






深度学习模型加速方向大致分为两种:
一、轻量化网络结构设计
- 分组卷积(group convolution,典型的如ShuffleNet和MobileNet等)
- 分解卷积(inception结构等)
- Bottleneck结构(通过1x1卷积进行降维和升维等操作)
- 神经网络结构搜索(Neural Architecture Search,简称NAS)
- 硬件适配
二、模型压缩相关技术
- 网络剪枝
- 知识蒸馏
- 参数量化
常用的模型压缩相关技术:
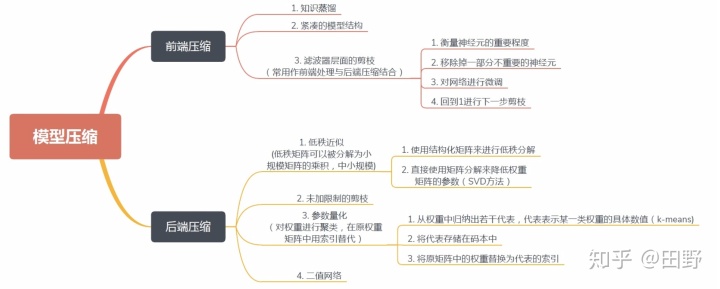
按照压缩过程对网络结构的破坏程度, 我们将模型压缩技术分为“前端压缩”与“后端缩”两部分。
所谓“前端压缩”,是指不改变原网络结构的压缩技术,主要包括知识蒸馏、紧凑的模型结构设计以及滤波器层面的剪枝等;而“后端压缩”则包括低秩近似、未加限制的剪枝、参数量化以及二值网络等,其目标在于尽可能地减少模型大小,因而会对原始网络结构造成极大程度的改造。
其中,由于“前端压缩”未改变原有的网络结构,仅仅只是在原模型的基础上减少了网络的层数或者滤波器的个数,其最终的模型可完美适配现有的深度学习库,如caffe等。相比之下,“后端压缩”为了追求极致的压缩比,不得不对原有的网络结构进行改造,如对参数进行量化表示等,而这样的改造往往是不可逆的。同时,为了获得理想的压缩效果,必须开发相配套的运行库,甚至是专门的硬件设备,其最终的结果往往是一种压缩技术对应于一套运行库,从而带来了巨大的维护成本。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









