






目前,基于纯视觉的3D感知模型已经取得了非常不错的成绩,其性能指标逐渐向使用激光雷达作为输入的感知模型看齐。但是!虽然纯视觉的感知算法已经取得了非常好的效果,但是由于相机采集到的是2D图像信息,物体在3D坐标系下的深度信息会在相机的成像过程中消失,这就导致纯视觉的感知模型对深度的估计还有待进一步的加强。而现在比较流行的一种技术路线是借助激光雷达传感器采集到的点云信息对视觉模型进行监督;其中一种监督方式就是利用知识蒸馏的思想,让激光雷达模型作为教师模型,视觉模型作为学生模型,利用激光雷达能够更加准确表达物体几何和位置的能力对视觉模型进行跨模态蒸馏监督。
今天介绍的一篇是来自旷视的自动驾驶感知论文,并且中稿了今年的CVPR 2023视觉顶会。该文章的主要贡献点是提出了一种通用的跨模态知识蒸馏框架去提升单模态的感知模型能力,是一篇很不错的将知识蒸馏技术应用到自动驾驶感知任务的论文。主打一个通用!用于BEV 3D检测的通用跨模态蒸馏框架!
UniDistill算法模型整体结构
由于自动驾驶的车辆上配备了不同的传感器采集数据,如相机采集到的图像数据,激光雷达采集到的点云数据,所以会收集到不同模态的数据表示。而这篇文章提供了一种通用的跨模态蒸馏思路,如下图所示。
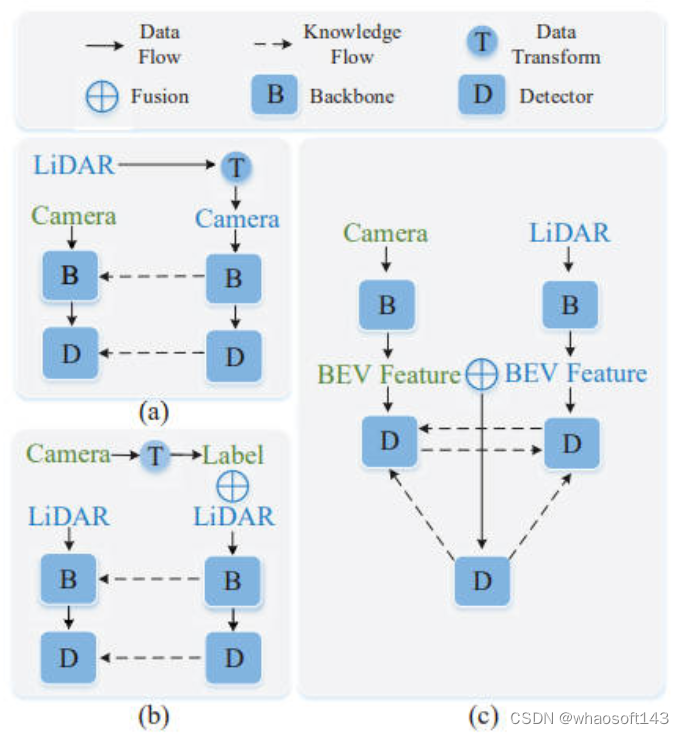
其中图中的(a)和(b)主要是指知识蒸馏中的教师模型和学生模型采用相同的数据模态,如(a)的图像数据,或者(b)的点云数据。而文章的创新点是提出了(c)跨模态蒸馏,可以让激光雷达或者视觉模型分别充当教师或者学生模型进行蒸馏,从而实现了通用意义上的蒸馏框架。而论文中所提出的蒸馏框架整体结构图如下。
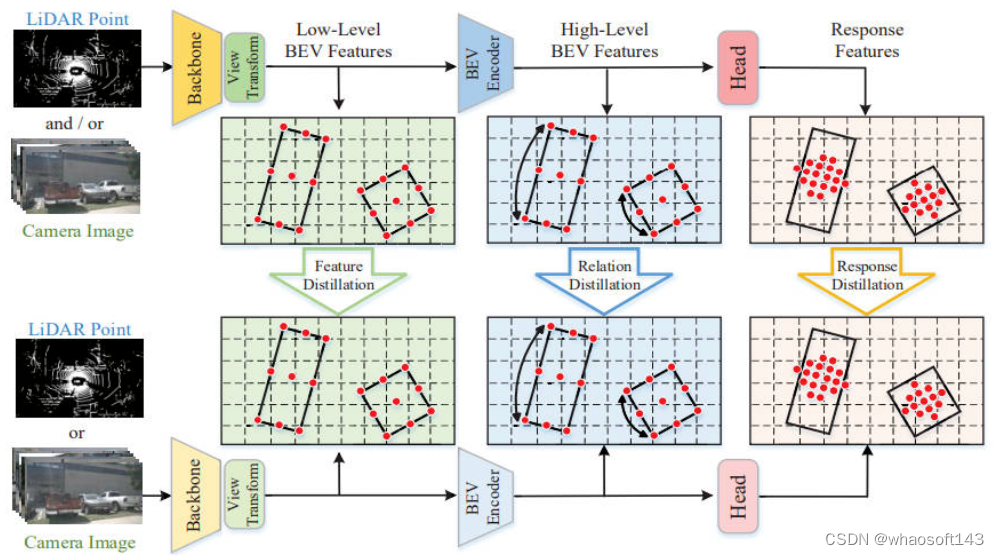
其中框架图的上方代表该知识蒸馏网络的教师模型(数据输入可以采用激光雷达的点云数据或者相机采集的图像数据),框架图的下方代表知识蒸馏网络的学生模型(数据输入同教师模型)。
通过整个算法框图可以看出文章的创新点主要包括三部分的蒸馏子模块
- Feature Distillation(Low-Level级蒸馏):对应上图中的绿色部分,将教师和学生模型的主干网络提取出来的低级语义特征进行蒸馏,这部分是蒸馏框架中的第一层蒸馏
- Relation Distillation(High-Level级蒸馏):对应上图中的蓝色部分,将教师和学生模型的BEV Encoder提取出来的高级语义特征进行蒸馏,这部分是蒸馏框架中的第二层蒸馏
- Response Distillation(Response级蒸馏):对应上图中的粉色部分,将教师和学生模型的Head的输出结果特征进行蒸馏,这部分是蒸馏框架中的第三层蒸馏
接下来就详细介绍一下上述三部分蒸馏子模块具体的工作流程~
Feature Distillation(Low-Level级蒸馏)
因为网络模型浅层可以提取到物体较为丰富的语义特征,文章中就将教师和学生模型主干网络提取到的特征进行了Low-Level级的蒸馏,用于对二者的特征进行对齐。论文中也有提到,一种比较直觉的特征蒸馏方法就是进行点对点的特征蒸馏,但是由于不同模态背景之间的差异性将会弱化蒸馏的性能,所以文章中的解决方案是选择只对前景区域进行蒸馏。除此之外,由于大类目标的前景区域要比小类目标的前景区域在BEV空间上占的面积要多,从而会导致模型更多的关注对大类目标的前景蒸馏,而忽略对小类目标蒸馏的学习,所以文章中的解决方案是无论是大类目标还是小类目标,都只选择九个关键点(对应整体结构中的九个红色的点)进行蒸馏,从而使得模型进行均等的学习。
所以,针对上述提到的不同模态背景区域差异以及不同类目标对蒸馏的贡献度不同的问题,论文针对Feature Distillation蒸馏子模块提出的蒸馏损失如下

但是作者进行实验发现,由于教师模型和学生模型的模态是不相同的,从而导致两种模态的特征之间存在语义gap问题,弱化最终的蒸馏学习效果。在这里作者是采用了1x1的卷积层充当Adaption Layer来缩短两种模态间的语义gap。注意:这里提到的Adaption Layer只会在训练的过程中用到,模型在推理的过程中就会去除掉Adaption Layer。
Relation Distillation(High-Level级蒸馏)

在这里同样会出现Feature Distillation中提到的不同模态之间的语义gap问题,所以作者还是采用了一个另外的1x1卷积充当Adaption Layer缓解不同模态之间的语义差距。
Response Distillation(Response级蒸馏)

论文实验结果
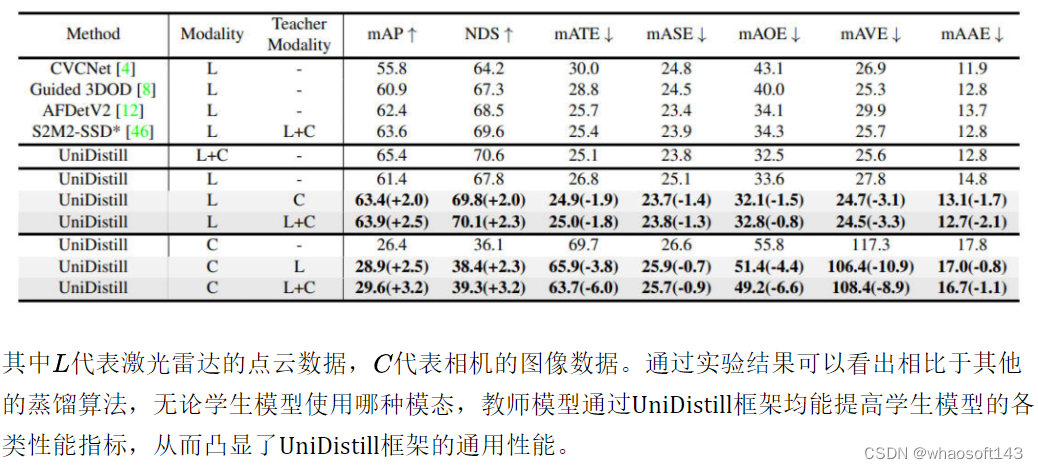
首先给出UniDistill和其他自动驾驶感知算法的比较实验,实验中给出了UniDistill在不同模态的情况下的nuScenes的test数据集的结果。
同时针对上文提到的,为了缩减学生模型和教师模型两类不同模态之间的语义gap而引入的adaption layer,作者也进行了相关的消融实验,结果如下图所示。
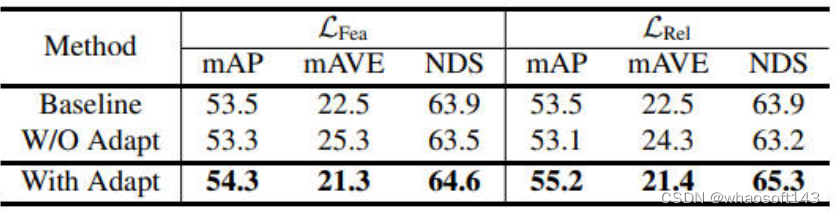
通过实验结果可以看出,当采用了1x1的卷积层充当adaption layer来缓解不同模态语义的gap之后,教师模型可以更加准确的指导学生模型的学习过程(无论是Low-Level级的蒸馏还是High-Level级的蒸馏),除此之外,论文中还使用了训练过程中的检测损失,进一步的说明adaption layer的重要作用。
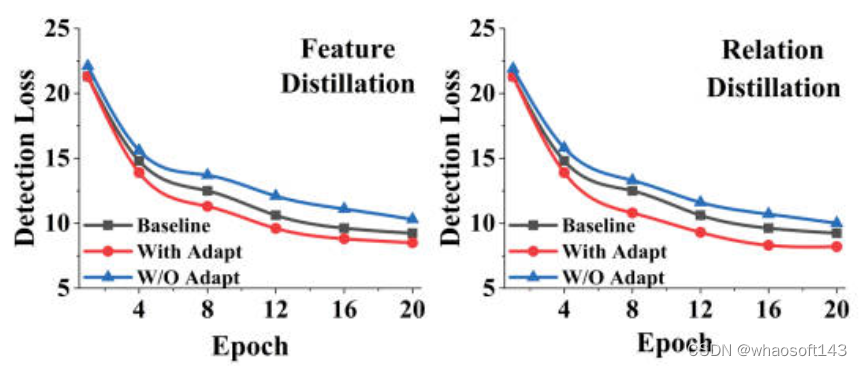
可以较为明显的看出,在采用了adaption layer后,学生模型的学习过程更加容易,无论是High-Level级的蒸馏还是Low-Level级的蒸馏,都有更低的代价损失。
最后论文作者也放出了使用了UniDistill框架的检测结果对比图,如下。
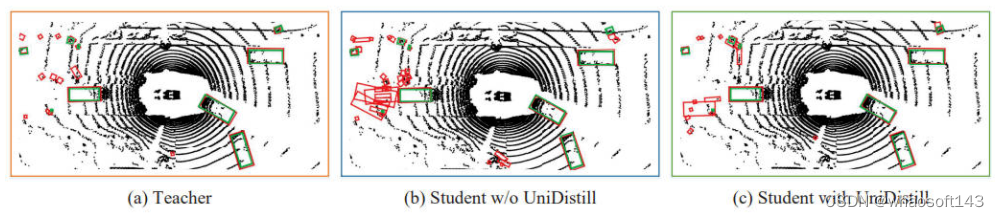
其中图中的红色框代表检测结果,绿色框代表真值结果。可以看出,通过教师模型引导学生模型的学习后,蒸馏后的学生模型要明显优于未经教师模型指导的模型,有更多准确的检测结果,同时具有更少的虚警。
总结
目前,虽然基于纯视觉的自动驾驶感知算法已经取得了非常大的进步,但是由于相机自身的成像机理,纯视觉的检测模型对于深度的估计依旧是一个痛点问题。而激光雷达的点云数据可以非常好的描述一个物体的空间和几何结构,所以激光雷达作为教师模型,视觉图像作为学生模型的蒸馏路线是一个比较火的研究方向。本文就是对旷视的一项发表在CVPR 2023的跨模态蒸馏论文进行了介绍,希望对大家有所帮助。
文章的链接和官方开源仓库链接如下:
- 论文链接:https://arxiv.org/abs/2303.15083
- 代码链接:https://github.com/megvii-research/CVPR2023-UniDistill















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









