







该文章整理翻译自http://colah.github.io/posts/2014-10-Visualizing-MNIST/
众所周知,我们人类在二维和三维上能够理性的进行思考,通过努力,我们可以从第四维来思考。但是机器学习经常要求我们使用成千上万个维度——或者数万,或者数百万!即使是非常简单的事情,当你在非常高的维度上做的时候,也会变得难以理解。
这时,就需要一些工具的辅助。高手已经建立了工具来帮助我们。有一个完整的、发展良好的领域,称为降维,它实现了将高维数据转换成低维数据的技术。关于高维数据可视化的相关课题也做了大量工作。
这些技术就是我们需要的基本构建块,特别是如果我们希望进行可视化机器学习和深入学习。
通过可视化和更直接地观察实际发生的事情,我们可以更深入、更直接地理解神经网络。
因此,我们的首要任务是熟悉降维。要做到这一点,我们需要一个数据集来测试这些技术。
1. MNIST
MNIST是一种简单的计算机视觉数据集。它由28×28像素的手写数字图像组成,如:

每一个MNIST数据点,每一个图像,都可以被看作是一个数字数组,将每一个像素填充为黑色,如
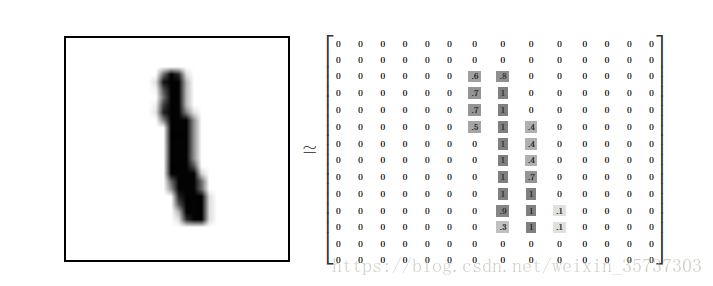
由于每个图像都有28×28个像素,所以我们得到了一个28×28的数组。我们可以将每个数组变为28×28=784维向量。矢量的每个分量是介于0和1之间的值,描述像素的强度。因此,我们通常认为MNIST是784维向量的集合。
并不是所有784维空间中的所有向量都是MNIST数据。这个空间的典型点是非常不同的!为了对一个典型点有点感觉,我们可以随机挑选几个点,并检查
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









