



 本文介绍了Python的pandas库在处理Excel数据方面的强大功能,包括数据导入、清洗、计算和导出。相比openpyxl库,pandas在速度上更具优势,尤其适合大量数据的处理和重复操作。此外,pandas还支持数据可视化,能生成各种图表。文章提到了安装pandas的命令,并预告了后续将讨论pandas的读取功能。
本文介绍了Python的pandas库在处理Excel数据方面的强大功能,包括数据导入、清洗、计算和导出。相比openpyxl库,pandas在速度上更具优势,尤其适合大量数据的处理和重复操作。此外,pandas还支持数据可视化,能生成各种图表。文章提到了安装pandas的命令,并预告了后续将讨论pandas的读取功能。

前面利用python的openpyxl库对excel做了简单基础操作,大家可以打开公众号右下角往期回顾,可以复习查看。今天开始介绍python可以操作Excel的另一个强大的库——pandas库。
个人认为,pandas库对于操作Excel有着极好的支撑。在数据导入、数据清洗、数据计算、数据导出都有着完整性的支撑,是一个提供高性能易用数据类型和分析工具,并且用一段时间你就会发现如果拿pandas只操作表格数据,是真的大材小用。 它不仅可以处理数据,更可以可视化数据。譬如可以做出这样的图表。并且是html形式的。当然还有特别多的类型,这个后面再说。
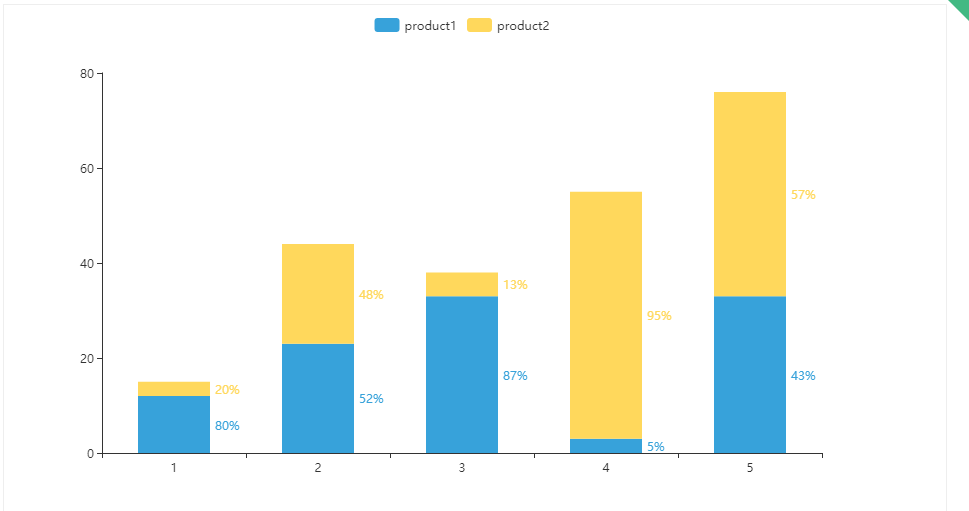
总而言之,pandas处理数据第一、数据量要够大够多,否则用Excel处理就行了。第二、每天重复的操作,例如打开同样的表格、删除同样的列、查找同样的数据。再适合不过了。
接下来再说说pandas与之前openpyxl库哪个好?
两个库其实都差不多,对数据以及图表都有很好的支持,但从写入数据与读取数据的速度来看,pandas更胜一筹。我也比较喜欢用pandas,至于图表这一块我们后面在可视化的专题在讨论。
0 1
安装
对于安装,请自行百度,不在赘述,简单而言两条命令:
安装:cmd——输入 pip install pandas
导入:import pandas as pd
0 2
读取
一、读取Excel文件,以下是几个常用的参数释义。pandas.read_excel(path, sheet_name = 0, header = 0, names = None index_col = None, usecols = None) import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx")print(data)
import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx",header = 0)print(data)
import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx",header = 0, sheet_name = 0)print(data)
import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx",header = 0, sheet_name = 0,usecols=[0,1])print(data)
import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx",header = 0, sheet_name = 0,usecols=["基站名称"])print(data)
import pandas as pddata = pd.read_excel(r"C:\Users\Administrator\Desktop\1.xlsx",header = 0, sheet_name = 0,usecols=[0,1,2],index_col = 0)print(data)
import pandas as pddata = pd.read_csv(r"C:\Users\Administrator\Desktop\1.csv",header = 0, usecols=[0,1,2],index_col = 0, encoding = "gbk")print(data)import pandas as pddata = pd.read_csv(r"C:\Users\Administrator\Desktop\1.csv",header = 0, usecols=[0,1,2],index_col = 0, encoding = "gbk",sep = ",")print(data)
end

















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









