






InputSplit
输入分片(Input Split):在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。
Hadoop 2.x默认的block大小是128MB,hadoop 1.x默认的block大小是64MB,可以在hdfs-site.xml中设置dfs.block.size,注意单位是byte。
分片大小范围可以在mapred-site.xml中设置,mapred.min.split.size mapred.max.split.size,minSplitSize大小默认为1B,maxSplitSize大小默认为Long.MAX_VALUE = 9223372036854775807

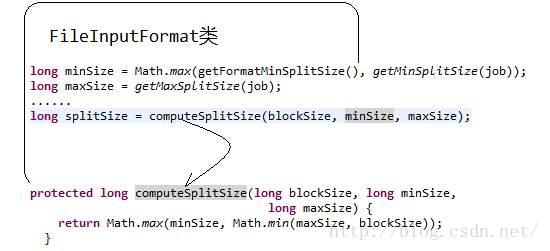
没有设置分片的范围的时候,分片大小是由block块大小决定的,和它的大小一样。比如把一个258MB的文件上传到HDFS上,假设block块大小是128MB,那么它就会被分成三个block块,与之对应产生三个split,所以最终会产生三个map task。第三个block块里存的文件大小只有2MB,而它的block块大小是128MB,那它实际占用Linux file system的多大空间?
答案是实际的文件大小,而非一个块的大小。
MapReduce的三个过程
如果我们有10亿个数据,Mapper会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
总结:网络带宽严重被占降低程序效率;
场景二:
假设使用美国专利数据集中的国家一项来阐述数据倾斜这个定义,这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅Mapper中的键值对、中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于一个单一的Reducer之上,压倒这个Reducer,从而大大降低程序的性能。
总结:单一节点承载过重降低程序性能;
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能

优化MapReduce作业所使用带宽的步骤—Combiner,它在Mapper之后Reducer之前运行。Combiner是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被发送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce”过程,它只处理单台机器生成的数据。
小结:
在实际的Hadoop集群操作中,我们是由多台主机一起进行MapReduce的,
如果加入规约操作,每一台主机会在reduce之前进行一次对本机数据的规约,
然后在通过集群进行reduce操作,这样就会大大节省reduce的时间,
从而加快MapReduce的处理速度
二、Partitioner

step1.3就是一个分区操作。通过前面的学习我们知道Mapper最终处理的键值对<key,value>,是需要送到Reducer去合并的,合并的时候,有相同key的键/值对会送到同一个Reducer节点中进行归并。哪个key到哪个Reducer的分配过程,是由Partitioner规定的。在一些集群应用中,例如分布式缓存集群中,缓存的数据大多都是靠哈希函数来进行数据的均匀分布的,在Hadoop中也不例外。
MapReduce的使用者通常会指定Reduce任务和Reduce任务输出文件的数量(R)。
用户在中间key上使用分区函数来对数据进行分区,之后在输入到后续任务执行进程。一个默认的分区函数式使用hash方法(比如常见的:hash(key) mod R)进行分区。hash方法能够产生非常平衡的分区。
小结:分区Partitioner主要作用在于以下两点
针对多个map任务的输出按照不同的分区(Partition)通过网络复制到不同的reduce任务节点上,这个过程就称作为Shuffle。
Shuffle过程

Map端

map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。
1.在map端首先是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2.写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件
3.最后将磁盘中的数据送到Reduce中,图中Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Reduce端

1. Copy阶段:Reducer通过Http方式得到输出文件的分区。
reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据
2.
3.Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中
阶段:如果形成多个磁盘文件会进行合并
从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中
3.Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中
Hadoop中的压缩
Shuffle过程中看到,map端在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









