






MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
原文地址:MobileNetV1
1、摘要
MobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depth wise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。
论文介绍了两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。论文验证了模型在其他领域(对象检测,人脸识别,大规模地理定位等)使用的有效性。
2、引言
深度卷积神经网络将多个计算机视觉任务性能提升到了一个新高度,总体的趋势是为了达到更高的准确性构建了更深更复杂的网络,但是这些网络在尺度和速度上不一定满足移动设备要求。MobileNet描述了一个高效的网络架构,允许通过两个超参数直接构建非常小、低延迟、易满足嵌入式设备要求的模型。

3、相关工作
现阶段,在建立小型高效的神经网络工作中,通常可分为两类工作:
- 压缩预训练模型。获得小型网络的一个办法是减小、分解或压缩预训练网络,例如量化压缩(product quantization)、哈希(hashing )、剪枝(pruning)、矢量编码( vector quantization)和霍夫曼编码(Huffman coding)等;此外还有各种分解因子(various factorizations )用来加速预训练网络;还有一种训练小型网络的方法叫蒸馏(distillation ),使用大型网络指导小型网络,这是对论文的方法做了一个补充,后续有介绍补充。
- 直接训练小型模型。 例如Flattened networks利用完全的因式分解的卷积网络构建模型,显示出完全分解网络的潜力;Factorized Networks引入了类似的分解卷积以及拓扑连接的使用;Xception network显示了如何扩展深度可分离卷积到Inception V3 networks;Squeezenet 使用一个bottleneck用于构建小型网络。
本文提出的MobileNet网络架构,允许模型开发人员专门选择与其资源限制(延迟、大小)匹配的小型模型,MobileNets主要注重于优化延迟同时考虑小型网络,从深度可分离卷积的角度重新构建模型。
4、模型结构
4.1、深度可分离卷积(Depthwise Separable Convolution)
MobileNet是基于深度可分离卷积的。通俗的来说,深度可分离卷积干的活是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。这么做的好处是可以大幅度降低参数量和计算量。分解过程示意图如下:
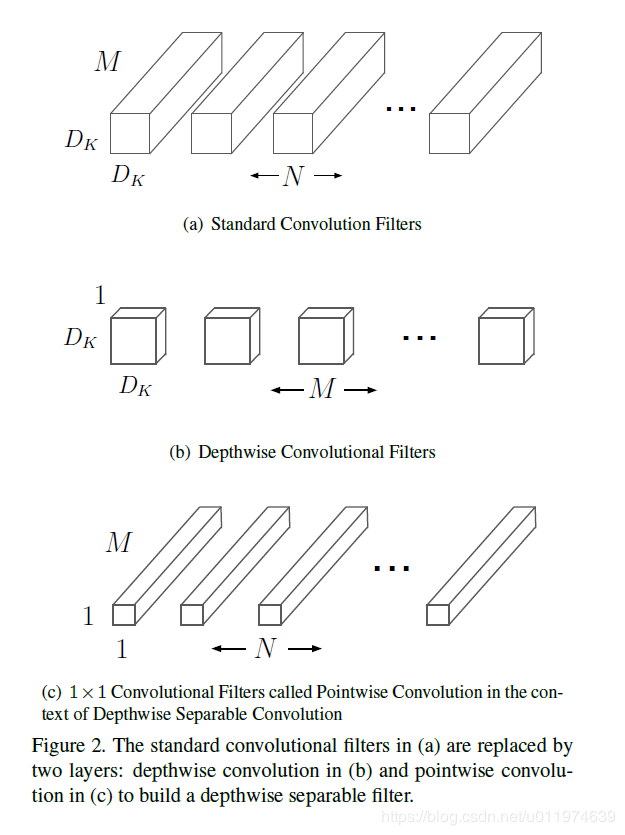
具体计算过程如下:
输入的特征映射F尺寸为( DF, DF , M),采用的标准卷积K为(DK, DK, M, N)(如图(a)所示),输出的特征映射为G尺寸为(DG, DG, N)。
标准卷积的卷积计算公式为:
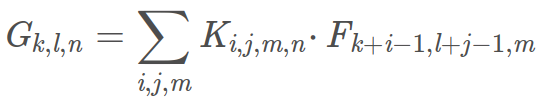
卷积输入的通道数为M,输出的通道数为N。对应的计算量为:DK * DK *M * N * DF * DF。可将标准卷积(DK, DK, M, N)拆分为深度和逐点卷积:
- 深度卷积负责滤波作用,尺寸为(DK, DK, 1, M)如图(b)所示。输出特征为(DG, DG, M);
- 逐点卷积负责转换通道,尺寸为(1, 1, M, N)如图(c)所示。得到最终输出为(DG, DG ,N)。
深度卷积的卷积公式为:
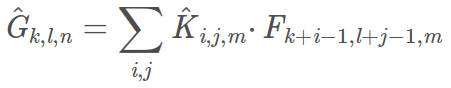
其中K^是深度卷积,卷积核为(DK, DK, 1, M),其中m个卷积核应用在F中第m个通道上,产生G^上第m个通道输出。
深度卷积和逐点卷积计算量:DK * DK * M * DF * DF + M * N * DF * DF。
计算量减少了:
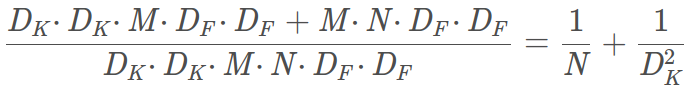
4.2、网络结构及训练
标准卷积和MobileNet中使用的深度分离卷积结构对比如下,一个结构分解为两个的串联:

注意:如果是需要下采样,则在第一个深度卷积上取步长为2.
MobileNet的具体结构如下(dw表示深度分离卷积):

除了最后的FC层没有非线性激活函数,其他层都有BN和ReLU非线性函数。
我们的模型几乎将所有的密集运算放到1×1卷积上,这可以使用general matrix multiply (GEMM) functions优化。在MobileNet中有95%的时间花费在1×1卷积上,这部分也占了75%的参数:

剩余的其他参数几乎都在FC层上了。
在TensorFlow中使用RMSprop对MobileNet做训练,使用类似InceptionV3 的异步梯度下降。与训练大型模型不同的是,我们较少使用正则和数据增强技术,因为小模型不易陷入过拟合;没有使用side heads or label smoothing,我们发现:在深度卷积核上放入很少的L2正则或不设置权重衰减的很重要,因为这部分参数很少。
4.3、宽度因子α: (控制特征维度的通道数)
我们引入的第一个控制模型大小的超参数是:宽度因子α(Width multiplier ),用于控制输入和输出的通道数,即输入通道从M变为αM,输出通道从N变为αN。

4.4、分辨率因子ρ: (控制输入图像的分辨率)
我们引入的第二个控制模型大小的超参数是:分辨率因子ρ(resolution multiplier ).用于控制输入和内部层表示。即用分辨率因子控制输入的分辨率。

下面的示例展现了宽度因子和分辨率因子对模型的影响:

第一行是使用标准卷积的参数量和Mult-Adds;第二行将标准卷积改为深度分类卷积,参数量降低到约为原本的1/10,Mult-Adds降低约为原本的1/9。使用α和ρ参数可以再将参数降低一半,Mult-Adds再成倍下降。
5、实验
实验部分主要研究以下部分: 深度卷积的影响;宽度因子的影响;两个超参数的权衡;与其他模型对比。
5.1、模型选择
使用深度分类卷积的MobileNet与使用标准卷积的MobileNet之间对比:

在精度上损失了1%,但是的计算量和参数量上降低了一个数量级。
原MobileNet的配置如下:

为了进一步缩小模型,可将MobileNet中的5层14×14×512的深度可分离卷积去除。
实验结果对比:

可以看到在类似的参数量和计算量下,精度衰减了3%。(中间的深度卷积用于过滤作用,参数量少,冗余度相比于大量的逐点卷积应该是少很多的~)
5.2、超参数验证
5.2.1、单参数验证
表6显示宽度因子对模型参数量、计算量精度的影响,表7显示分辨率因子对模型参数量、计算量精度的影响:

使用过程要权衡参数对模型性能和大小的影响。
5.2.2、交叉验证计算量对精度影响
图4显示了16个交叉的模型在ImageNet上的表现,宽度因子取值为α∈{1,0.75,0.5,0.25},分辨率取值为{224,192,160,128}。

当模型越来越小时,精度可近似看成对数跳跃形式的。
5.2.3、交叉验证参数量对精度影响
图5显示了16个交叉的模型在ImageNet上的表现,宽度因子取值为α∈{1,0.75,0.5,0.25},分辨率取值为{224,192,160,128}。

5.3、与其他先进模型相比
表8将完整的MobileNet与原始的GoogleNet和VGG16对比,MobileNet与VGG16有相似的精度,参数量和计算量减少了2个数量级。

表9是MobileNet的宽度因子α=0.5和分辨率设置为160×160的缩小模型与其他模型对比结果,相比于老大哥AlexNet在计算量和参数量上都降低一个数量级,对比同为小型网络的Squeezenet,计算量少了2个数量级,在参数量类似的情况下,精度高了3%。
5.4、其他应用场景性能
5.4.1、Fine Grained Recognition
在Stanford Dogs dataset的表现如下:
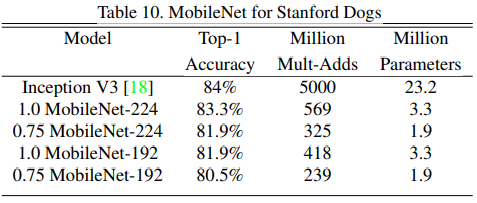
MobileNet在计算量和参数量降低一个数量级的同时几乎保持相同的精度。
5.4.2、Large Scale Geolocalizaton
PlaNet是做大规模地理分类任务,我们使用MobileNet的框架重新设计了PlaNet,对比如下:
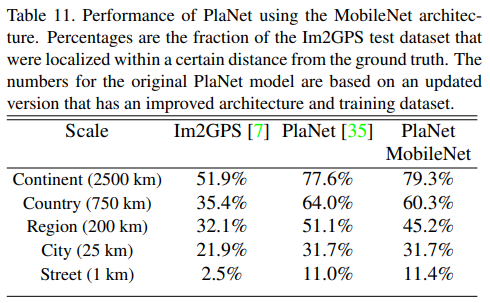
基于Inception V3架构的PlaNet有5200万参数和574亿的mult-adds,而基于MobileNet的PlaNet只有1300万参数(300个是主体参数,1000万是最后分类层参数)和58万的mult-adds,相比之下,只是性能稍微受损,但还是比原Im2GPS效果好多了。
5.4.3、Face Attributes
MobileNet的框架技术可用于压缩大型模型,在Face Attributes任务中,我们验证了MobileNet的蒸馏(distillation )技术的关系,蒸馏的核心是让小模型去模拟大模型,而不是直接逼近Ground Label:
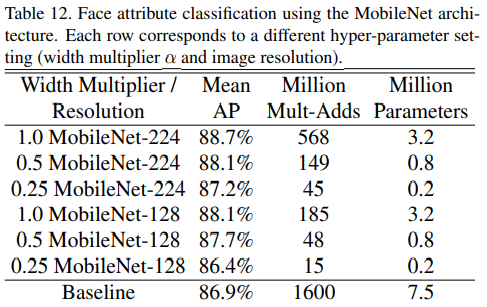
将蒸馏技术的可扩展性和MobileNet技术的精简性结合到一起,最终系统不仅不需要正则技术(例如权重衰减和退火等),而且表现出更强的性能。
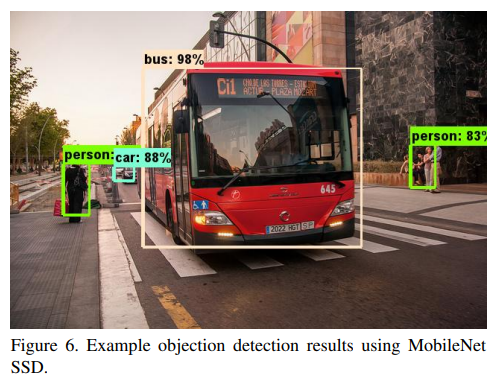
5.4.4、Object Detection
基于MobileNet改进的检测模型对比如下:
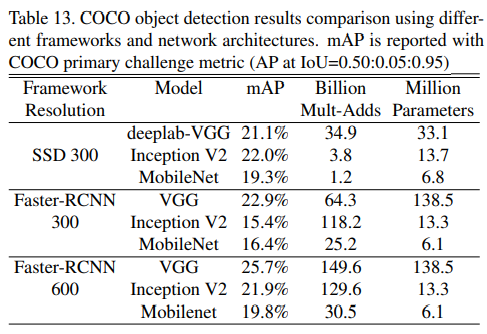
可视化结果:
5.4.5、Face Embeddings
FaceNet是现阶段最先进的人脸识别模型,基于MobileNet和蒸馏技术训练出结果如下:

6、结论
论文提出了一种基于深度可分离卷积的新模型MobileNet,同时提出了两个超参数用于快速调节模型适配到特定环境。实验部分将MobileNet与许多先进模型做对比,展现出MobileNet的在尺寸、计算量、速度上的优越性。
上一篇:Xception论文翻译,下一篇:MobileNetV2论文翻译,传送门:分类网络目录索引。














 3610
3610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









