






本文通过一个图像分类模型为实例,引导您一步步完成在 Apache Spark 上利用 DJL 在大数据生产环境中部署 TensorFlow,PyTorch,以及 MXNet 等模型。
前言
深度学习在大数据领域上的应用日趋广泛,可是在 Java/Scala 上的部署方案却屈指可数。亚马逊开源项目团队另辟蹊径,利用 DJL 帮助用户部署深度学习应用在 Spark 上。只需10分钟,你就可以轻松部署 TensorFlow,PyTorch,以及 MXNet 的模型在大数据生产环境中。
Apache Spark 是一个优秀的大数据处理工具。在机器学习领域,Spark 可以用于对数据分类,预测需求以及进行个性化推荐。虽然 Spark 支持多种语言,但是大部分 Spark 任务设定及部署还是通过 Scala 来完成的。尽管如此,Scala 并没有很好的支持深度学习平台。大部分的深度学习应用都部署在 Python 以及相关的框架之上,造成 Scala 开发者一个很头痛的问题:到底是全用Python写整套 spark 架构呢,还是说用 Scala 包装 Python code 在 pipeline 里面跑。这两个方案都会增加工作量和维护成本。而且,目前看来,PySpark 在深度学习多进程的支持上性能不如Scala的多线程,导致许多深度学习应用速度都卡在了这里。
今天,我们会展示給用户一个新的解决方案,直接使用 Scala 调用 Deep Java Library (DJL)来实现深度学习应用部署。DJL 将充分释放Spark强大的多线程处理性能,轻松提速2-5倍*现有的推理任务。DJL 是一个为 Spark 量身定制的 Java 深度学习库。它不受限于引擎,用户可以轻松的将 PyTorch, TensorFlow 以及MXNet的模型部署在 Spark 上。在本 blog 中,我们通过使用 DJL 来完成一个图片分类模型的部署任务,你也可以在这里参阅完整的代码。
图像分类:DJL + Spark
我们将使用 Resnet50的预训练图像分类模型来部署一个推理任务。为了简化配置流程,我们只会在本地设置单一 cluster 与多个虚拟 worker node 的形式来进行推理。这是大致的工作流程:
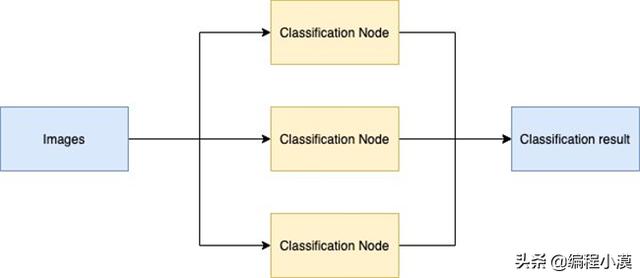
Spark 会产生多个 Executor 来开启每个 JVM 进程,然后每一个处理任务(task) 都会发送給 Executor 执行。每一个 Excutor 拥有独立分配的内核以及内存。具体任务执行将会完全使用多线程来执行。在大数据处理中,这种架构可以帮助每个 worker 分配到合理的数据量。
第一步 建立一个Spark项目
通过使用 sbt,我们可以轻松构建 Scala 项目。想了解更多关于 sbt 的介绍,请参考这里。可以通过下面的模板轻松设定:
name := "sparkExample"version := "0.1"// DJL要求JVM 1.8及以上scalaVersion := "2.11.12"scalacOptions += "-target:jvm-1.8"resolvers += Resolver.mavenLocallibraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"libraryDependencies += "ai.djl" % "api" % "0.5.0"libraryDependencies += "ai.djl" % "repository" % "0.5.0"// 使用MXNet引擎libraryDependencies += "ai.djl.mxnet" % "mxnet-model-zoo" % "0.5.0"libraryDependencies += "ai.djl.mxnet" % "mxnet-native-auto" % "1.6.0"项目使用 MXNet 作为默认引擎。你可以通过修改下面两行来更换使用 PyTorch:
// 使用PyTorch引擎libraryDependencies += "ai.djl.pytorch" % "pytorch-model-zoo" % "0.5.0"libraryDependencies += "ai.djl.pytorch" % "pytorch-native-auto" % "1.5.0"第二步 配置 Spark
我们使用下面的配置在本地运行 Spark:
// Spark 设置val conf = new SparkConf() .setAppName("图片分类任务") .setMaster("local[*]") .setExecutorEnv("MXNET_ENGINE_TYPE", "NaiveEngine")val sc = new SparkContext(conf)MXNet 多线程需要设置额外的 NaiveEngine 环境变量。如果使用 PyTorch 或者 TensorFlow,这一行可以删除:
.setExecutorEnv("MXNET_ENGINE_TYPE", "NaiveEngine")第三步 设置输入数据
输入数据是一个内含多张图片的文件夹。Spark 会把这些图片读入然后分成不同的 partition。每个 partition 会被分发给不同的 Executor。那么我们配置一下图片分发的过程:
val partitions = sc.binaryFiles("images/*")第四步 设置 Spark job
在这一步,我们将创建一个 Spark 计算图用于进行模型读取以及推理。由于每一张图片推理都会在多线程下完成,我们需要在进行推理前设置一下 Executor:
// 开始分发任务到 worker 节点val result = partitions.mapPartitions( partition => { // 准备深度学习模型:建立一个筛选器 val criteria = Criteria.builder // 图片分类模型 .optApplication(Application.CV.IMAGE_CLASSIFICATION) .setTypes(classOf[BufferedImage], classOf[Classifications]) .optFilter("dataset", "imagenet") // resnet50设置 .optFilter("layers", "50") .optProgress(new ProgressBar) .build val model = ModelZoo.loadModel(criteria) // 建立predictor val predictor = model.newPredictor() // 多线程推理 partition.map(streamData => { val img = ImageIO.read(streamData._2.open()) predictor.predict(img).toString })})DJL 引入了一个叫做ModelZoo的概念,通过 Criteria 来设置读取的模型。然后在 partition 内创建 Predictor。在图片分类的过程中,我们从 RDD 中读取图片然后进行推理。这次使用的 Resnet50 模型是经过ImageNet数据集预训练的模型。
第五步 设置输出
当我们完成了 Map 数据的过程,我们需要让 Master 主节点收集数据:
// 打印推理的结果result.collect().foreach(print)// 存储到output文件夹result.saveAsTextFile("output")运行上述两行代码会驱动 Spark 开启任务,输出的文件会保存在 output 文件夹. 请参阅 Scala example 来运行完整的代码。
如果你运行了示例代码,这个是输出的结果:
[ class: "n02085936 Maltese dog, Maltese terrier, Maltese", probability: 0.81445 class: "n02096437 Dandie Dinmont, Dandie Dinmont terrier", probability: 0.08678 class: "n02098286 West Highland white terrier", probability: 0.03561 class: "n02113624 toy poodle", probability: 0.01261 class: "n02113712 miniature poodle", probability: 0.01200][ class: "n02123045 tabby, tabby cat", probability: 0.52391 class: "n02123394 Persian cat", probability: 0.24143 class: "n02123159 tiger cat", probability: 0.05892 class: "n02124075 Egyptian cat", probability: 0.04563 class: "n03942813 ping-pong ball", probability: 0.01164][ class: "n03770679 minivan", probability: 0.95839 class: "n02814533 beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon", probability: 0.01674 class: "n03769881 minibus", probability: 0.00610 class: "n03594945 jeep, landrover", probability: 0.00448 class: "n03977966 police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria", probability: 0.00278]生产环境配置的建议
在这个例子里,我们用了 RDD 来进行任务分配,这个只是为了方便展示。如果考虑到性能因素,建议使用 DataFrame 来作为数据的载体。从 Spark 3.0开始,Apache Spark 为 DataFrame 提供了 binary 文件读取功能。这样在未来图片读取存储将会易如反掌。
工业环境中 DJL 在 Spark 上的应用
Amazon Retail System (ARS) 通过使用 DJL 在 Spark 上运行了数以百万的大规模数据流推理任务。这些推理的结果用于推断用户对于不同操作的倾向,比如是否会购买这个商品,或者是否会添加商品到购物车等等。数以千计的用户倾向类别可以帮助 Amazon 更好的推送相关的广告到用户的客户端与主页。ARS 的深度学习模型使用了数以千计的特征应用在几亿用户上,输入的数据的总量达到了1000亿。在庞大的数据集下,由于使用了基于 Scala 的 Spark 处理平台,他们曾经一直在为没有好的解决方案而困扰。在使用了 DJL 之后,他们的深度学习任务轻松的集成在了 Spark 上。推理时间从过去的很多天变成了只需几小时。我们在之后将推出另一篇文章来深度解析 ARS 使用的深度学习模型,以及 DJL 在其中的应用。
关于 DJL
DJL 亚马逊云服务在2019年 re:Invent 大会推出的专为 Java 开发者量身定制的深度学习框架,现已运行在亚马逊数以百万的推理任务中。如果要总结 DJL 的主要特色,那么就是如下三点:
- DJL不设限制于后端引擎:用户可以轻松的使用 MXNet, PyTorch, TensorFlow 和 fastText 来自 Java 上做模型训练和推理。
- DJL 的算子设计无限趋近于 numpy:它的使用体验 numpy 基本是无缝的,切换引擎也不会造成结果改变。
- DJL 优秀的内存管理以及效率机制:DJL 拥有自己的资源回收机制,100个小时连续推理也不会内存溢出。















 2330
2330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









