






 本文介绍了如何在HBase与MapReduce环境中进行数据操作,包括从HBase读取和写入数据,以及数据迁移的场景。在解决运行HBase jar包时遇到的依赖问题上,提出了两种解决方案,并详细展示了使用RowCounter工具统计rowkey以及如何通过MapReduce将特定列族数据导入新表的过程。
本文介绍了如何在HBase与MapReduce环境中进行数据操作,包括从HBase读取和写入数据,以及数据迁移的场景。在解决运行HBase jar包时遇到的依赖问题上,提出了两种解决方案,并详细展示了使用RowCounter工具统计rowkey以及如何通过MapReduce将特定列族数据导入新表的过程。
在公司中,大多数都是hbase和mapreduce共同进行业务操作,hbase多数都是读写操作,hbase和hadoop在内部已经封装好了,我们要做的就是调用。
常见的模式
1、从hbase读取数据
将hbase的数据作为map的输入
2、将数据写入hbase
将hbase作为reduce输出
3、从hbase读,再写入hbase
场景:数据迁移
比如有张表,有20列table01(20col),我需要将其中的10列给 table02(table01.10col)
启动环境
在HBase安装目录下找到jar包
hbase-server-1.2.1.jar
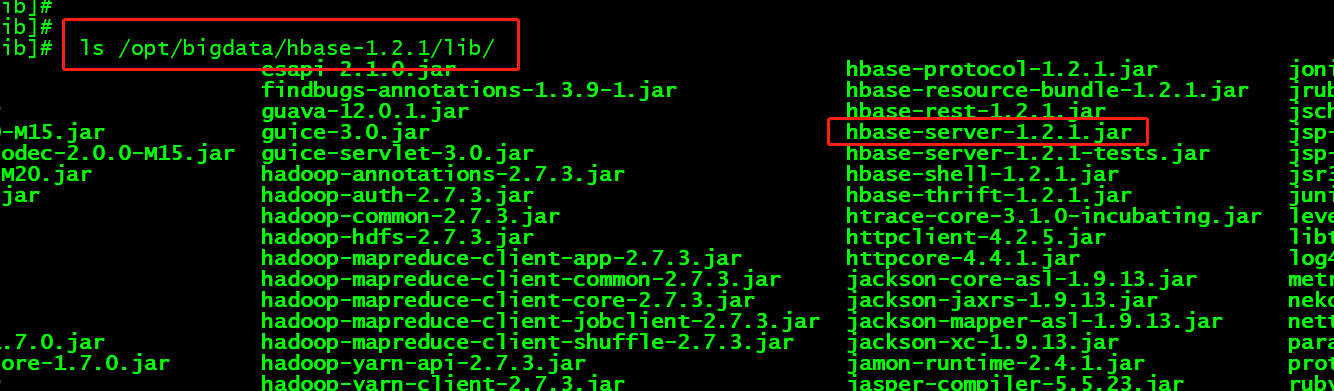
运行jar包
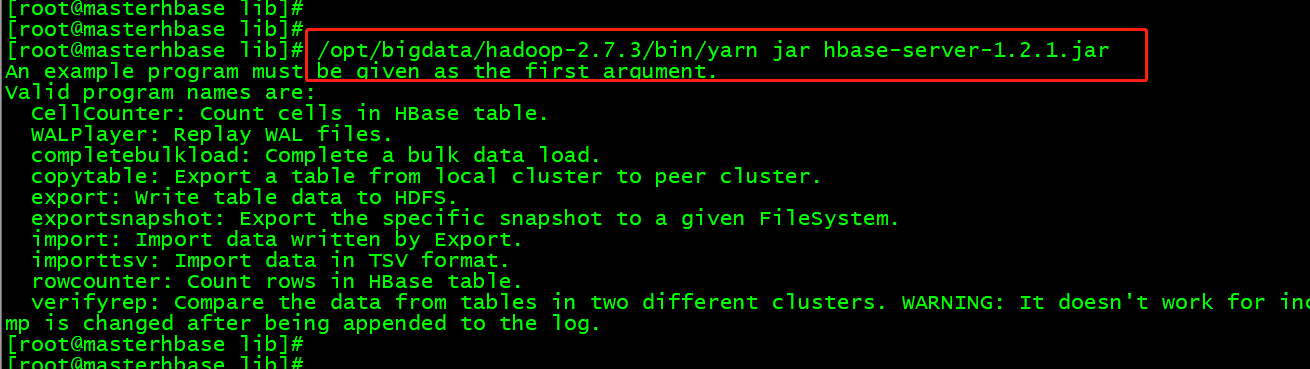
/opt/bigdata/hadoop-2.7.3/bin/yarn jar hbase-server-1.2.1.jar
出现问题
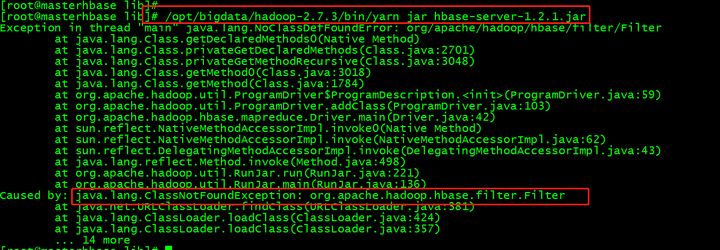
缺少hbase相关的jar包,因为命令是hadoop命令去运行hbase的jar包。
解决方案有两个
- 将所有的hbase的jar包放到Hadoop运行环境变量中,
配置环境变量
HBASE_HOME、HADOOOP_HOME、HADOOP_CLASSPATH
其中HADOOP_CLASSPATH默认加载的是share/hadoop下的所有jar包的依赖,这种方式,可能会产生jar包冲突的情况
2、将Hadoop需要的hbase的jar包放到Hadoop运行环境变量中
运行bin/hbase mapredcp查看jar包,cp不是copy的意思,是classpath的意思,包含了hbase的jar包地址,需要将这些添加到classpath中。
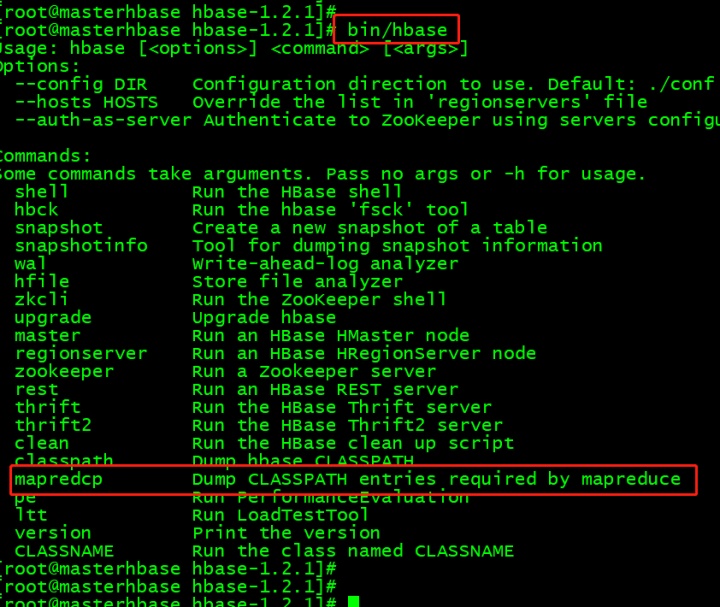
所需要的jar包支持

声明环境变量可以在hadoop-env.sh中(需要重启),也可以永久生成到/etc/profile
我们选择/etc/profile
添加以下内容
export HBASE_HOME=/opt/bigdata/hbase-1.2.1
export
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:`$HBASE_HOME/bin/hbase mapredcp`

配置生效
source /etc/profile

再执行之前的命令,就不会报错了
这里面的一些内容
CellCounter: 统计有多少cell
completebulkload: 将hfile的文件数据加载
copytable: 从一个集群中拷贝到另一个集群中
export: 将表导出到HDFS
import: Import data written by Export.
importtsv: 导入一个tsv的文件数据
rowcounter: 统计rowkey
verifyrep:比较两个不同集群中的表的数据
这是目前的表
有7行
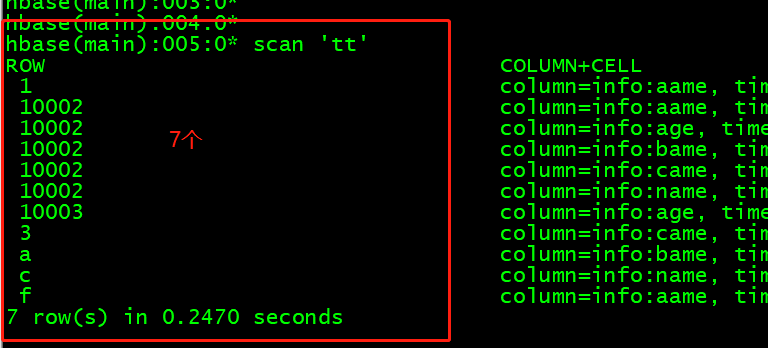
使用下命令统计rowkey
/opt/bigdata/hadoop-2.7.3/bin/yarn jar hbase-server-1.2.1.jar rowcounter tt

运行成功
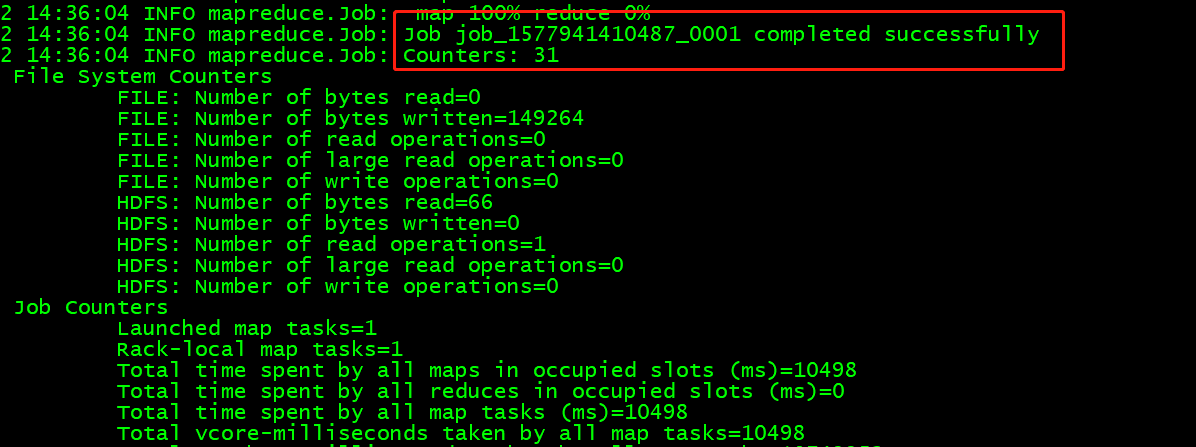
结果显示出来了
org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters
ROWS=7

我们现在设定一个需求:
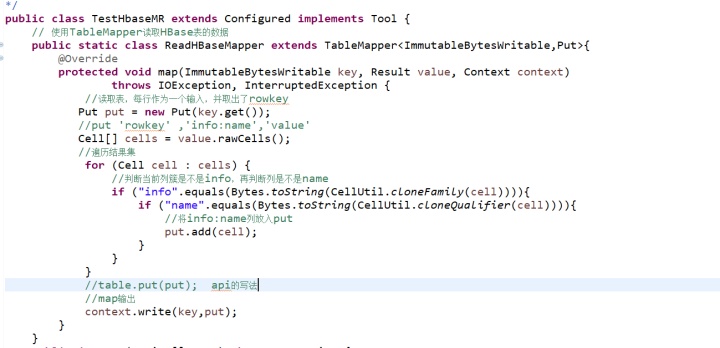
将所有info列簇中的所有name这列导入到另一张表中去
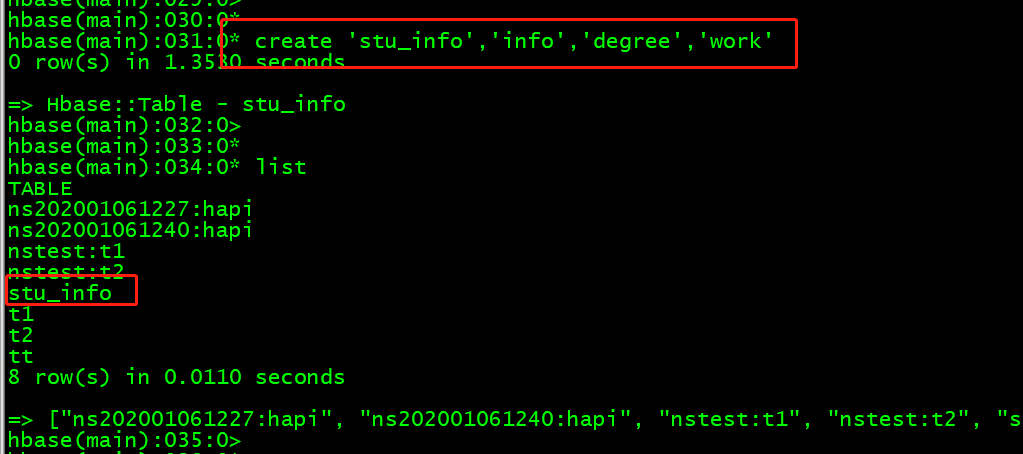
首先建表,读取的表:
create 'stu_info','info','degree','work'
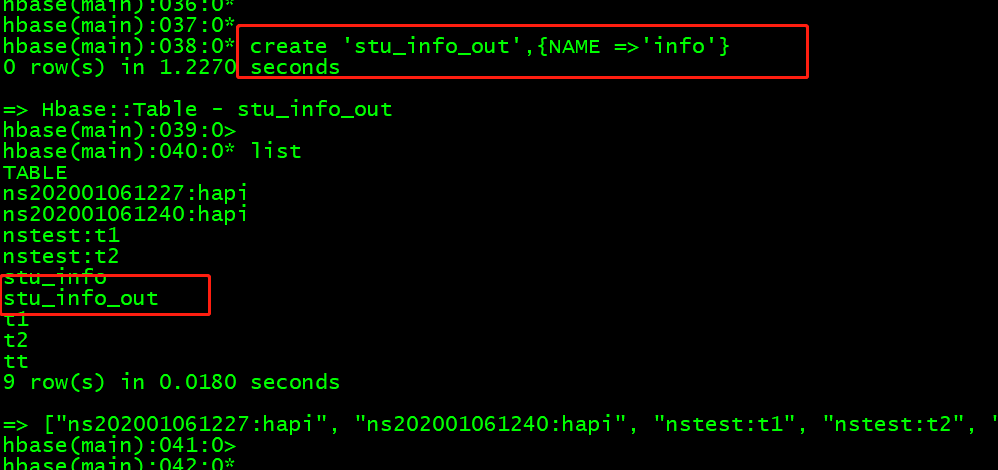
写入的表:
create 'stu_info_out',{NAME =>'info'}
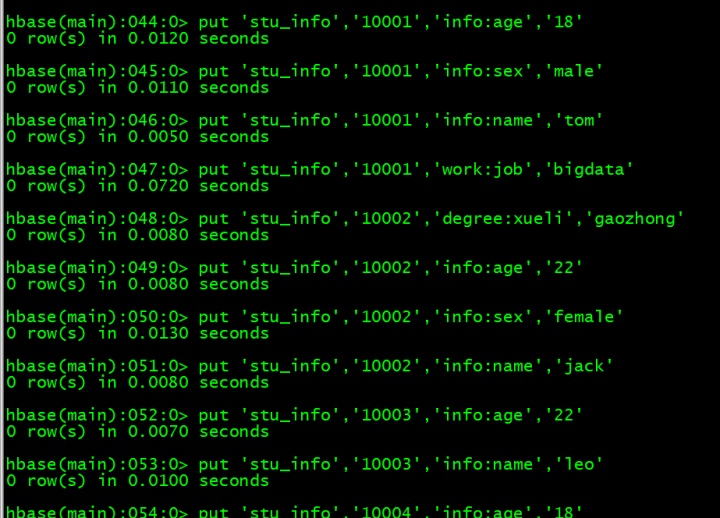
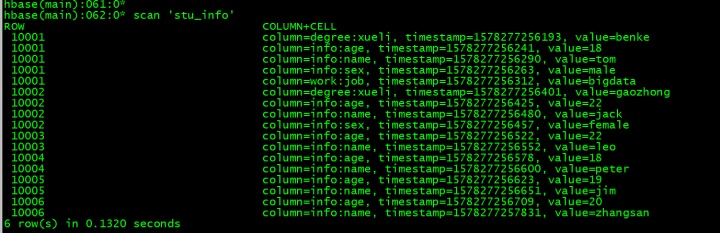
插入准备的数据
put 'stu_info','10001','degree:xueli','benke'
put 'stu_info','10001','info:age','18'
put 'stu_info','10001','info:sex','male'
put 'stu_info','10001','info:name','tom'
put 'stu_info','10001','work:job','bigdata'
put 'stu_info','10002','degree:xueli','gaozhong'
put 'stu_info','10002','info:age','22'
put 'stu_info','10002','info:sex','female'
put 'stu_info','10002','info:name','jack'
put 'stu_info','10003','info:age','22'
put 'stu_info','10003','info:name','leo'
put 'stu_info','10004','info:age','18'
put 'stu_info','10004','info:name','peter'
put 'stu_info','10005','info:age','19'
put 'stu_info','10005','info:name','jim'
put 'stu_info','10006','info:age','20'
put 'stu_info','10006','info:name','zhangsan'
查看下数据是不是插入成功了
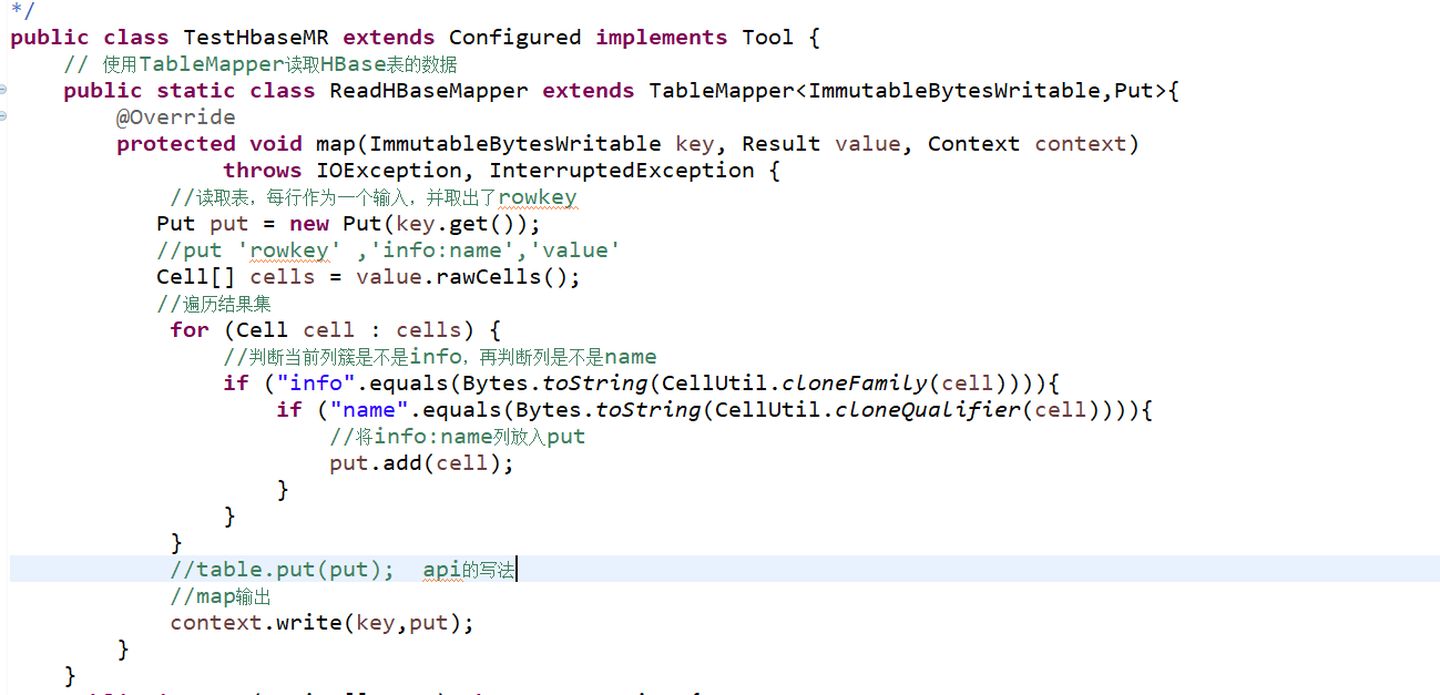
创建一个类
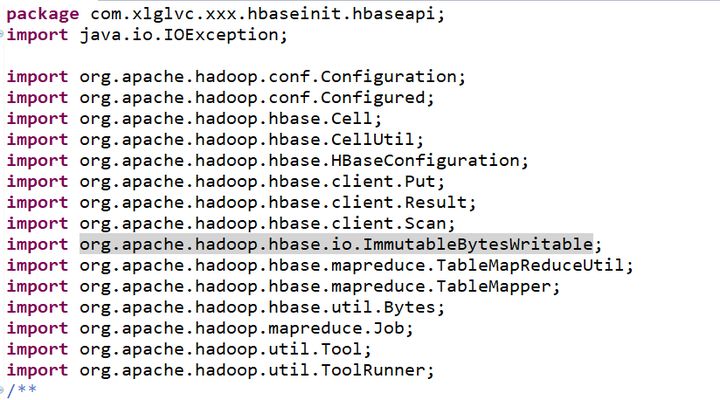
编写代码
导入的包
Map方法
Run方法

Main方法

运行代码
查看数据,已经导入了


















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









