







K-means聚类方法简单来说是将相似的物体分为一类。
K-means聚类方法属于无监督学习。在无监督学习中,物体没有标签(lable)。
那么如何评估物体的相似度?
可使用不同物体之间的距离来量化表示物体的相似度。距离越小,表明物体越接近,距离越小,表明物体越不相似。
最常用的距离是欧式距离,计算公式如下:
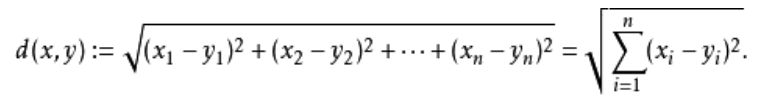
但是因为数据有不同的类型,数值型、类别型、排序型等。数值型数据可以直接使用欧式距离公式计算距离。类别型和排序型数据则需要使用一些方法处理后,才可以计算。
数值型变量可直接使用欧氏距离公式计算两点间的距离。计算前可先对数据进行归一化或离散化处理,避免不同变量量纲存在较大区别或其他的问题。
类别型变量可使用独热编码的方式进行处理。
排序性变量有两种方式处理。一是直接使用排序的数值,二是转为独热编码。
知道了如何评估物体间的相似度,下面就要学习K-means算法的核心了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4629
4629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









