







多通道CNN 基于部分卷积神经网络模型,并且结合 改善的三元组损失函数
本文的所提出的 CNN model 和 改进的三元组损失函数 可以认为是学习一个映射函数,使得能够将原始 raw image 映射成 一个特征空间,该特征空间使得同一个人的图像距离 小于 不同行人的图像距离。所以,所提出的框架,可以学习到最优的特征和距离度量,从而更好的进行行人的在识别任务。
五个层;

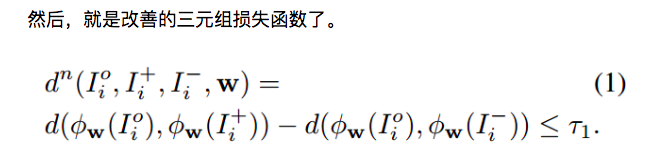

总结:
总体来说,感觉还是比较暴力的解决方案。一方面来说,文章提出了一种利用 human part 和 global body 进行精细化识别的框架来提供更加有效的 feature。另一方面,改善了三元组损失函数,使得最终的训练更加有效。 这是本文中,两个最重要的创新点。
A Discriminatively Learned CNN Embedding for Person Re-identification
主要的特点是采用双loss组合(Identification loss and verification loss)去增强特征的表达(提高类内特征的聚拢性和类间特征的区分性)。
扩大类间距离,缩小类内距离;
这里面的verification loss可以借鉴metric learning中的方法,如contrastive loss、triplet loss等等一系列。其实结合meric learning和cnn的方案最早是出现在人脸识别领域中(如王晓刚老师组的deep ID 系列和google的triplet等)。
Top-push Video-based Person Re-identification
文中针对图片序列(视频)提取 HOG3D 等特征,并提出 TDL(Top-push Distance Learning) 的距离度量学习方法。
TDL 跟近年来的很多方法(如 KISSME[2] )一样,也是基于马氏距离(Mahalanobis distance)进行学习。

















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









