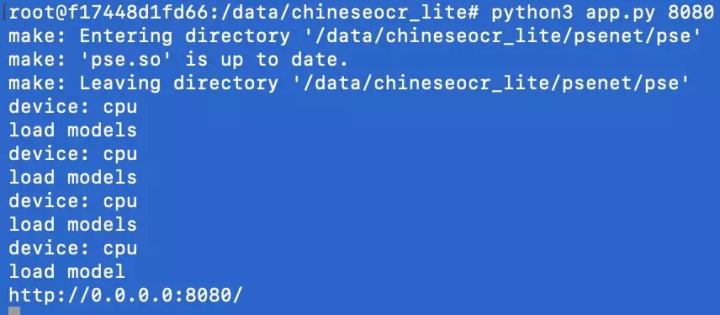
需要注意的是,我们在创建容器时将主机的 6666 端口映射到了容器的 8080 端口,所以在浏览器里我们应该输入 http://127.0.0.1:6666/ocr (http://127.0.0.1:8080/ocr),出现如下界面:
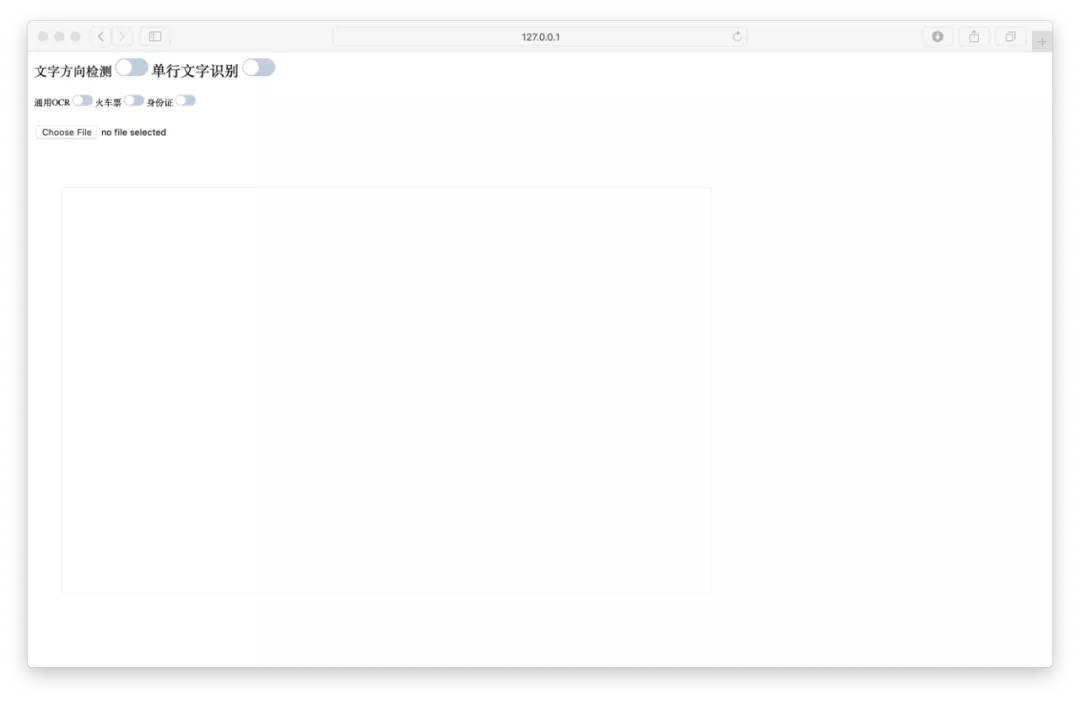
踩坑指南
机器之心也将测试这个项目过程中踩过的坑记录了下来,避免各位对这个项目感兴趣的小伙伴中同样的招。当在容器里安装好 requirement 就万事大吉了吗?不存在的,电脑表示不出错是不可能的,这辈子都不可能不报错。直接运行后出现如下错误:
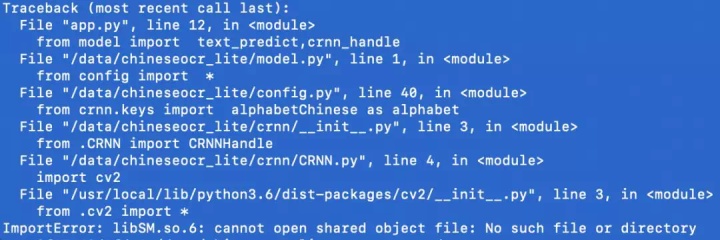
原因是缺少共享文件库,使用如下方法解决:
apt-get update
apt-get install apt-file
apt-file update
apt-file search libSM.so.6
apt-get install libsm6再运行出现这样的错误:
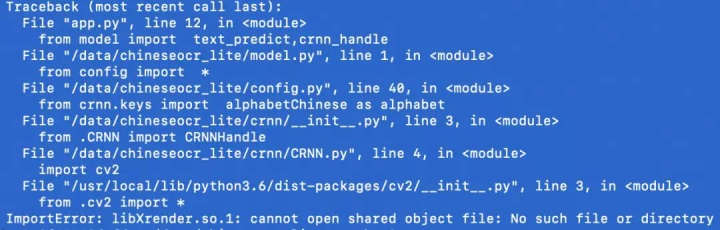
遂使用 apt-get install libxrender1 与 apt install python-qt4 安装之。进行这样一番操作之后,就可以顺利运行了。完结撒花~
Docker 配置参考教程:https://zhuanlan.zhihu.com/p/64493662















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









