







pandas 文件读取操作:
import pandas as pd
# 读取文件:
data = pandas.read_table('file.txt', sep = '/t', )
# read_table - 读取.txt文件
# read_csv - 读取.csv文件,sep = ','
# read_excel - 读取.xls文件pandas 文件读取操作:
# 写入文件
name = []
age = []
result = (pd.DataFrame([name, age],['name','age'])).T
result.to_csv('result.csv',index = False)pandas 切片操作:
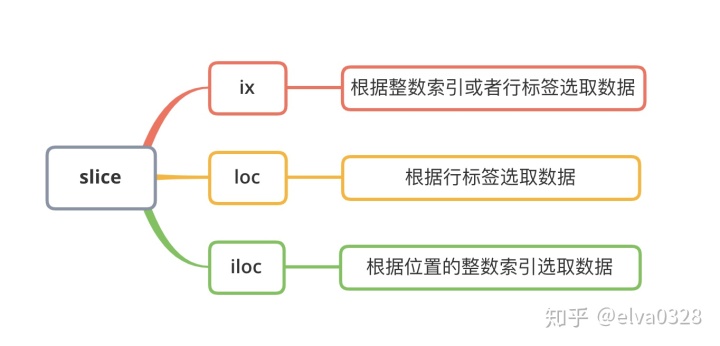
pandas主要提供了三种属性用来选取行/列数据:
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
... index=['cobra', 'viper', 'sidewinder'],
... columns=['max_speed', 'shield'])
>>> df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8
# ix切片:
# 按照行列的整数索引或者名称皆可读取。取sub_matrix建议使用.ix[[行索引],[列索引]]
>>> df.ix[0] #读取第一行,
df.ix['viper']
max_speed 1
shield 2
Name: cobra, dtype: int64
>>> df.ix[0,1] #读取第一行,第二列。
df.ix['cobra','shield']
2
>>> df.ix[[0,1],[1]] #读取1-2行,第二列。
df.ix[['cobra','viper'],['shield']]
shield
cobra 2
viper 5
>>> df.ix[0:2,1]
df.ix[['cobra','viper'],1]
cobra 2
viper 5
Name: shield, dtype: int64
# loc切片:
# 按照行列名称读取。取sub_matrix建议使用.loc[[行索引],[列索引]]
>>> df.loc[['viper', 'sidewinder']] #取index为'viper', 'sidewinder'的行
max_speed shield
viper 4 5
sidewinder 7 8
>>> df.loc['cobra', 'shield'] #取index为'viper', 列名为'sidewinder'的值
2
>>> df.loc[df['shield'] > 6] #取列名为'shield',且值大于6的样本(行)
max_speed shield
sidewinder 7 8
## setting values
>>> df.loc[['viper', 'sidewinder'], ['shield']] = 50 #定义行名,列名下的值为50
max_speed shield
cobra 1 2
viper 4 50
sidewinder 7 50
# iloc切片:
# 按照行列名称读取。取sub_matrix建议使用.iloc[[行索引],[列索引]]
>>> df.iloc[0:2,] #选取前两行,所有列
max_speed shield
cobra 1 2
viper 4 5













 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









