







 本文利用Python的Pandas和Matplotlib库,对智联招聘的Python职位数据进行清洗、分析和可视化。通过分析,发现北上广深等一线城市占据大部分Python职位,平均月薪与工作经验、学历正相关。同时,本科及以上学历需求量大,无经验或1-3年经验的岗位较多,博士和硕士学历的平均月薪显著高于其他学历。通过词云图,进一步揭示了岗位职责的关键特征。
本文利用Python的Pandas和Matplotlib库,对智联招聘的Python职位数据进行清洗、分析和可视化。通过分析,发现北上广深等一线城市占据大部分Python职位,平均月薪与工作经验、学历正相关。同时,本科及以上学历需求量大,无经验或1-3年经验的岗位较多,博士和硕士学历的平均月薪显著高于其他学历。通过词云图,进一步揭示了岗位职责的关键特征。
上一篇,我用了Excel对爬虫采集到的智联招聘数据进行了数据分析及可视化,用到软件是Excel, 这一篇,我们打算完全用Python来做同样的事。用到的库有Pandas、Matplotlib。np、pd、plt分别是numpy、pandas、matplotlib.pyplot的常用缩写。
Numpy(Numerical Python的简称)是Python科学计算的基础包。它提供了以下功能:
- 快速高效的多维数组对象ndarray。
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数。
- 用于读写硬盘上基于数组的数据集的工具。
- 线性代数运算、傅里叶变换,以及随机数生成。
- 用于将C、C++、Fortran代码集成到Python的工具。
除了为Python提供快速的数组处理能力,Numpy在数据分析方面还有另外一个主要作用,即作为在算法之间传递数据的容器。对于数值型数据,Numpy数组在存储和处理数据时要比内置的Python数据结构高效的多。此外,由低级语言(比如C和Fortran)编写的库可以直接操作Numpy数组中的数据,无需进行任何数据复制工作。
Pandas这个名字本身源于panel data(面板数据,这是计量经济学中关于多维结构化数据集的一个术语)以及Python data analysis。pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数。Pandas中用的最多的是DataFrame,它是一个面向列的二维表结构,且含有行标和列标。pandas兼具numpy高性能的数组计算功能以及电子表格和关系型数据库(如SQL)灵活的数据处理功能。它提供了复杂精细的索引功能,以便更为便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
Matplotlib是Python中常用的可视化绘图库,可以通过简单的几行代码生成直方图,功率谱,条形图,错误图,散点图等。Seaborn、ggplot、等诸多Python可视化库均是在此基础上开发的,所以学会matplotlib的基础操作还是很有必要的!它和Ipython结合的很好,提供了一种非常好用的交互式数据绘图环境。绘制的图表也是交互式的,你可以利用绘图窗口中的工具栏放大图表中的某个区域或对整个图表进行平移浏览。
数据来源:
Python爬虫爬取了智联招聘关键词:【Python】、全国30个主要城市的搜索结果,总职位条数:18326条(行),其中包括【职位月薪】、【公司链接】、【工作地点】、 【岗位职责描述】等14个字段列,和一个索引列【ZL_Job_id】共计15列。数据存储在本地MySql服务器上,从服务器上导出json格式的文件,再用Python进行数据读取分析和可视化。
数据简单清洗:
1.首先在终端中打开输入ipython --pylab。在Ipython的shell界面里导入常用的包numpy、pandas、matplotlib.pyplot。用pandas的read_json()方法读取json文件,并转化为用df命名的DataFrame格式文件。(DataFrame格式是Pandas中非常常用且重要的一种数据存储格式、类似于Mysql和Excel中的表。)
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdf = pd.read_json('/Users/zhaoluyang/Desktop/Python_全国JSON.json')#查看df的信息df.info()df.columns 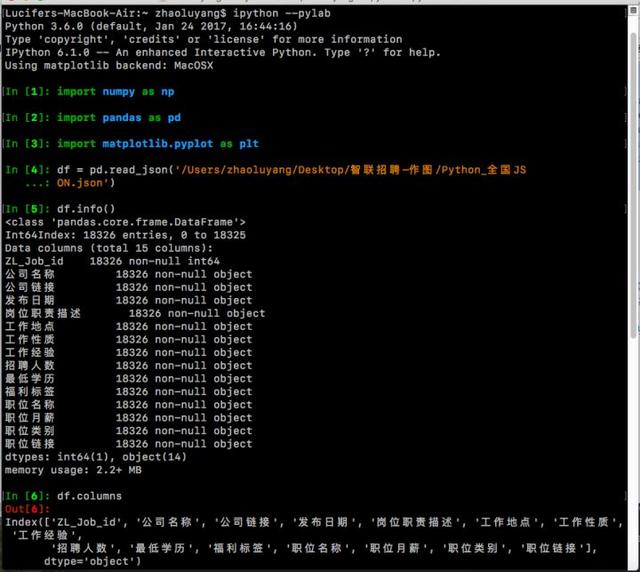
可以看到读取的df格式文件共有15列,18326行,pandas默认分配了索引值从0~18325。还有一点值得注意的:全部的15列都有18326个非空值,因为当初写爬虫代码时设置了, 如果是空值,譬如:有一条招聘信息其中【福利标签】空着没写,那么就用字符串代替,如“found no element”。
2.读取JSON文件时pandas默认分配了从0开始的索引,由于文件'ZL_Job_id'列中自带索引,故将其替换!替换后,用sort_index()给索引重新排列。
df.index = df['ZL_Job_id']#索引列用'ZL_Job_id'列替换。del(df['ZL_Job_id'])#删除原文件中'ZL_Job_id'列。df_sort = df.sort_index()#给索引列重新排序。df = df_sortdf[['工作地点','职位月薪']].head(10)3.下面,将进行【职位月薪】列的分列操作,新增三列【bottom】、【top】、【average】分别存放最低月薪、最高月薪和平均月薪。 其中try语句执行的是绝大多数情况:职位月薪格式如:8000-10000元/月,为此需要对【职位月薪】列用正则表达式逐个处理,并存放至三个新列中。 处理后bottom = 8000,top = 10000,average = 9000. 其中不同语句用于处理不同的情况,譬如【职位月薪】=‘面议’、‘found no element’等。对于字符形式的‘面议’、‘found no element’ 处理后保持原字符不变,即bottom = top = average = 职位月薪。q1,q2,q3,q4用来统计各个语句执行次数.其中q1统计职位月薪形如‘6000-8000元/月’的次数;q2统计形如月收入‘10000元/月以下’;q3代表其他情况如‘found no element’,‘面议’的次数;q4统计失败的特殊情况。
import redf['bottom'] = df['top'] = df['average'] = df['职位月薪']pattern = re.compile('([0-9]+)')q1=q2=q3=q4=0for i in range(len(df['职位月薪'])): item = df['职位月薪'].iloc[i].strip() result = re.findall(pattern,item) try: if result: try: #此语句执行成功则表示result[0],result[1]都存在,即职位月薪形如‘6000-8000元/月’ df['bottom'].iloc[i],df['top'].iloc[i] = result[0],result[1] df['average'].iloc[i] = str((int(result[0])+int(result[1]))/2) q1+=1 except: #此语句执行成功则表示result[0]存在,result[1]不存在,职位月薪形如‘10000元/月以下’ df['bottom'].iloc[i] = df['top'].iloc[i] = result[0] df['average'].iloc[i] = str((int(result[0])+int(result[0]))/2) q2+=1 else: #此语句执行成功则表示【职位月薪】中并无数字形式存在,可能是‘面议’、‘found no element’ df['bottom'].iloc[i] = df['top'].iloc[i] = df['average'].iloc[i] = item q3+=1 except Exception as e: q4+=1 print(q4,item,repr(e))for i in range(100):#测试一下看看职位月薪和bottom、top是否对的上号 print(df.iloc[i][['职位月薪','bottom','top','average']])#或者df[['职位月薪','bottom','top','average']].iloc[i]也可df[['职位月薪','bottom','top','average']].head(10)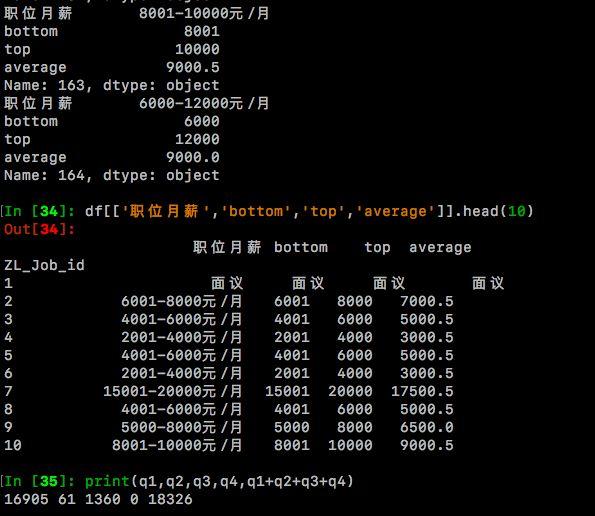
经过检查,可以发现【职位月薪】和新增的bottom、top、average列是能对的上。其中形如‘6000-8000元/月’的有16905条、形如‘10000元以下’的 有61条、'found no element'和'面议'加起来有1360条,总数18326条,可见是正确的。
4.进行【工作地点】列的处理,新增【工作城市】列,将工作地点中如‘苏州-姑苏区’、‘苏州-工业园区’等统统转化为‘苏州’存放在【工作城市】列。
df['工作城市'] = df['工作地点']pattern2 = re.compile('(.*?)(-)')df_city = df['工作地点'].copy()for i in range(len(df_city)): item = df_city.iloc[i].strip() result = re.search(pattern2,item) if result: print(result.group(1).strip()) df_city.iloc[i] = result.group(1).strip() else: print(item.strip()) df_city.iloc[i] = item.strip()df['工作城市'] = df_citydf[['工作地点','工作城市']].head(20)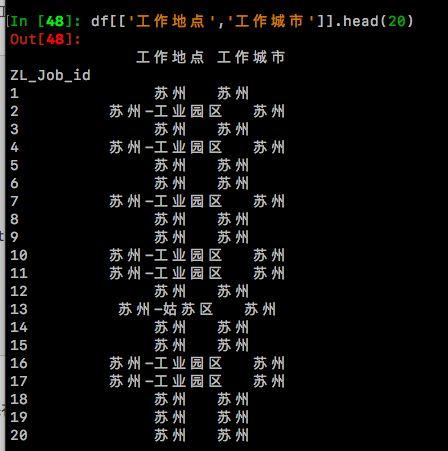
检查一下,没有错误,可以进行下一步的操作了!
数据分析和可视化
从可读性来看,应该是先进行数据清洗,然后进行分析及可视化,但是实际过程中,往往是交织在一起的, 所有下面让我们一步步来,完成所有的清洗、分析和可视化工作。除了具体的公司和职位名称以外,我们还比较关心几个关键词: 平均月薪、工作经验、工作城市、最低学历和岗位职责描述,这里岗位职责描述以后会用python分词做词云图,所以目前筛选出 【平均月薪】、【工作经验】、【工作城市】、【最低学历】这四个标签,这些标签可以两两组合产生各种数据。譬如我想知道各个城市
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5786
5786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









