








CDA数据分析师 出品
相信大家在做一些算法经常会被庞大的数据量所造成的超多计算量需要的时间而折磨的痛苦不已,接下来我们围绕四个方法来帮助大家加快一下Python的计算时间,减少大家在算法上的等待时间。今天给大家讲述最后一方面的内容,关于Dask的方法运用。
1.简介
随着对机器学习算法并行化的需求不断增加,由于数据大小甚至模型大小呈指数级增长,如果我们拥有一个工具,可以帮助我们并行化处理Pandas的DataFrame,可以并行化处理Numpy的计算,甚至并行化我们的机器学习算法(可能是来自sklearn和Tensorflow的算法)也没有太多的麻烦,那它对我们会非常有帮助。
好消息是确实存在这样的库,其名称为Dask。Dask是一个并行计算库,它不仅有助于并行化现有的机器学习工具(Pandas和Numpy)(即使用高级集合),而且还有助于并行化低级任务/功能,并且可以通过制作任务图来处理这些功能之间的复杂交互。[ 即使用低级调度程序 ]这类似于Python的线程或多处理模块。
他们也有一个单独的机器学习库dask-ml,这与如现有的库集成如sklearn,xgboost和tensorflow。
Dask通过绘制任务之间的交互图来并行化分配给它的任务。使用Dask的.visualize()方法来可视化你的工作将非常有帮助,该方法可用于所有数据类型以及你计算的复杂任务链。此方法将输出你的任务图,并且如果你的任务在每个级别具有多个节点(即,你的任务链结构在多个层次上具有许多独立的任务,例如数据块上的并行任务),然后Dask将能够并行化它们。
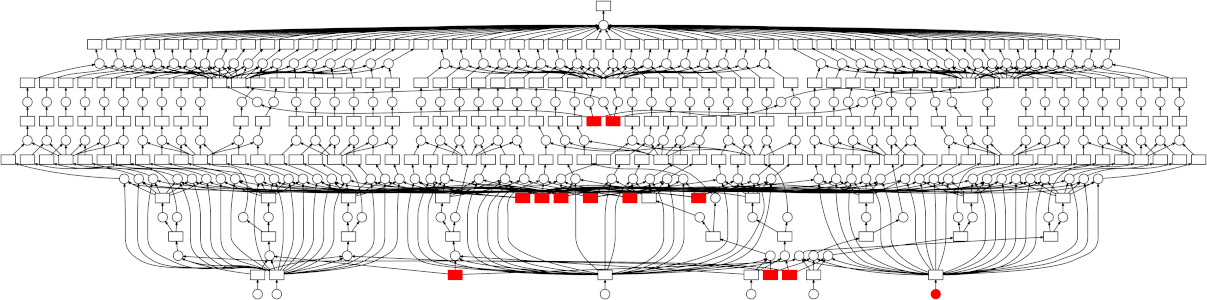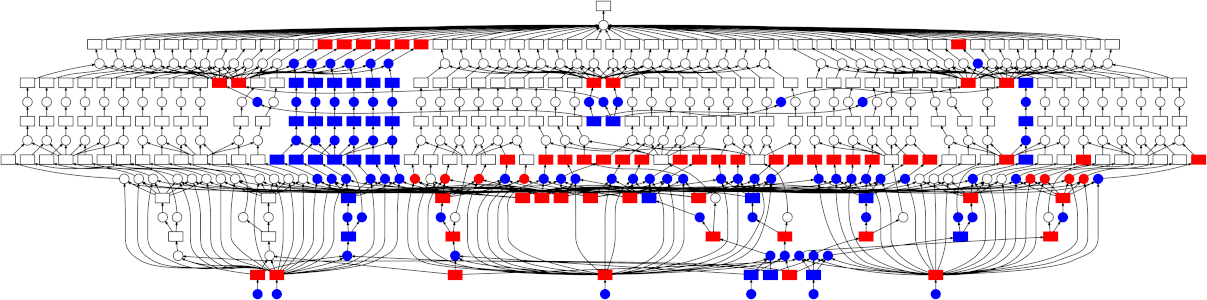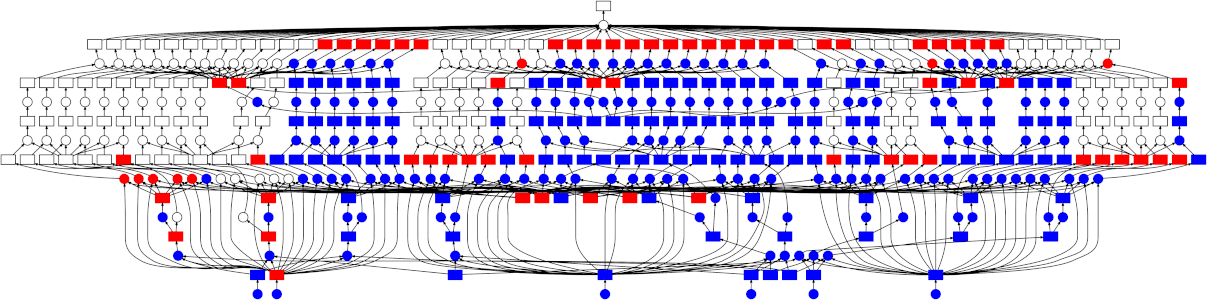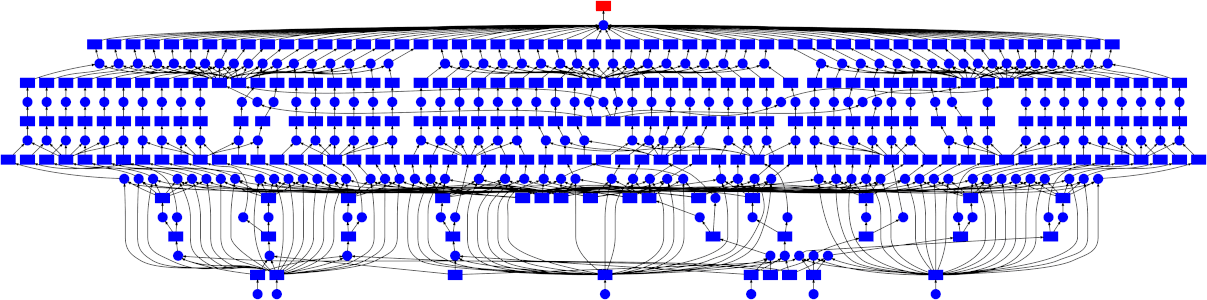
注意: Dask仍是一个相对较新的项目。它还有很长的路要走。不过,如果你不想学习全新的API(例如PySpark),Dask是你的最佳选择,将来肯定会越来越好。Spark / PySpark仍然遥遥领先,并且仍将继续改进。这是一个完善的Apache项目。
2.数据类型
Dask中的每种数据类型都提供现有数据类型的分布式版本,例如pandas中的DataFrame、numpy中的ndarray和Python中的list。这些数据类型可以大于你的内存,Dask将以Blocked方式对数据并行(y)运行计算。Blocked从某种意义上说,它们是通过执行许多小的计算(即,以块为单位)来执行大型计算的,而块的数量为chunks的总数。
a)数组:

网格中的许多Numpy数组作为Dask数组
Dask Array对非常大的数组进行操作,将它们划分为块并并行执行这些块。它有许多可用的numpy方法,你可以使用这些方法来加快速度。但是其中一些没有实现。
只要支持numpy切片,Dask Array就可以从任何类似数组结构中读取数据,并且可以通过使用并且通过使用Dask . Array .from_array方法具有.shape属性。它还可以读取.npy和.zarr文件。
import dask.array as daimport numpy as nparr = numpy.random.randint(1, 1000, (10000, 10000))darr = da.f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6931
6931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









