






哈哈 准备开始挪一些 cv相的合集~
一、CVの白平衡算法
介绍OpenCV自带的三种白平衡算法使用 --4.7版本
OpenCV xphoto模块中提供了三种不同的白平衡算法,分别是:灰度世界算法、完美反射算法和基于学习的白平衡算法。本文将介绍其使用方法并给出代码演示,供大家参考。
因为xphoto模组是在OpenCV扩展部分,所以需要CMake编译contrib代码,这部分前面已介绍过多次,此处略过。下面是源码文件和编译后的头文件:
编辑
编辑
【1】灰度世界(GrayworldWB)-白平衡算法。
参考链接:
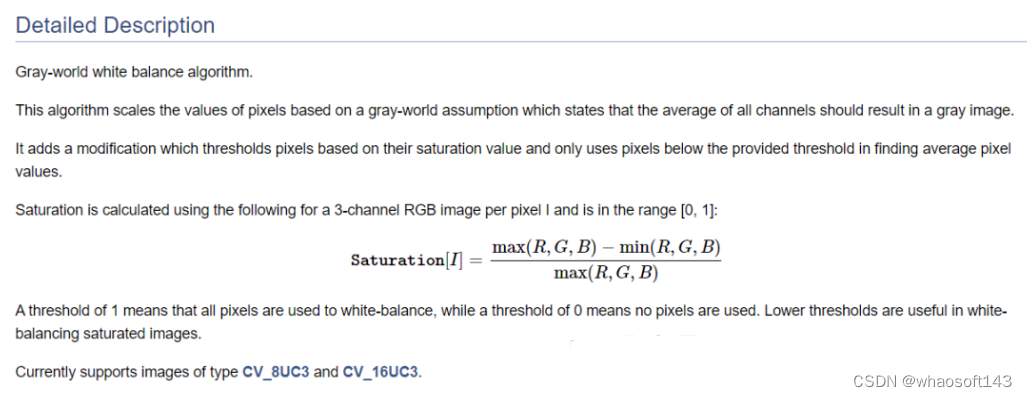
编辑
代码演示与效果:
效果对比(左:原图,右:白平衡算法结果图)

编辑

编辑
【2】完美反射(SimpleWB)-白平衡算法。
参考链接:
效果对比(左:原图,右:白平衡算法结果图)

编辑

编辑
【3】基于学习的(LearningBasedWB)-白平衡算法。
参考链接:
许多传统的白平衡算法都是基于统计的,即它们依赖于这样一个事实:某些假设应该在正确白平衡的图像中成立,例如众所周知的灰色世界假设。然而,通过在基于学习的框架中利用具有地面实况光源的大型图像数据集,通常可以获得更好的结果。下面如何训练基于学习的白平衡算法并评估结果的质量。
- 下载数据集进行训练。在本教程中,我们将使用Gehler-Shi 数据集。将所有 568 张训练图像提取到一个文件夹中。单独下载包含真实光源值 (real_illum_568..mat) 的文件。
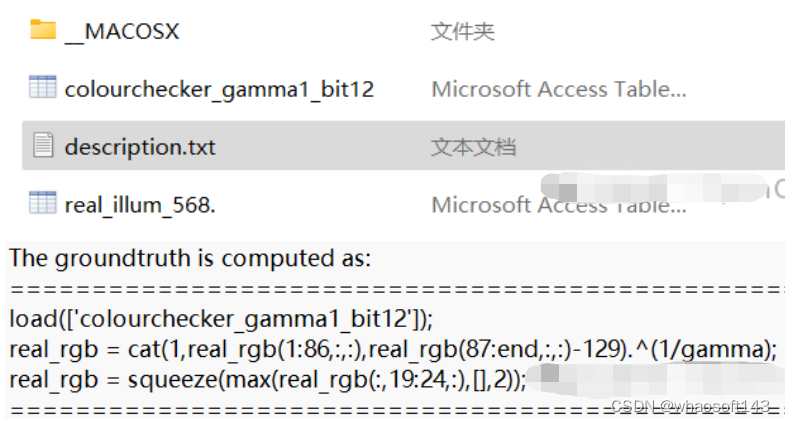
编辑
2. 我们将使用Python 脚本(learn_color_balance.py)进行训练。使用以下参数调用它:
python learn_color_balance.py -i <包含训练图像的文件夹的路径> -g <real_illum_568..mat的路径> -r 0,378 --num_trees 30 --max_tree_depth 6 --num_augmented 0
这应该开始在前 378 个图像(整个数据集的 2/3)上训练模型。我们将模型的大小设置为每个特征 30 个回归树对,并将树深度限制为不超过 6。默认情况下,生成的模型将保存到 color_balance_model.yml
3.在构建 LearningBasedWB 实例时,通过传递其路径来使用经过训练的模型:
Ptr<xphoto::LearningBasedWB> wb = xphoto::createLearningBasedWB (modelFilename);
简单来说就是通过给定数据集,一部分未经过白平衡矫正的图像,大概是下面这样:

编辑
目标图像也就是希望得到的白平衡矫正结果groundtruth,大概是下面这样,或者效果更好:

编辑
通过训练我们能得到一些参数,直接应用到新的图像上。训练好的参数模型保存到color_balance_model.yml文件中,使用时加载即可:
二、CV+CNN~数字识别
使用CNN和OpenCV实现数字识别
在当今世界,深度学习和图像处理技术正在各个应用领域得到利用。在这篇博文中,我们将使用卷积神经网络 (CNN) 和 OpenCV 库完成数字识别项目。我们将逐步掌握该项目如何执行。
- 项目准备
- 分离数据
- 数据可视化
- 数据预处理
- 数据生成
- 创建 CNN 模型
- 评估模型
- 使用 OpenCV 测试经过训练的模型
项目目的和范围
在这个项目中,我们的目标是利用卷积神经网络 (CNN) 和 OpenCV 的强大功能创建一个数字识别系统。该项目的范围包括建立一个可以准确识别数字的模型。通过这项工作,我们将展示深度学习和图像处理技术在解决实际问题中的应用。
实现步骤
【1】准备数据集。如下是0-9的示例图片,用于本项目训练使用。
编辑
等.....
【2】分离数据。我们正在指定数据集目录的路径。我们使用该os.listdir()函数获取指定路径内所有项目(文件和目录)的列表。该len()函数计算指定目录中的项目(文件和目录)总数。然后,我们打印的值noOfClasses。
我们正在定义名为images和 的数组classNo来保存我们的数据。
此代码读取来自不同类别的图像,将其大小调整为 32x32 像素的标准大小,并使用类别标签组织它们以进行深度学习。图像和类标签存储在列表中,然后转换为 NumPy 数组以进行进一步处理。目标是准备这些图像和标签来训练深度学习模型。
这两行代码将数据集分割为训练集、验证集和测试集,使模型能够在一个子集上进行训练,在另一个子集上进行验证,并在剩余部分上进行测试。这是深度学习中评估和提高模型性能的常见做法。
x_train, x_test, y_train, y_test = train_test_split(images, classNo, test_size=0.5, random_state=42)将数据集分为训练集 (x_train和y_train) 和测试集 (x_test和y_test)。它划分数据,以便分配 50% 用于测试,并使用固定随机种子 ( random_state=42) 来实现再现性。
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=42)进一步将训练集分为训练集 (x_train和y_train) 和验证集 (x_val和y_val)。它指定 20% 的训练数据用于验证。同样,为了获得一致的结果,随机种子设置为 42。
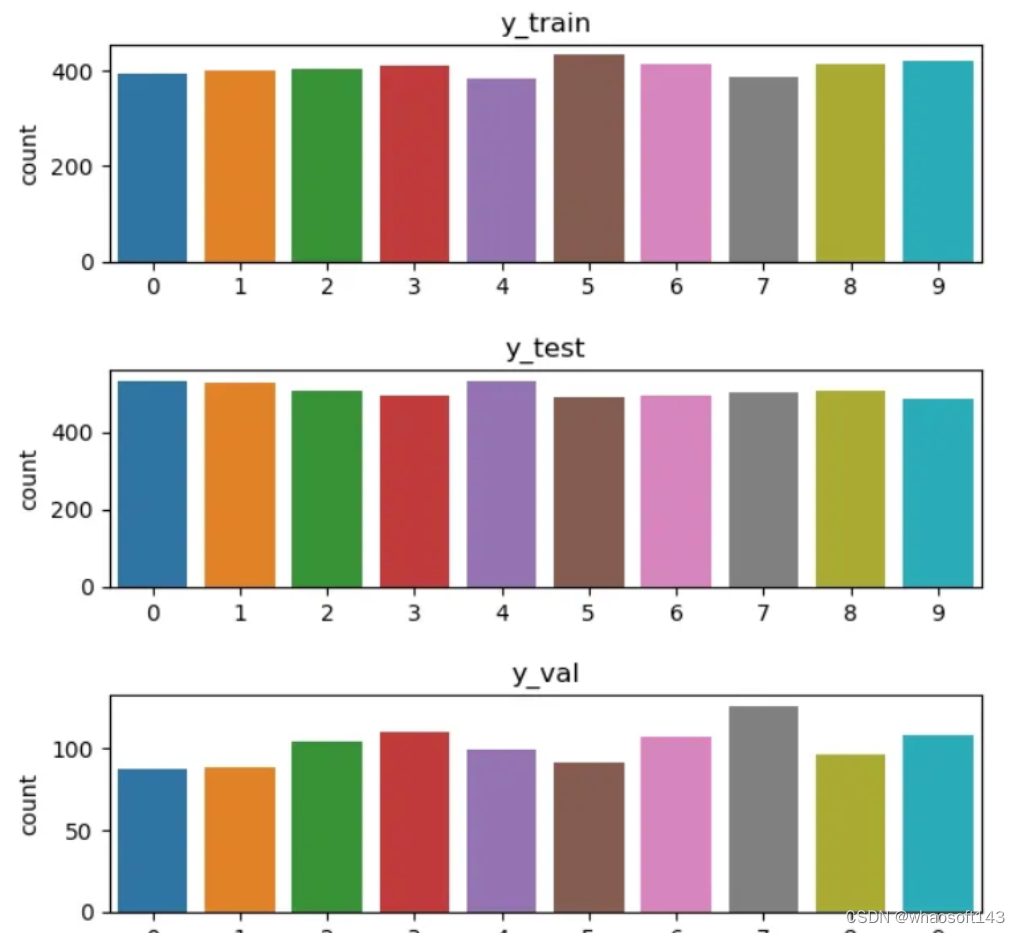
【3】数据可视化。
使用条形图生成训练、测试和验证数据集中类分布的可视化表示。它有助于了解不同数据子集的类别分布的平衡或不平衡程度。
编辑
【4】数据预处理。
定义一个预处理函数,将图像转换为灰度、执行直方图均衡并标准化像素值。然后,它将这个预处理函数应用于训练、测试和验证数据集。最后,它将图像重塑为模型训练所需的格式。这些预处理步骤有助于提高图像的质量和适用性,以输入深度学习模型。
【5】数据生成。
设置ImageDataGenerator通过对训练图像应用随机移位、缩放和旋转来执行数据增强。然后,生成器适合训练数据,以计算增强过程所需的统计数据和参数。这有助于模型从更多样化的增强图像中学习,提高其泛化新的和未见过的数据的能力。
使用 one-hot 编码将原始类标签转换为二进制矩阵格式。这种格式通常在机器学习中处理分类数据时使用,因为它为需要数字输入的训练模型提供了合适的表示。
【6】创建CNN模型。
定义用于图像分类的 CNN 模型,对其进行编译,使用数据增强对其进行训练,并保存训练模型的权重和架构以供将来使用。该模型旨在从输入图像中学习特征并将其分类为指定的类别之一。
【7】评估模型。
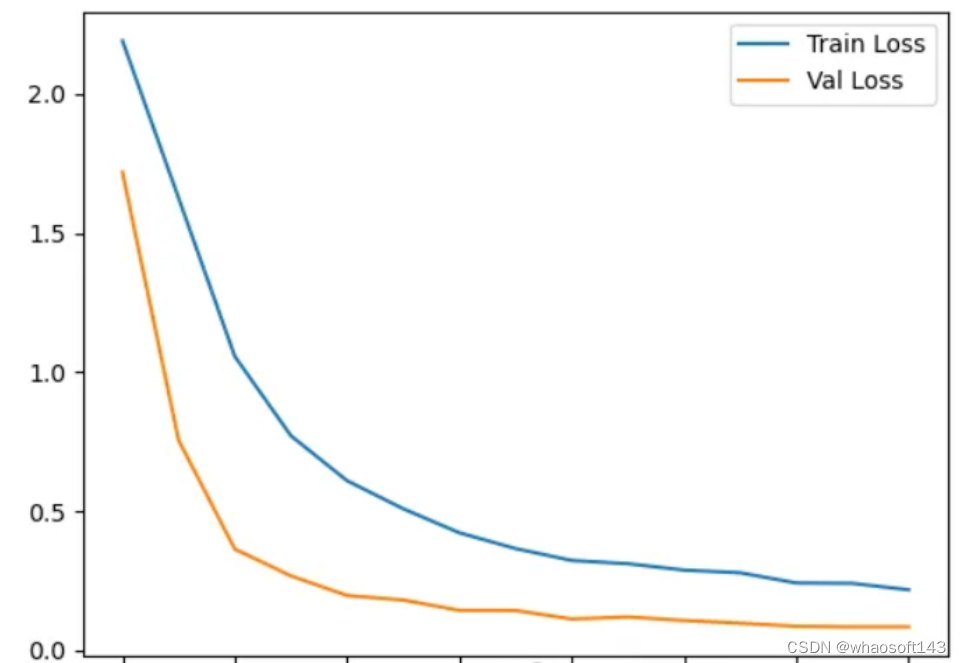
编辑
创建一个折线图,显示随着训练次数的增加,训练损失和验证损失。这是一种直观的方式来了解模型的学习效果以及是否过度拟合或欠拟合。
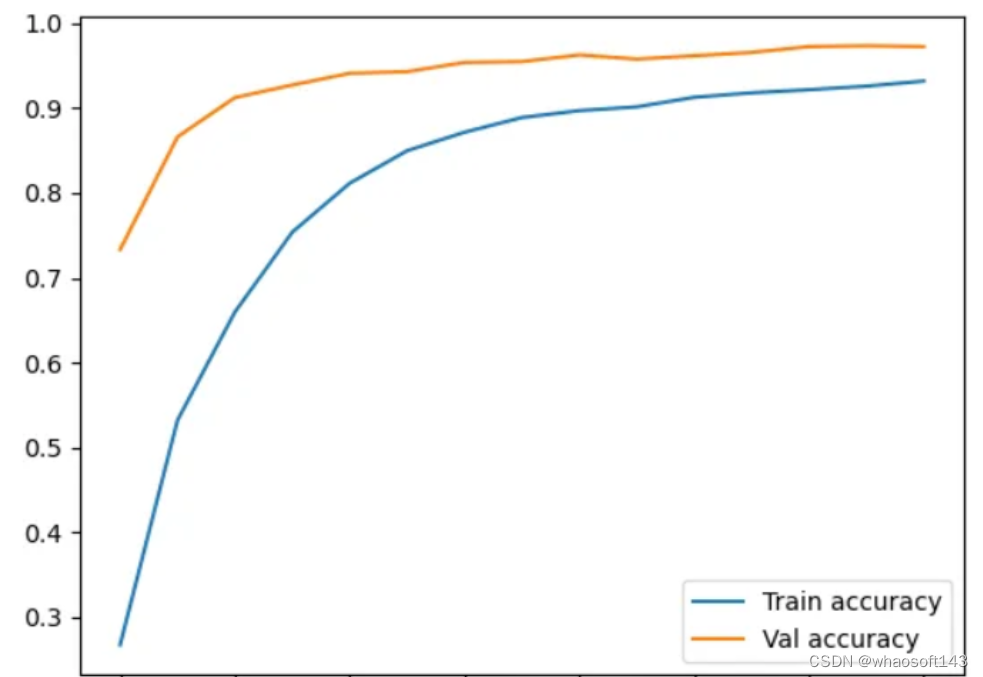
编辑
创建一个折线图,显示随着训练次数的增加,训练准确性和验证准确性趋势。这种可视化有助于评估模型从训练数据中学习的效果以及它推广到验证数据的效果。
编辑
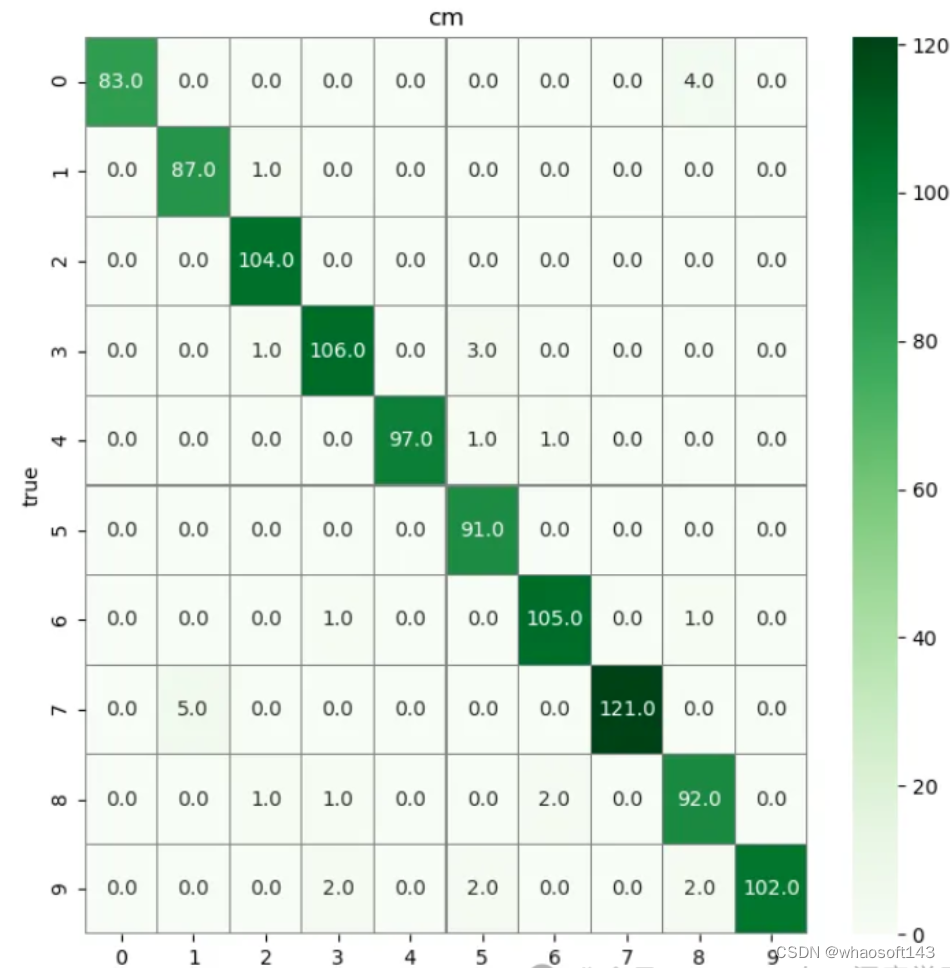
评估模型在测试数据集上的性能,计算验证数据集预测的混淆矩阵,然后使用热图可视化混淆矩阵。热图有助于可视化模型在类别预测方面的表现以及可能出错的地方。
【8】使用 OpenCV 测试经过训练的模型。
cap = cv2.VideoCapture(0):此行初始化视频捕获对象以从网络摄像头(摄像头索引 0)捕获帧。
cap.set(3, 480)和cap.set(4, 480):这些行将捕获的视频帧的宽度和高度设置为各 480 像素。
model = load_model("modelWeights.h5"):此行从“modelWeights.h5”文件加载预训练的 CNN 模型。
该代码进入循环以连续捕获和处理来自网络摄像头的视频帧。success, frame = cap.read():此行从网络摄像头捕获帧。success表示该帧是否捕获成功。
循环内部:
- 使用该函数处理捕获的帧并将其大小调整为 32x32 像素preProcess。
- 处理后的图像被重新整形为模型输入所需的格式。
- 该模型预测输入图像的类别概率。
- 提取具有最高概率和最大概率值的预测类别索引。
- 如果最大概率值大于 0.7,则使用 来将预测的类别索引和概率显示在框架上cv2.putText。
- 使用 来显示带注释的框架cv2.imshow。
if cv2.waitKey(1) & 0xFF == ord("q"): break:检查是否按下了“q”键。如果是,则循环中断,结束视频捕获和窗口显示。
总之,此代码从网络摄像头捕获视频帧,对其进行处理,将其输入到预先训练的模型中,并在视频输入上显示结果(类索引和概率)。循环继续,直到按下“q”键。
让我们通过运行代码并向计算机的摄像头显示一个数字来测试我们的项目。

编辑
当我在手机屏幕上显示数字 8 时,OpenCV 会处理图像。随后,我们向相机展示的照片将作为模型的输入。然后我们的模型将显示的数字预测为 8。
源码地址:
三、CVの目标颜色改变
colorChange与seamlessClone同属于Seamless Cloning部分,算法均来自下面这篇论文:
https://www.cs.jhu.edu/~misha/Fall07/Papers/Perez03.pdf
百度网盘下载:
链接:https://pan.baidu.com/s/1Ma_9ZF4r0SgNmfygHe3kgQ
提取码:0857
算法解读可参考下面链接:
https://blog.csdn.net/zhaoyin214/article/details/88196575
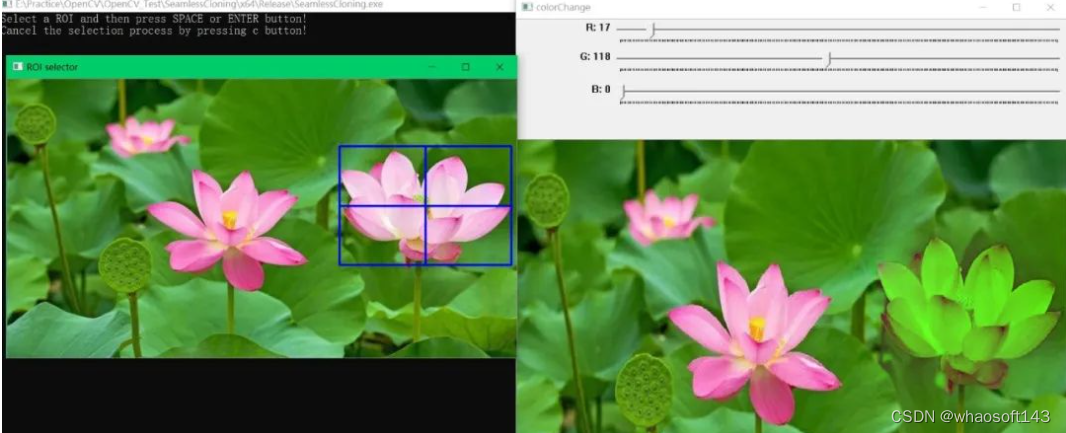
使用colorChange函数可以轻松将一幅图像中的指定目标颜色改变并尽可能保留其边缘信息,自然融合。函数说明:

编辑
参数:
src | 输入8位3通道图像(截取目标的大图) |
mask | 输入8位1或3通道图像(待改变颜色目标掩码区域图像) |
dst | 输出结果图(要求和src相同的大小和类型) |
red_mul | 红色通道乘积因子(建议值0.5~2.5) |
green_mul | 绿色通道乘积因子(建议值0.5~2.5) |
blue_mul | 蓝色通道乘积因子(建议值0.5~2.5) |
效果展示
手动框选左图中的目标,然后调整滑动条动态查看颜色改变效果:
实现步骤与源码
程序实现步骤:
(1) 使用selectROI函数框选指定目标;
(2) 使用三个滑动条动态改变red_mul,green_mul,blue_mul参数值;
(3) 滑动条回调函数中使用colorChange函数完成颜色改变。
src图:

编辑
框选ROI区域设定mask与参数设置(red_mul=1.0, green_mul=1.78, bule_mul=2.35)以及运行结果:
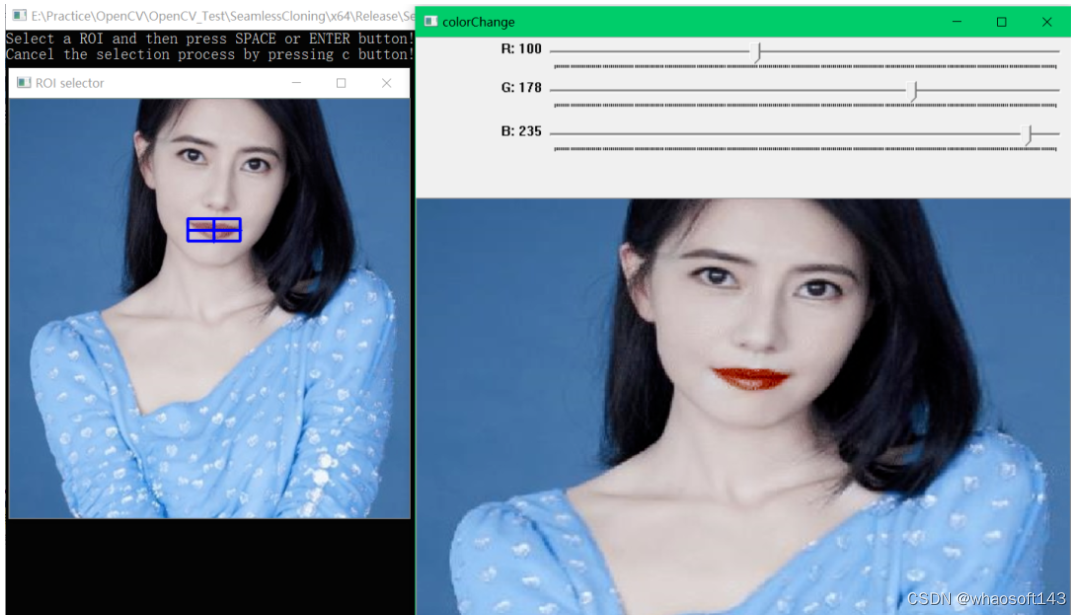
编辑
src图:

编辑
框选ROI区域设定mask与参数设置(red_mul=1.17, green_mul=0.47, bule_mul=1.23)以及运行结果:
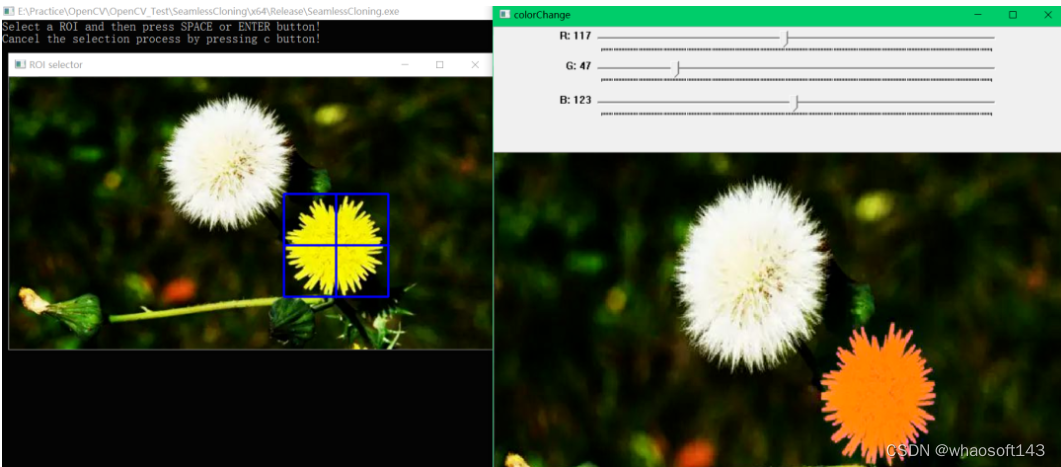
编辑
src图:

编辑
框选ROI区域设定mask与参数设置(red_mul=0.18, green_mul=1.17, bule_mul=2.35)以及运行结果:
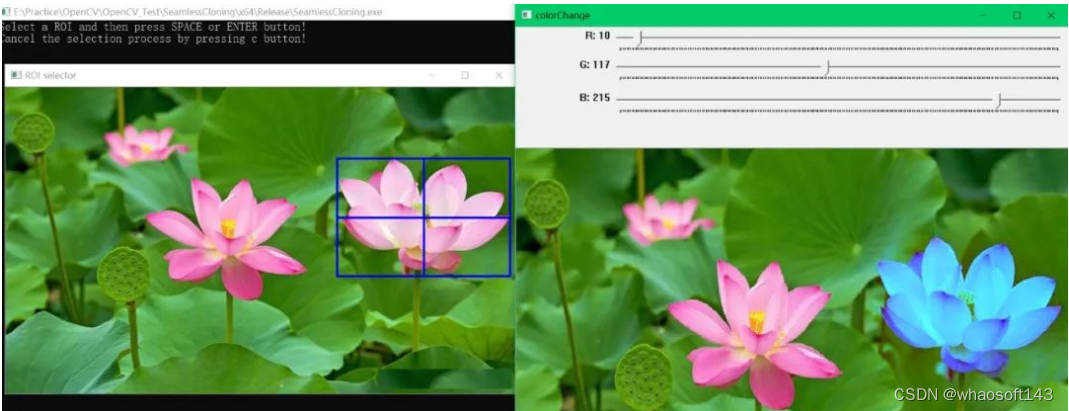
编辑
(red_mul=0.17, green_mul=1.18, bule_mul=0)运行结果:
编辑
效果见开头效果视频,C++源码如下:
注意:如果希望得到更准确的结果,可以用提取轮廓的方法精确设置mask,这样颜色改变后不会更改其他区域。比如唇色替换,可以先通过人脸关键点提取后,裁剪出嘴唇部分轮廓作为mask,这样结果也会更准确。
四、CVの搭建半自动标注工具
用Python和OpenCV搭建一个半自动标注工具
样本标注是深度学习项目中最关键的部分,甚至在模型学习效果上起决定性作用。但是,标注工作往往非常繁琐且耗时。一种解决方案是使用自动图像标注工具,它可以大大减少标注的时间。
主要介绍的半自动标注工具为pyOpenAnnotate,此工具是基于Python和OpenCV实现,最新版本为0.4.0,可通过下面指令安装使用:
详细介绍与使用步骤参考链接:
编辑
标注效果:

编辑
效果如上图所示,标注完成后可以生成标注文件,后面部分将详细介绍其实现步骤。
实现步骤
实现原理流程:
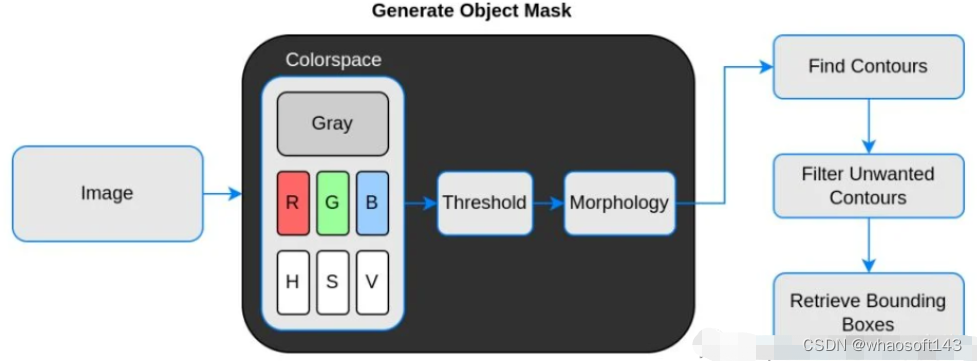
编辑
说明:
【1】Threshold(二值化)只接受单通道图像,但这里并不是直接使用灰度转换图来处理,而是从灰度图、R、G、B、H、S、V通道图像中找到对比度最高的图像来做二值化。
【2】二值化之后并不能保证总是得到我们需要的掩码,有时会有噪声、斑点、边缘的干扰,所以加入了膨胀、腐蚀等形态学处理。
【3】最后通过轮廓分析得到对象的边界框,也就是左上角和右下角坐标。
代码讲解与演示
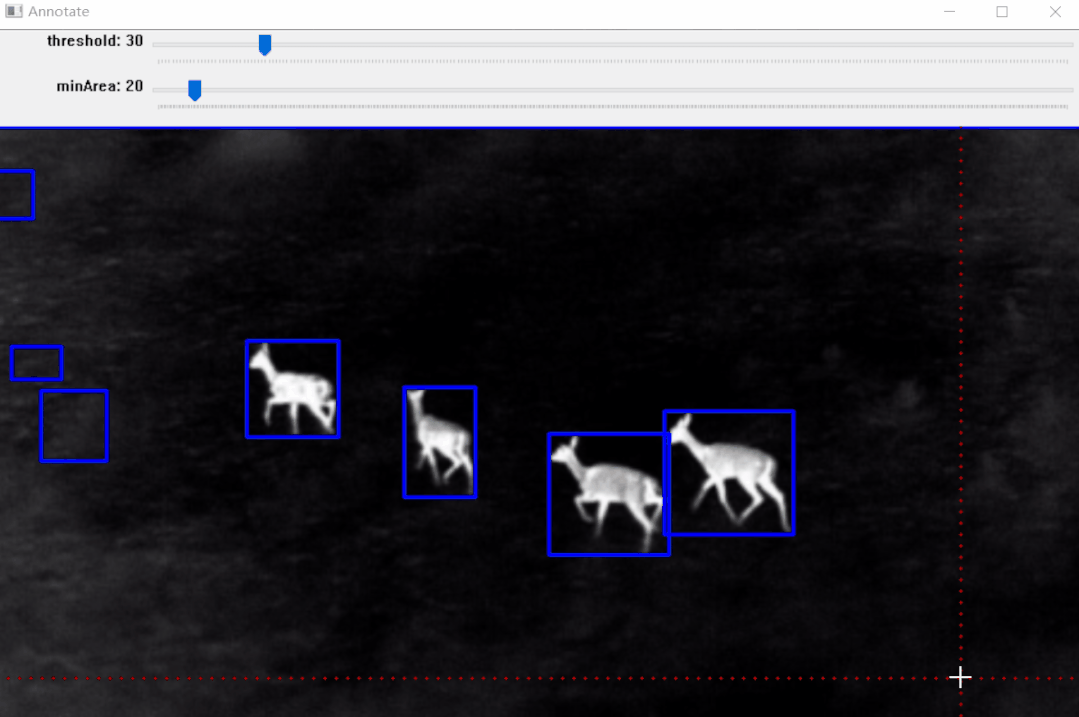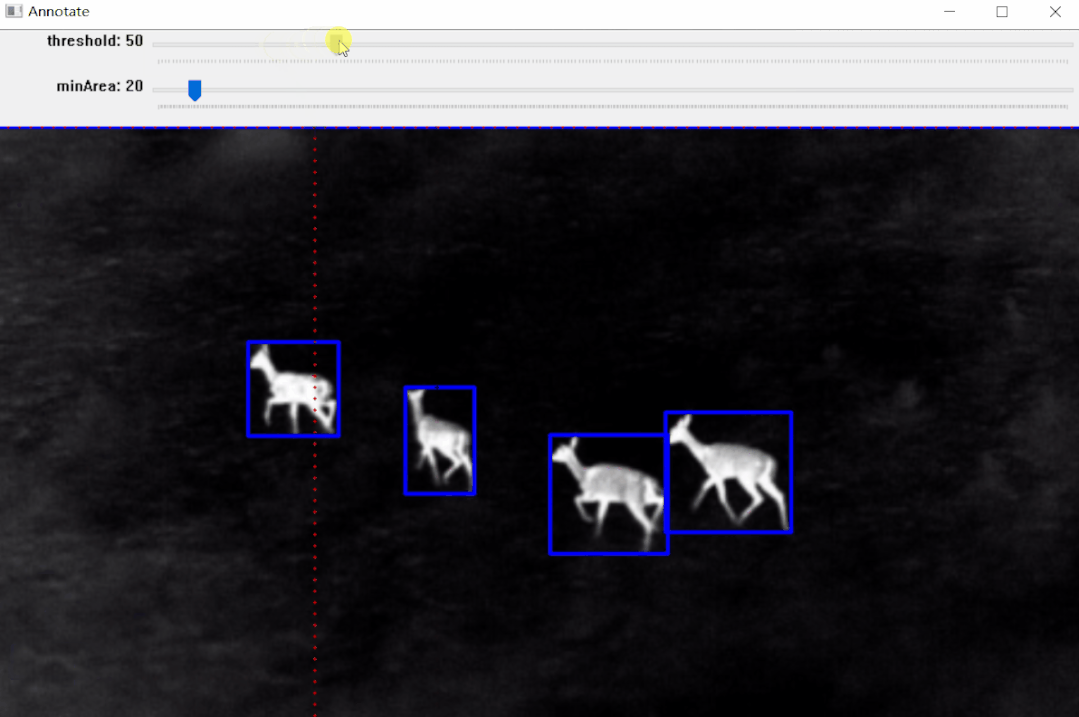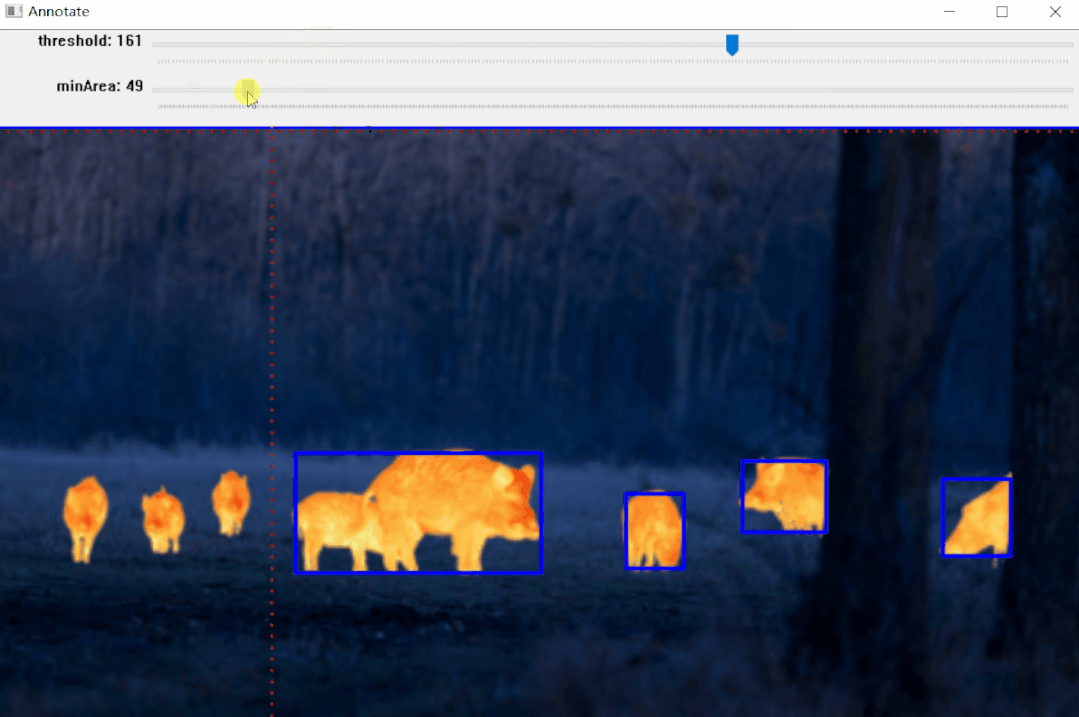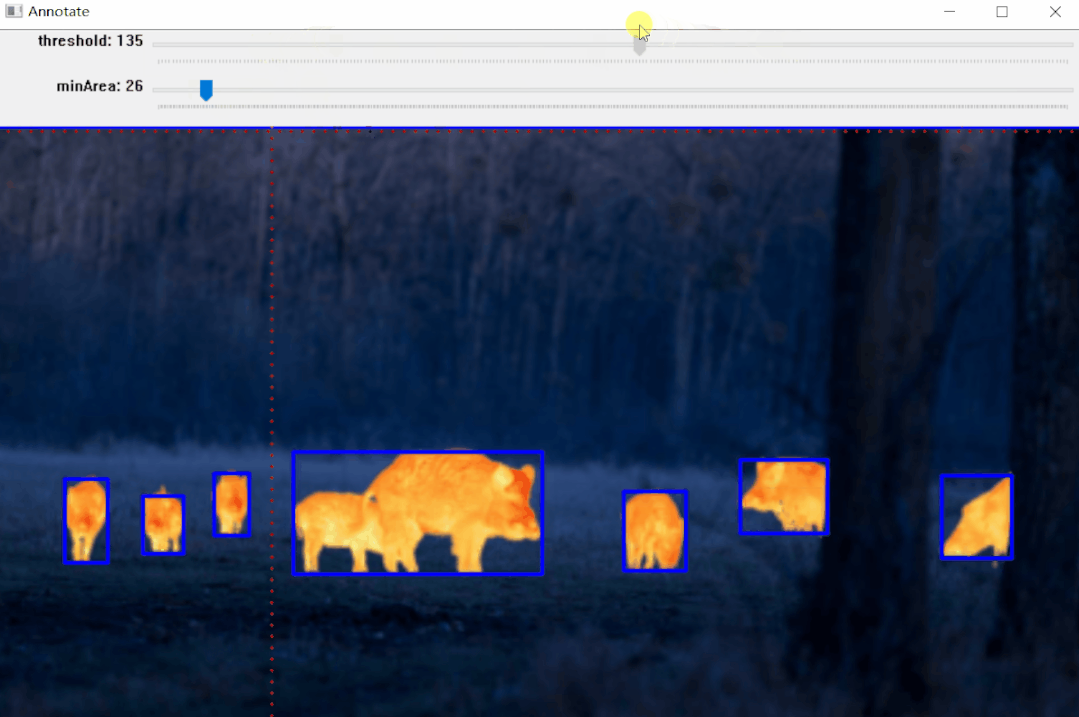
实例:雄鹿红外图像标注
整体实现步骤:
【1】选择色彩空间
【2】执行阈值

编辑
【3】执行形态学操作
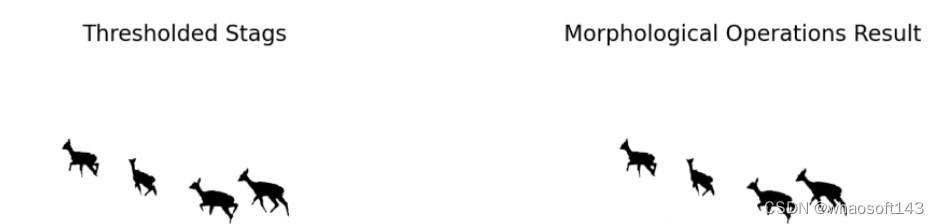
编辑
【4】轮廓分析以找到边界框

编辑
【5】过滤不需要的轮廓
【6】绘制边界框
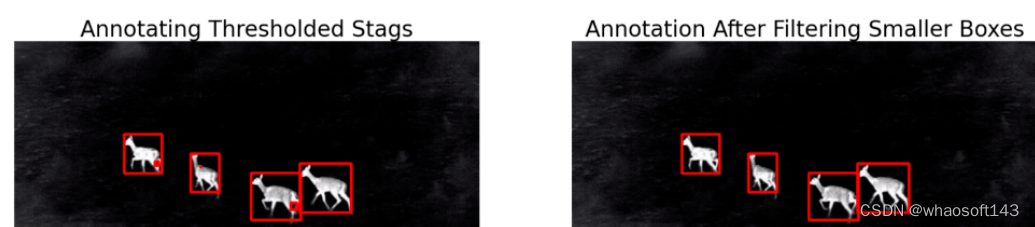
编辑
视频标注:

编辑
【7】以需要的格式保存
Pascal VOC、YOLO和COCO 是对象检测中使用的三种流行注释格式。让我们研究一下它们的结构。
I. Pascal VOC 以 XML 格式存储注释
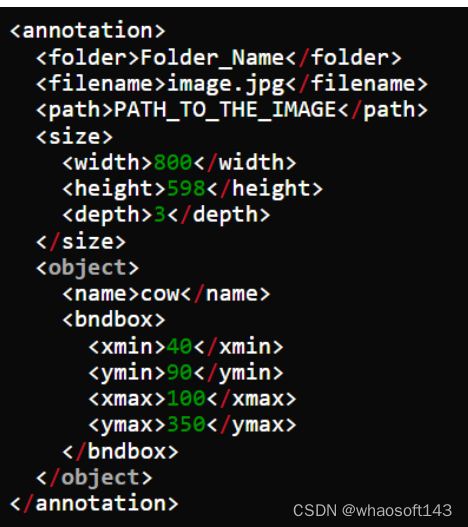
编辑
II. YOLO标注结果保存在文本文件中。对于每个边界框,它看起来如下所示。这些值相对于图像的高度和宽度进行了归一化。
让边界框的左上角和右下角坐标表示为(x1, y1)和(x2, y2)。然后:
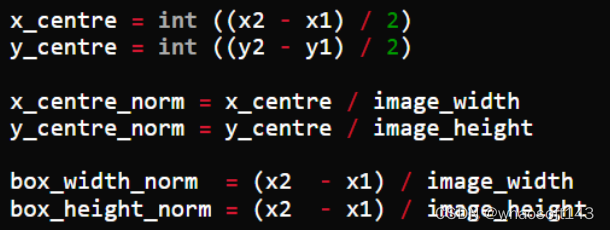
编辑
III. MS COCO
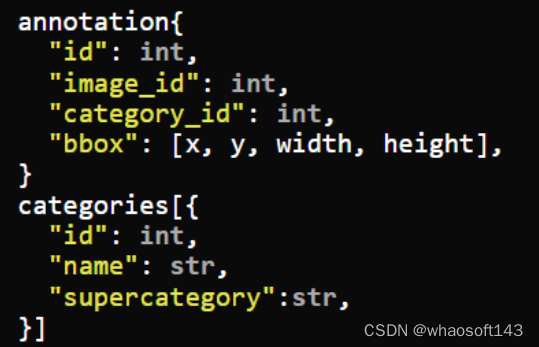
编辑
这里以YOLO Darknet保存格式为例(当然,你可以保存其他格式):
标注结果显示与保存:
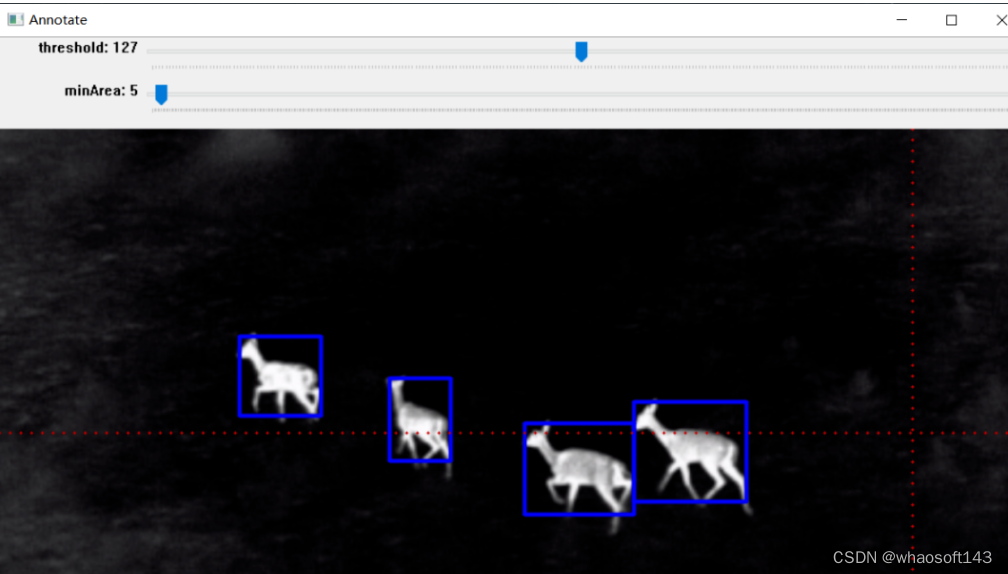
编辑

编辑
五、CVの粘连大米分割计数
测试图如下,图中有个别米粒相互粘连,本文主要演示如何使用OpenCV用两种不同方法将其分割并计数。

编辑
# 方法一:基于分水岭算法
基于分水岭算法分割步骤如下:
【1】高斯滤波 + 二值化 + 开运算

编辑
【2】距离变换 + 提取前景

编辑

编辑
【3】标记位置区域

编辑
【4】分水岭算法分割
【5】轮廓查找和标记

编辑
#方法二:轮廓凸包缺陷方法
基于轮廓凸包缺陷分割步骤如下:
【1】高斯滤波 + 二值化 + 开运算

编辑
【2】轮廓遍历 + 筛选轮廓含有凸包缺陷的轮廓

编辑
【3】将距离d最大的两个凸包缺陷点连起来,将二值图中对应的粘连区域分割开,红色圆标注为分割开的部分

编辑
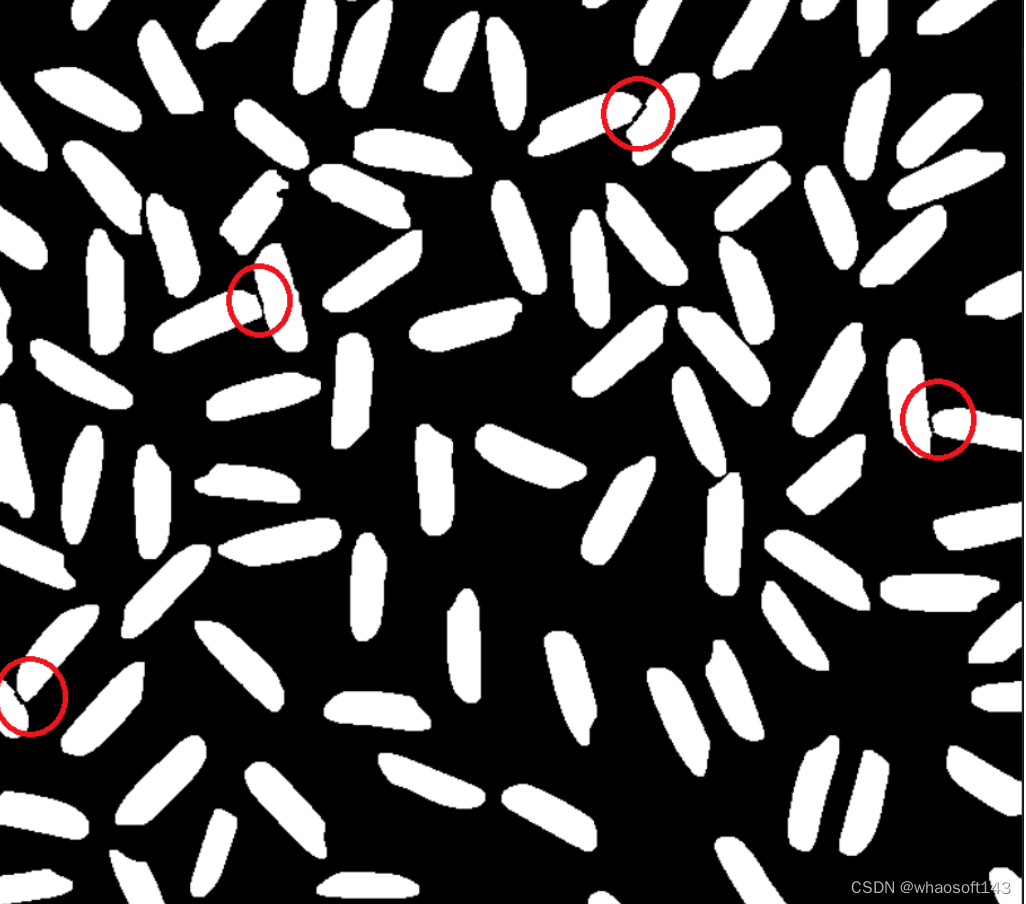
编辑
【4】重新查找轮廓并标记结果

编辑
六、CVの老人跌倒监测
使用Python、OpenCV和MediaPipe搭建一个老人跌倒智能监测系统。
老人监测系统是一种智能检测系统,可以检测老人是否躺在床上或是否跌倒在地。这是一个解决实际问题的程序,可用于在您外出工作或外出时监控家中的老人,以便在出现任何问题时通知您。
实现步骤
【1】导入必要的模块:
在 python 中导入 Numpy、MediaPipe 和 opencv
【2】定义一个计算角度的函数:
由于我们将根据我们使用 OpenCV 获得的角度和坐标来假设一个人是在行走还是跌倒在地上,因此,我们必须计算角度,最简单的方法是定义一个函数,然后调用它在程序中。
【3】查找坐标:
我们还必须找到坐标,以便我们可以在条件下使用它们,也可以将它们与calculate_angle函数一起使用。
【4】如何知道主体(老人)是安全的还是跌倒的?
我们将借助从 cv2 和 mediapipe 获得的坐标以及使用上述定义的函数获得的角度来找到这一点。
由于我们正在获取眼睛臀部和脚踝的坐标,因此我们知道当一个人平躺(倒下)时,他的眼睛、臀部和脚踝之间的角度在 170 到 180 度的范围内。因此,我们可以简单地提出一个条件,当角度在 170 -180 度之间时,我们可以说一个人摔倒了。
现在你的脑海中可能会出现一个问题,即如何确定这个人是否真的摔倒了,或者他是否只是躺在床上,因为在这两种情况下,角度都在相同的范围内。
我们也会回答它,所以请继续阅读:)
【5】如何区分床和地板?
我们将再次使用从 OpenCV 获得的坐标,然后使用它来找到床的坐标,然后在检查跌倒条件时引入一个新条件,即当受试者的坐标与床坐标一致时,这意味着一个人在床上时自然是安全的。这种情况将排除跌倒的情况,程序将显示安全。只有当此条件变为假时,才会检查跌倒条件和其他步行和尝试步行条件。
因此,通过引入带有床坐标的单一条件,我们也解决了上述问题。
【6】让我们在屏幕上打印结果:
现在打印摔倒和安全等的结果;我们可以很容易地使用 cv2 中的 putText 函数来显示保存在变量 stage 中的文本。
该函数的示例用法如下所示:
【7】添加图形用户界面:
最终效果:

编辑

编辑

编辑

编辑
完整代码下载链接:
https://github.com/Alwaz-Sheikh/Alwaz
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









