







转自三篇文章做笔记
文章1:https://zhuanlan.zhihu.com/p/33075914
几天前,著名的小网 MobileNet 迎来了它的升级版:MobileNet V2。之前用过 MobileNet V1 的准确率不错,更重要的是速度很快,在 Jetson TX2 上都能达到 38 FPS 的帧率,因此对于 V2 的潜在提升更是十分期待。
V2 主要引入了两个改动:Linear Bottleneck 和 Inverted Residual Blocks。下面让我们通过对比 V2 与 V1 和 ResNet 结构,来认识这两个改动背后的动机和细节。欢迎大家指正。
更新:2018年4月2日,Google发布了MobileNet V2的官方实现,原论文在Arxiv上也做出了相应更新,详见官方博客。
1. 对比 MobileNet V1 与 V2 的微结构
相同点
- 都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。由下式可知,因为卷积核的尺寸
通常远小于输出通道数
,因此标准卷积的计算复杂度近似为 DW + PW 组合卷积的
倍。
不同点:Linear Bottleneck
- V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数
,这样不管输入通道数
是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 (
) 进行着辛勤工作的。
- V2 去掉了第二个 PW 的激活函数。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。
2. 对比 ResNet 与 MobileNet V2 的微结构
相同点
- MobileNet V2 借鉴 ResNet,都采用了
的模式。
- MobileNet V2 借鉴 ResNet,同样使用 Shortcut 将输出与输入相加(未在上式画出)
不同点:Inverted Residual Block
- ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征。
- ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。直观的形象上来看,ResNet 的微结构是沙漏形,而 MobileNet V2 则是纺锤形,刚好相反。因此论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
3. 对比 MobileNet V1 和 V2 的宏结构
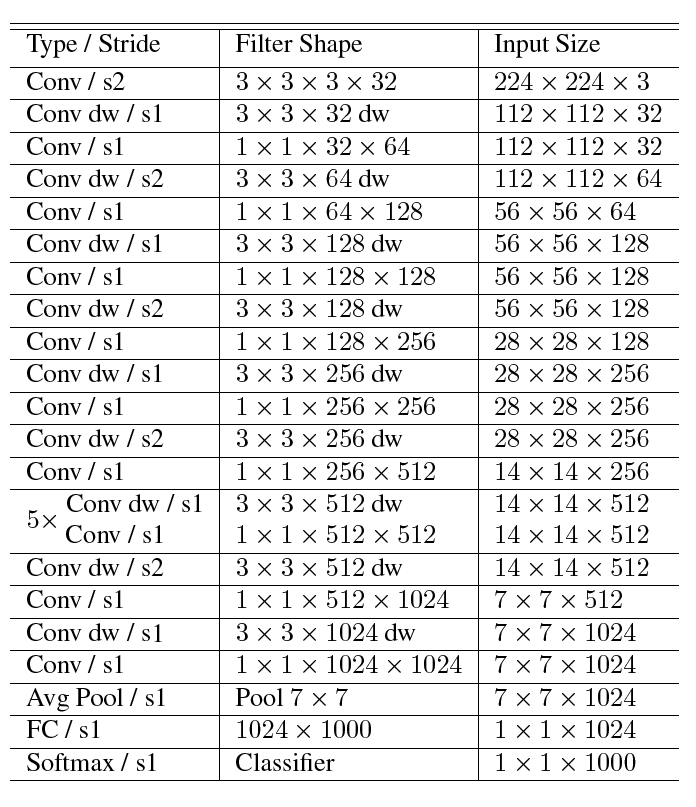
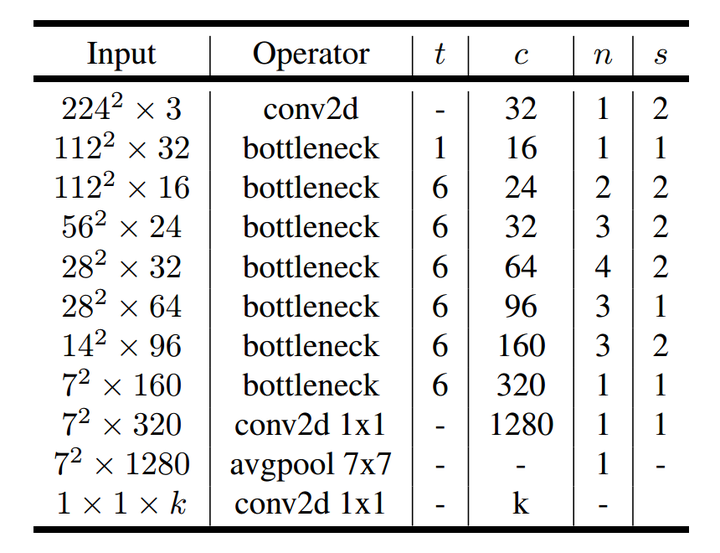

4. 在复现时遇到的问题
- 表述前后不一致。论文里面文字描述说有19个 Bottleneck Residual Block,但是之后给出的网络结构表(论文中的Table 2)里却只列出了17个。Table 2 第五行的 stride 和第六行的输入尺寸也是矛盾的。最后一行的输入通道数应该是1280而不是k。最后似乎也没有用 Softmax,不知道是否有意为之等等。
- 关于性能优化不知道具体实现。论文里面提到可以将 Bottleneck Residual Block 内的运算拆成 Expansion Ratio 个分别运算,以减小运行时的内存占用,但是没细说具体怎么实现。
- 目前我基于 Keras/TensorFlow 按照论文给的结构尝试实现了 V2 的网络,简单测了下预测速度,不知道为什么比 V1 还要慢... 用 GTX 1050 上跑一个 Forward Pass,V1 平均只用时 11ms,而 V2 却要用 14ms。这和论文里面用 CPU 测试的性能是不符的,按理说CPU都能快50%,GPU应该也有类似的提升效果吧?不知道是我的网络问题还是论文里面使用了特殊的性能优化实现 + TensorFlow Lite 的优化加成导致的。按理说 TensorFlow 已经实现了高效的 DepthwiseConv2D,不应该存在由于 V2 比 V1 的层数多了不少且DW也多了一些而导致速度下降的可能吧?
- 我一直以为只要A网络比B网络的时间复杂度和空间复杂度都低,那么A网络的预测速度就一定比B网络快,但是现在的初步测试结果让我很困惑,也许是我的网络写的有问题吧... 只能期待作者能够尽快公布代码和预训练模型了。
下图是我按照论文给出结构搭的 MobileNet V2 网络结构示意图(点击看高清大图)
注:由于还不确定是否正确,就先不放出代码了,避免误导大家...

附录
题图是在Muir Woods看到的两只斑比,一只叫 MobileNet V1,另一只叫 V2。哈哈。
文章2: https://blog.csdn.net/sun_28/article/details/80561964
MobileNet V2
Linear Bottlenecks and Inverted Residuals
下图是可分离卷积:

请注意到由于 MobileNet 使用 Batch Normalization ,而 Batch Normalization 的 beta 项含有均值,因此整个 MobileNet 并没有使用 BiasAdd 操作。其次,我们要注意到 MobileNetV1 无论是 Depthwise Conv 还是 Pointwise Conv ,它们后面会加入一个 ReLu6 操作,作者在 MobileNetV2 花了很大篇幅来讨论这个操作的影响。
下面两张图是 MobileNet V1 的模块结构:


下图是 MobileNet V2 的主要模块结构(Linear Bottlenecks and Inverted Residuals):


不难发现 MobileNet V2 的主要结构,只是在 MobileNet V1 的基础上引入了,残差连接和瓶颈结构,以及把 Pointwise 的激活改成了 Linear 。
MobileNet V2 网络结构
下图是 MobileNet V2 的网络架构:

下图是 MobileNet V1 的网络架构:

对比 MobileNet 的 V1 和 V2 两版网络架构,我们发现两版都没有 Pooling 层,而是直接把 stride 设成 2 ,直接卷积缩放。而且最近有些观点表示,Pooling 层产生的的特征丢失不可逆转,所以 MobileNet 一直就没有 Pooling 层。另外,大致一眼过去,貌似 V2 宽度比 V1 小很多。然而,我们挑出其中一层,比如 56×5656×56 来算一下,会发现 V2 中间该模块中间有两层 feature map 的维度达到 192 ,而 V1 仅有128。这么看来,V2 的特征信息传输更高效,对数据带宽利用率更好。再就是,尽管 v2 比 v1 更深,但是 v2 的 parameters 未必就比 v1 多。因为 MobileNet 的参数重量,主要不在 depthwise 上,而是在 poinwise ,所以瓶颈压缩部分减少了不少 pointwise 的参数。
Memory Efficient Trick
这个内存高效利用技巧,我用下面的草稿解释。

需要注意,源码这部分的实现逻辑可能是有问题的,貌似与原文精神不一致。
def split_conv(input_tensor,
num_outputs,
num_ways,
scope,
divisible_by=8,
**kwargs):
"""Creates a split convolution.
Split convolution splits the input and output into
'num_blocks' blocks of approximately the same size each,
and only connects $i$-th input to $i$ output.
Args:
input_tensor: input tensor
num_outputs: number of output filters
num_ways: num blocks to split by.
scope: scope for all the operators.
divisible_by: make sure that every part is divisiable by this.
**kwargs: will be passed directly into conv2d operator
Returns:
tensor
"""
b = input_tensor.get_shape().as_list()[3]
if num_ways == 1 or min(b // num_ways,
num_outputs // num_ways) < divisible_by:
# Don't do any splitting if we end up with less than 8 filters
# on either side.
return slim.conv2d(input_tensor, num_outputs, [1, 1], scope=scope, **kwargs)
outs = []
input_splits = _split_divisible(b, num_ways, divisible_by=divisible_by) # 这句貌似不应该拆分输入
output_splits = _split_divisible(
num_outputs, num_ways, divisible_by=divisible_by)
inputs = tf.split(input_tensor, input_splits, axis=3, name='split_' + scope)
base = scope
for i, (input_tensor, out_size) in enumerate(zip(inputs, output_splits)):
scope = base + '_part_%d' % (i,)
n = slim.conv2d(input_tensor, out_size, [1, 1], scope=scope, **kwargs)
n = tf.identity(n, scope + '_output')
outs.append(n)
return tf.concat(outs, 3, name=scope + '_concat')上面源码这段,我认为是有问题的,输入输出一般不可能是同时进行 split 的,甚至大多数情况都不会去尝试拆输入。
下面附录一张我的原始推导笔记:

关于 ReLu6 的讨论
我认为 MobileNet V2 的关键论点,可能并不是 Linear Bottleneck 和 Inverted Residuals 本身的形式,它们只是一个研究结果而已。而作者主要的论点应该是,以 ReLu6 为例的非线性激活映射,对特征信息空间的有害影响。在部分的讨论中,作者有一个观点,我认为比较有趣。这个观点是:
In ReLu(Bx)ReLu(Bx) is the linear classifier to ensure which are the non-zero volume part of output space
这也就是说,每个卷积层都能看作 Feature Map 分类器,而 ReLu 决定了一些特征的去留。大于零的算做重要特征被留下,小于等于零作为冗余特征被舍弃。同时,我们很清楚世上并不存在完美分类器,从不误判的分类器。因此这些分类器只要出现误判,那么特征信息就会出现损失,而且作为符合条件概率的链式响应,这个信息损失应该相当严重,精度应该很低,那为何现在 CNN 在某些领域,依然表现出色呢?这是因为 B 会把 x 的信息,散落到比 x 更高的维度空间上,保持了一定的信息冗余。这样就能在有信息损失的推理过程中,利用剩下的特征信息推理出正确的结果。因此,有了 Linear Bottleneck 和 Inverted Residuals 设计,既能逐步筛选有效的抽象特征,而又不在 bottleneck 时,丢失重要的特征信息。
下面的实验现象是:

下面图的实验,将 Linear bottleneck 的猜想用到 MobileNet 的表现,还顺带讨论了 shortcut 对 expansion module 的影响。

这里,我也借机表达个人观点。首先,对于 Inverted residuals 的设计,作者很诚实告诉我们这是一个无心插柳柳成荫的故事。他最初的动机,只是打算借助 classical residual connections 在梯度传播上的优势,提高网络推理的准确性。然而,classical residual connections 是 shortcut between expansions 的,这对前面 Memory Efficinet Trick 在实现上很不友好,甚至相当麻烦。因此,补充了一个 Shortcut between bottleneck 的实验对照,本来只要效果过得去,就谢天谢地了。没想到,这效果竟然比传统的要好,所以他也把这个点作为 MobileNet V2 的其中一个亮点放在了标题。

对 Linear bottleneck Inverted residual block ,作者尝试从信息流动的角度进行解释。他直观地把这种 block 拆分成两个阶段,一个是 expansion ,再就是 bottleck 。他认为 expansion layers 可以看作相应层的 capacity ,这好比是一种特征池。而 bottleneck 则是 expressiveness ,对众多特征反应结果的综合概括。这仿佛就是人类对事物的认知过程,先从众多维度,各个方面,分析事物的不同特性,这是一种发散型分析,expansion 的过程。然后,对这些不同的特性进行总结,从而归纳出该事物的一个简单规律,是事物的抽象而完整表述,bottlenect 的过程。基于作者的这解析角度,我们可以不难猜测 Inverted residuals 成功背后的原理是,事物的抽象表达更完整了,而且更容易保全事物的信息。用 Shortcut between Expansions 保留事物的重要信息,犹如在茫茫人海中,确认眼神找对象一样,是个大海捞针的过程,稍不留神 bottleneck 就把信息丢了,丢了再 shortcut 也只是徒劳。Expansion 空间维度那么高,事情反而不好学了。

总结
当初笔者粗读原文时,MobileNet V2 给我的感觉就是并没有创意,改几个连接,做几个尝试性实验出来的成果。随着对作者观点的深入,虽然现在我还没感受 MobileNet V2 的重大突破,但是我觉着作者的想法和观点很大胆,很独特,很新颖,很有趣。主要原因是作者看待 bottleneck 的方式,是跟原来相反的。原来人们都爱把 bottleneck 放在两个胖子中间,比如 ResNeXt 就是这种观点,而作者却把 bottlenecks 看作一个胖子的两端,这么想的话,其实这个胖子还有不少的瘦身空间,比如对胖子引入 ResNeXt 的 Cardinality 参数等。也正因为作者很多这种“反过来想”的研究观点,丰富了我对轻量网络结构设计的观点,所以这篇论文更适合耐心品尝,浮躁很难感受到这篇文章的真实亮点。















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









