







引言
自然语言处理NLP(nature language processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术以及应用。在对文本做数据分析时,我们一大半的时间都会花在文本预处理上,而中文和英文的预处理流程稍有不同,本文就对中、英文文本挖掘的常用的NLP的文本预处技术做一个总结。
文章内容主要按下图流程讲解:
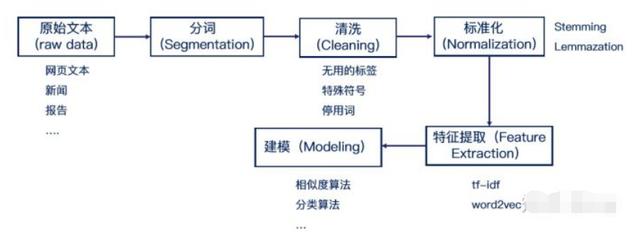
1.中英文文本预处理的特点
中英文的文本预处理大体流程如上图,但是还是有部分区别。首先,中文文本是没有像英文的单词空格那样隔开的,因此不能直接像英文一样可以直接用最简单的空格和标点符号完成分词。所以一般我们需要用分词算法来完成分词,具体操作后面会讲到。
当然,英文文本的预处理也有自己特殊的地方——拼写问题,很多时候,对英文预处理要包括拼写检查,比如“Helo World”这样的错误,我们不能在分析的时候再去纠错。还有就是词干提取(stemming)和词形还原(lemmatization),主要是因为英文中一个词会会不同的形式,这个步骤有点像孙悟空的火眼金睛,直接得到单词的原始形态。比如,"faster"、"fastest", 都变为"fast";“leafs”、“leaves”,都变为"leaf"。
2. 收集数据
文本数据的获取一般有两个方法:
别人已经做好的数据集,或则第三方语料库,比如wiki。这样可以省去很多麻烦。自己从网上爬取数据。但很多情况所研究的是面向某种特定的领域,这些开放语料库经常无法满足我们的需求。我们就需要用爬虫去爬取想要的信息了。可以使用如beautifulsoup、scrapy等框架编写出自己需要的爬虫。
3.文本预处理
3.1 去除数据中的非文本部分
由于爬下来的内容中有很多html的一些标签,需要去掉。还有少量的非文本内容的可以直接用Python 的正则表达式(re)删除, 另外还有一些特殊的非英文字符和标点符号,也可以用Python的正则表达式(re)删除。
import re
# 过滤不了\ 中文()还有————
r1 = u'[a-zA-Z0-9’!"#$%&'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\]^_`{|}~]+'#用户也可以在此进行自定义过滤字符
# 者中规则也过滤不完全
r2 = "[s+.!/_,$%^*(+"']+|[+——!,。?、~@#¥%……&*()]+"
# \可以过滤掉反向单杠和双杠,/可以过滤掉正向单杠和双杠,第一个中括号里放的是英文符号,第二个中括号里放的是中文符号,第二个中括号前不能少|,否则过滤不完全
r3 = "[.!//_,$&%^*()<>+"'?@#-|:~{}]+|[——!\\,。=?、:“”‘’《》【】¥…
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1946
1946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









