








转载自AWS China: 深度解析 Amazon Retail System 用户倾向预测模型以及使用 DJL 在 Apache Spark 进行深度学习推理任务
前言
如今,越来越多的公司正在为用户量身定制内容并产生个性化推荐。例如商家个性化产品推荐以及促销活动。为了产生最好的产品内容,我们首先需要推测用户的下一步动作。比如,用户会通过浏览一个商品并将其添加进购物车。如果我们在此时此刻推送此类商品的促销信息,那么用户会更有更大概率去购买商品。通过对于用户过去的行为以及喜好,我们可以推断出用户在未来潜在的行为倾向从而产生更好的个性化内容( 例如:邮件推送,广告)。
在亚马逊,我们使用Apache MXNet构造了一个多标签分类模型用于在数千类别里预测用户倾向。通过预测的结果,我们可以创造一种个性化的内容,帮助用户去选择最好的商品。这个文章将通过准备数据,模型构造和模型部署三个步骤来介绍在构造模型中我们遇到的各种挑战以及使用Deep Java Library (DJL) 在Apache Spark上进行大规模的深度学习推理任务。因为使用的工具完全开源,你也可以尝试去构建类似的应用。
准备数据
我们需要准备两组数据用于训练,分别是输入数据和标记数据。
输入数据
无论构建什么样的机器学习模型,其中一个很重要的部分就是输入数据。我们在这个模型中选择了多标记分类模型,这样做的好处是我们无需构建多个Pipeline(管道),只需要一个就可以进行推理任务。这个数据管道采集了来自于多个分类中用户的表现,然后通过这些信息,我们可以推断用户下一步在这些分类中的行为倾向。相比于构造大量的binary分类器,这种单模型多标记的设计减少了维护成本。
然后我们开始准备输入数据。我们为几亿亚马逊用户创建了几十万维度的特征向量,因为数据相对稀疏,我们使用了稀疏矩阵的形式来构造我们的输入数据:
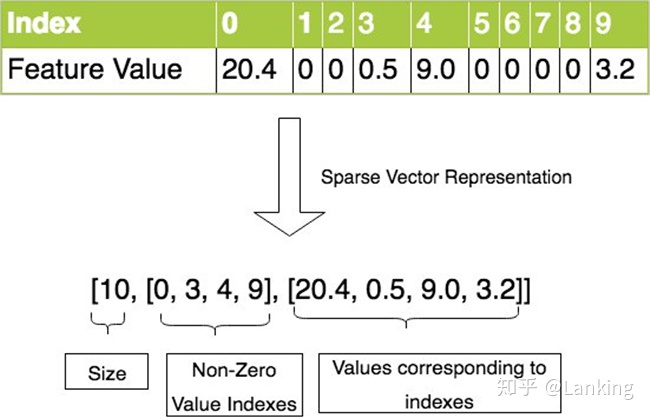
上图展示了一个稀疏矩阵的表达类型。通过给出数据大小,数据内容和对应的坐标,我们可以构建出一个稀疏矩阵。相比于密集矩阵,稀疏矩阵可以帮助节约内存以及加快推理的速度。
标记数据
这个倾向模型将会判断用户对于一个类别的选择,在不同的地区这些类别的内容也不尽相同。对于每一个地区而言,我们都有几千种类别。每一个类别都使用简单的0或者1表达。1表示用户进行了这个类别的行为,0则反之。这些过去行为的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









