






一、Github项目地址
二、解题思路
2.1 基本需求分析
经过仔细阅读题目,分析得出项目的基本需求如下:
wc.exe -c //返回文件 file.c 的字符数
wc.exe -c //返回文件 file.c 的字符数
wc.exe -w //返回文件 file.c 的词的数目
wc.exe -l //返回文件 file.c 的行数
wc.exe -a //返回更复杂的数据(代码行 / 空行 / 注释行)
wc.exe -s //递归处理目录下符合条件的文件。
wc.exe -x //显示图形界面
2.2 实现思路
因为本项目需要制作图形化界面,以及需求用到比较多的字符串操作,综合考虑开发效率和程序运行效率,最终选择Java作为开发语言,使用Javafx进行图形界面开发。因为之前没有做过Javafx项目,所以需要去找一份Javafx的使用教程进行学习。整体上项目需要具备解析控制台输入的指令的功能,读取文件的功能,统计文本信息的功能,图形化界面的功能等。
三、设计方案
3.1 系统架构
使用基本的MVC结构:
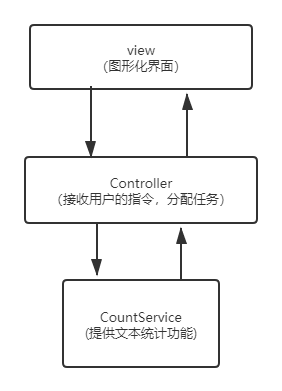
3.2 系统流程图
系统流程图如下:
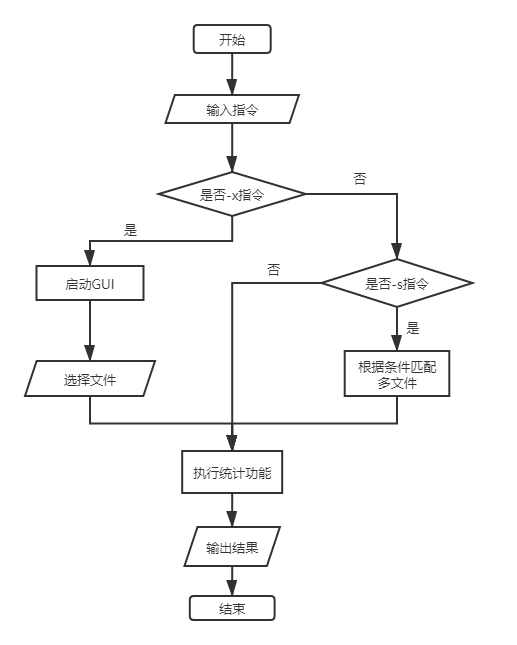
四、项目难点
4.1 如何准确地统计文件中的信息
使用逐行遍历的方式,统计每一行中的字符数,单词数等,最后汇总得到总行数,总的字符数,单词数等信息。
4.2 如何构建图形界面
使用scenebuilder构建基本的图形界面。
4.3 如何递归遍历查找文件夹中符合通配符的文件。
将用户输入的通配符转成正则表达式,递归获取当前目录下的所有文件,逐一进行文件名的匹配,得到符合条件的文件。
五、代码说明
/*** 核心统计方法
*
*@paramreader
*@return*@throwsIOException*/
private static CountResult count(BufferedReader reader) throwsIOException {
CountResult result= newCountResult();
String character= "\\w";
String word= "[a-zA-Z]+";
String line;//多行注释
boolean isAnnotation = false;while ((line = reader.readLine()) != null) {//统计一行中的字符数
result.character +=CountUtil.count(line, character);//统计一行中的单词数
result.word +=CountUtil.count(line, word);//统计行数
result.line++;//统计空行,代码行,注释行
if(line.trim().isEmpty()) {//空行
result.emptyLine++;//开始多行注释
} else if(isAnnotation) {
result.annotationLine++;//多行注释结束
if (line.trim().endsWith("*/")) {
isAnnotation= false;
}
}else if (line.trim().contains("//") || line.trim().contains("*")) {//注释行
result.annotationLine++;//如果是行后注释
if (!(line.trim().startsWith("/") || line.trim().startsWith("*"))) {
result.codeLine++;
}//多行注释开始
if (line.trim().startsWith("/*")) {
isAnnotation= true;
}
}else{//代码行
result.codeLine++;
}
}returnresult;
}/*** 根据命令行模式下的参数执行
*
*@paramargs*/
public static voidwc(String[] args) {long begin =System.currentTimeMillis();try{//多文件处理
if (Constant.OPS_S.equals(args[0])) {if (args.length == 3) {
List files = FileUtil.listFileByRegex(RegexUtil.toRegex(args[2]));for(File f : files) {
countFile(args[1], f);
}
}else{throw new Exception("缺少必要的参数,指令示例:-s -a *.c");
}
}else{//单文件处理
countFile(args[0], new File(args[1]));
}
System.out.println("运行耗时:" + (System.currentTimeMillis() - begin) + "ms");
}catch(Exception e) {
System.out.println("运行出错:" +e.getMessage());
}
}/*** 统计输出一个文件的信息
*
*@paramops 要统计的信息
*@paramfile 文件名
*@throwsException*/
public static void countFile(String ops, File file) throwsException {
System.out.println("文件信息:" +BeanUtil.getFileInfo(file));switch(ops) {caseConstant.OPS_C:
System.out.println("字符数:" +countService.countCharacter(file));break;caseConstant.OPS_W:
System.out.println("单词数:" +countService.countWord(file));break;caseConstant.OPS_L:
System.out.println("行数:" +countService.countLine(file));break;caseConstant.OPS_A:
CountResult result=countService.countAll(file);
System.out.println("字符数:" +result.character);
System.out.println("单词数:" +result.word);
System.out.println("行数:" +result.line);
System.out.println("空行数:" +result.emptyLine);
System.out.println("代码行数:" +result.codeLine);
System.out.println("注释行数:" +result.annotationLine);break;default:throw new Exception("无法识别的指令类型:" +ops);
}
}
六、测试结果
6.1 单文件测试
测试文件:
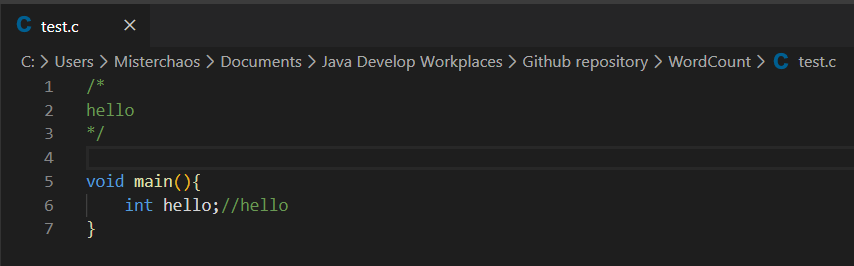
测试结果

6.2 多文件测试
测试文件:

测试结果:
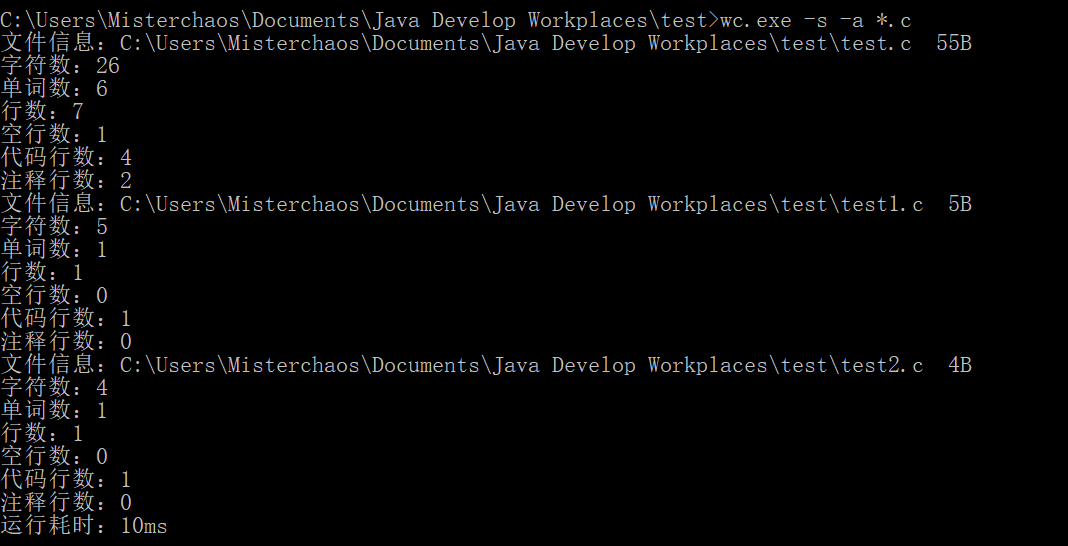
6.3 图形化界面测试
选择文件:
统计结果:

6.4 出错处理测试
文件不存在:

缺少参数:

不识别的指令:

没有找到符合条件的文件:

七、PSP表格
PSP2.1Personal Software Process Stages预估耗时(分钟)实际耗时(分钟)
Planning
计划
5
5
· Estimate
· 估计这个任务需要多少时间
5
5
Development
开发
180
265
· Analysis
· 需求分析 (包括学习新技术)
30
60
· Design Spec
· 生成设计文档
5
10
· Design Review
· 设计复审 (和同事审核设计文档)
5
5
· Coding Standard
· 代码规范 (为目前的开发制定合适的规范)
5
5
· Design
· 具体设计
5
5
· Coding
· 具体编码
120
150
· Code Review
· 代码复审
5
10
· Test
· 测试(自我测试,修改代码,提交修改)
5
20
Reporting
报告
15
25
· Test Report
· 测试报告
5
10
· Size Measurement
· 计算工作量
5
10
· Postmortem & Process Improvement Plan
· 事后总结, 并提出过程改进计划
5
5
合计
200
295
八、项目小结
这次的项目带给我最大的不同是使用了PSP表格去管理自己的时间,从实际的结果来看,实际的耗时比自己的计划都会稍微多一些,主要是有一些问题不在预期之内,而且在编写代码的过程中也不断有新的想法产生,就会产生更多的需求。耗时比较多的地方是图形化界面的表格,一开始只是做一个显示单文件信息的界面,后来觉得想做多文件的,就又去学了javafx表格的使用,Javafx做表格确实有点麻烦,花了一些时间去学习它的使用,总体来说收获还是挺多的。















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









