






这里提出了一种新颖的方案,将个性化先验知识注入到每个客户端收到的全局知识中,缓解联邦学习中本地训练先验信息不完整的问题。该方法在 5 个数据集上达到了最先进的性能,并且在 8 个基准测试中比其他方法平均高出至少1.29%,在其中较困难数据集上平均准确度至少高出3.02%。广泛的分析验证了所提出设计的必要性和鲁棒性。给模型注入个性先验知识,重新激活联邦学习中被忽视的信息
经典的联邦学习(FL)可以在不收集数据的情况下训练机器学习模型,以在减小通讯需求的同时保护隐私。数据异构性是 FL 的基本特征,会导致多次本地训练带来的客户端漂移以及训练和本地实际测试数据分布不一致(数据漂移)等挑战。个性化联邦学习(Personalized FL)通过在本地数据上进行训练,在全局训练的过程中或完成后,产生个性化模型并以之测试,从而缓解或解决这一问题。
论文链接:https://arxiv.org/pdf/2310.09183.pdf
代码链接:https://github.com/BDeMo/pFedBreD_public
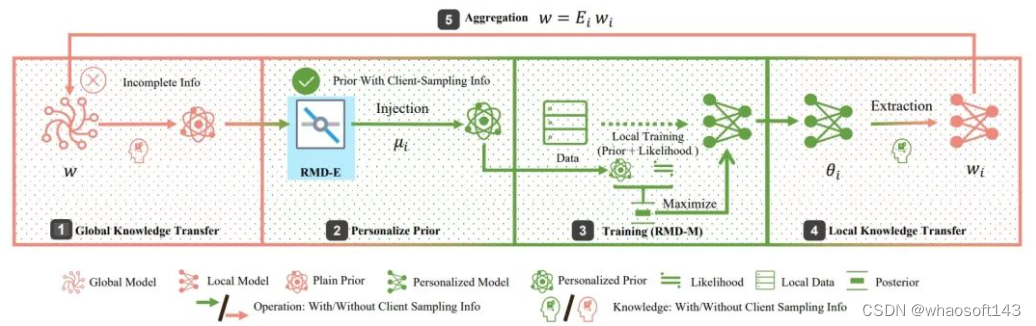
传统(个性化)联邦学习中,每个全局训练周期开始时,每次本地训练的先验知识通过全局模型传输,以获取总体数据的最新信息。而通过同一个全局模型传输的先验信息并没有量身定制给每个客户端,造成了每次本地训练要重获这部分互信息,即,客户端采样发生后并没有对先验知识的传输产生影响。我们将其称为OIP(Overlooked Information Problem),并提出了正式的问题定义。我们考虑直接注入缺失的部分互信息到先验中,以一定程度上缓解OIP带来的影响,特别是在难学习到的表征和困难数据集上,使得保留全局知识的同时加速个性化训练。
OIP的正式定义:

问题建模
我们首先需要对全局问题进行分析、解耦,并设计策略以注入本地信息,从而缓解先验信息传输中的OIP带来的负面影响。本工作中,我们通过如下主要假设,从全局问题中分离出先验信息部分、全局信息推断、本地信息推断,得到“全局极大似然估计 & 本地极大后验估计”(Global MLE & Local MAP)的新PFL模型,全局问题和本地问题求解过程中,通过知识传递参数和模型聚合,进行本地模型和全局模型之间的相互知识传递。
主要假设
先验信息假设:

上式可以重新整理为,混合似然(推断模型本地学到的似然+显式假设的似然),本地参数先验【直觉上地,分别对应:(本地知识推断+全局知识推断)、先验知识】。假设后验分布概率有两个好处:相比于直接假设先验分布概率,多出了一部分,显式假设的似然,也即全局知识推断的部分;结合指数族分布,我们能得到一个有非常好计算性质,同时涵盖面非常广的一般正则项,布雷格曼散度(Bregman Divergence,B-Div)正则项。
完全信息参数假设:
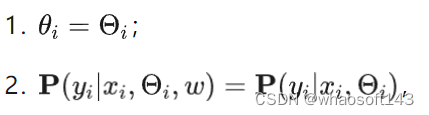
本地参数包含本地推断需要的所有信息,即,本地只用个性化模型做推断,而不是全局模型。
新PFL模型Global MLE & Local MAP——(pFedBreD, Personalized Federated Learning with Bregman Divergence)
全局问题:

一次迭代过程简述为:
- 全局模型发送给本地训练提供全局知识;
- 根据提供的全局知识构造个性化先验;
- 通过任意最优化方法求解本地问题;
- 从本地训练后得到的个性化模型中提取本地信息,并聚合本地模型得到新的全局模型。
全局问题求解算法为一阶算法,其中

个性化先验策略设计——松弛化镜像梯度下降(RMD,Relaxed Mirror Descent)
我们通过对如下镜像梯度下降的一般迭代形式进行松弛化:

其三者分别表示基于本地似然损失的、基于本地问题的、基于混合信息的一阶MAML策略。
收敛性分析
我们在Global MLE & Local MAP框架下,对大部分基于正则(例如,L2,KL)的本地训练方法提供了一个线性的以及无聚合噪声下的情况下的二次加速的收敛上界。除开常规的最终收敛半径和指数项,以下将分全局聚合噪声有无的两种情况讨论:

实验
对比实验
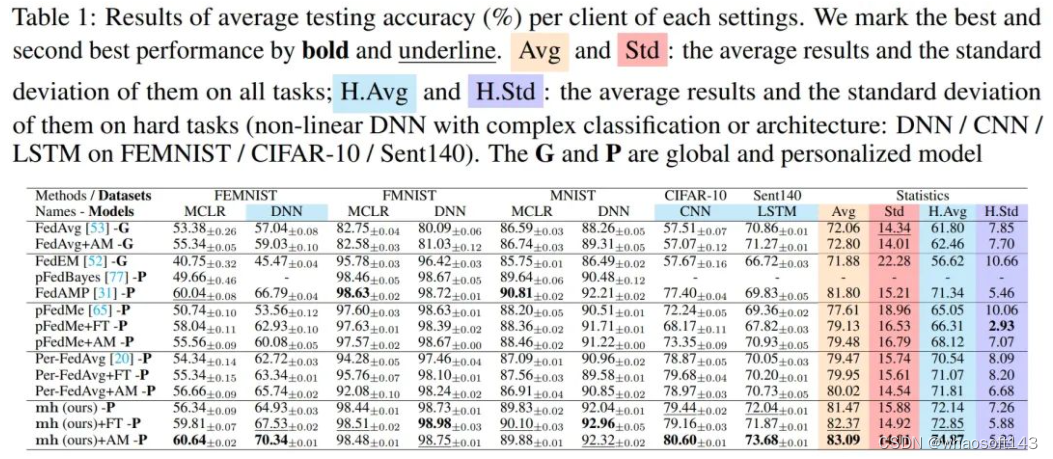
上图为8个setting,5个数据集上的结果
主要对比了:凸/非凸任务上、简单/复杂数据集上、CV/文本数据集上,本方法与其他方法的表现,Baselines主要包含:经典方法FedAvg、EM-based方法FedEM、贝叶斯个性化方法pFedBayes、多任务算法FedAMP(Heur-FedAMP)、正则化方法pFedMe、元学习方法Per-FedAvg。
消融实验
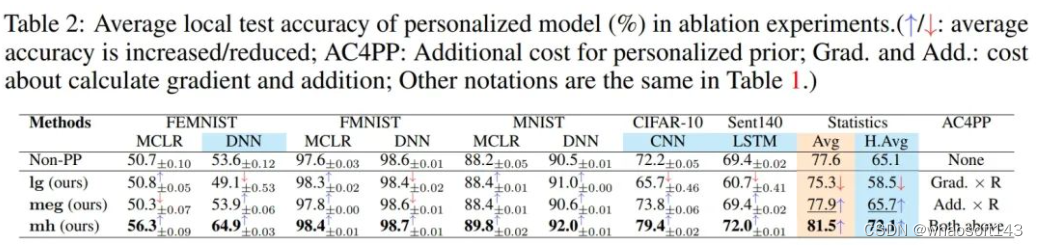
上图为对比试验数据集上的消融实验
主要摘掉了个性化先验策略的混合方法的本地似然梯度、本地包络梯度以及两者同时摘除,即退化成pFedMe【高斯先验假设的一种pFedBreD,用L2正则作为正则项。其他的方法也是pFedBreD框架下支持的方法,比如:KL正则,一些变分推断的方法】。消融实验体现了个性化先验方向的潜力,以及方法的各种信息补偿方式的有效性。
信息注入与提取验证
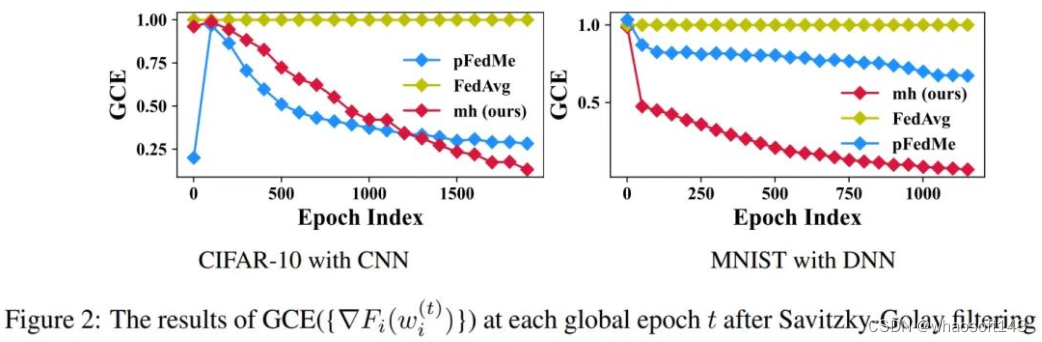
上图为广义相干性估计,经典非个性化方法,非个性化先验/个性化先验的个性化方法
本文通过对训练后的本地问题的一阶信息差异进行广义相干性估计(GCE),对信息的注入和提取验证,如果差异越大,即GCE越小,说明信息多样性越强。
鲁棒性实验
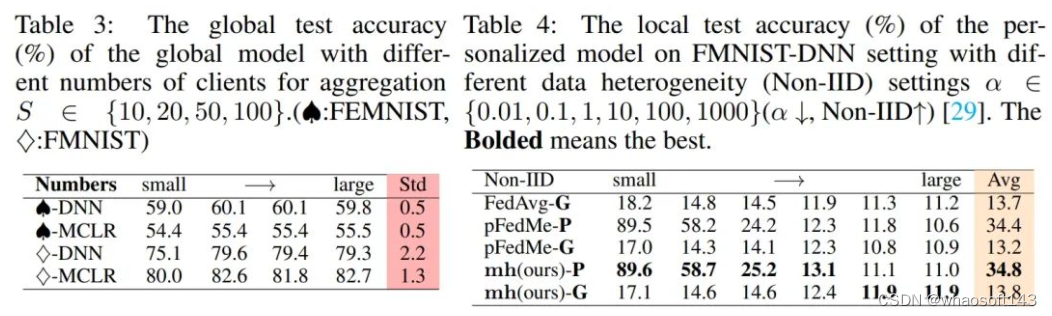
上图为关于不同聚合噪声以及数据异构性的鲁棒性实验
分别测试了在两个数据集上,不同聚合比率的结果稳定性,对比标准差非常小,表示非常稳定。分别测试了三个方法的全局模型、个性化模型在不同非独立同分布设置下的结果稳定性。
个性化实验
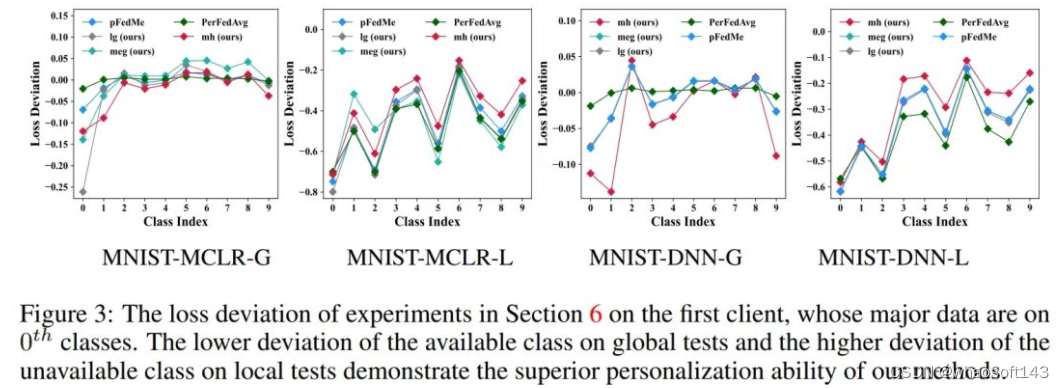
上图为损失离差对比
本问中个性化效果验证,除了之前实验的部分体现以外,我们使用不同类上的损失离差对比来验证个性化效果。G代表全局测试,即输出模型在所有数据上的测试;L代表本地测试,即输出模型在本地数据上的测试。更低的全局测试离差、更高的本地测试离差,体现了更好的个性化效果。















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









