





分析师:Kung Fu
近年来,在线课程凭借便捷的网络变得越来越流行。为了有更好的用户体验,在线课程平台想要给用户推荐他们所感兴趣的课程,以便增大点击率和用户黏性。
解决方案
任务/目标
根据学生所选的历史课程,预测出学生接下来可能选择的课程。
数据源准备
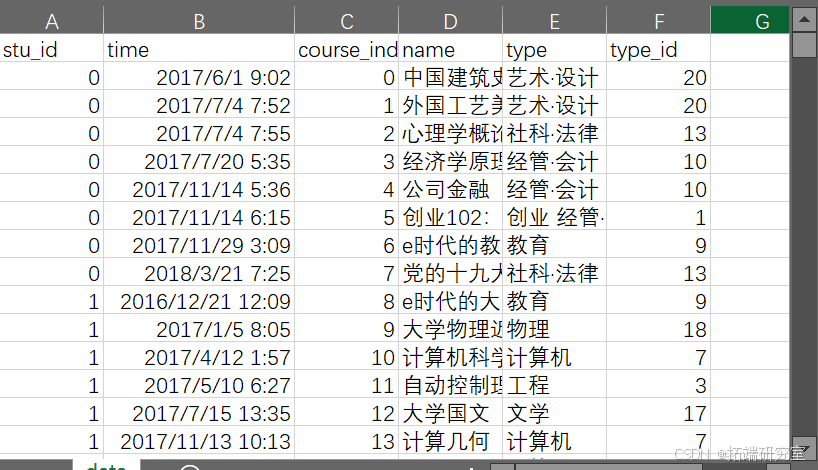
数据说明:
stu_id:学员证。
时间:学生首次报名相应课程的时间。
course_index:课程 ID。
名称:课程名称。
类型:课程的类型。
type_id:类型 id。
构造
这个是我所用到的数据集。在所给的数据特征中,我们需要用到的是学生的ID和课程的ID,每个学生所选的课已经按照时间顺序排列好了。
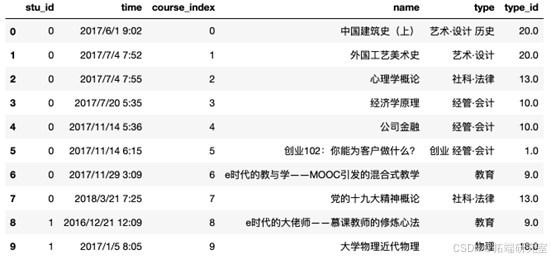
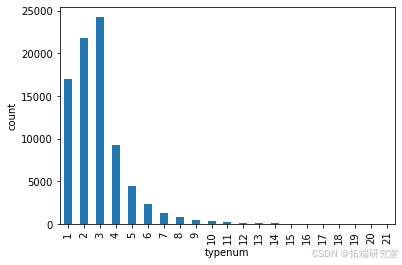
用户选择的课程的分布
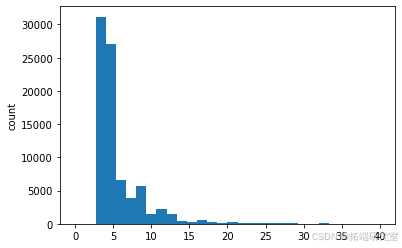
用户选择的类型的分布
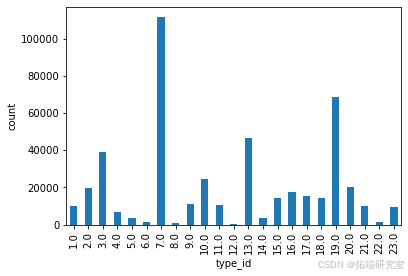
用户选择的类型的分布
划分训练集和测试集和评价指标
我们是这样划分训练集和测试集的,把每个学生选的最后一门课作为测试集,剩下的课程作为训练集。Hit rate@10(推荐10门课程的命中率)和NDCG@10(推荐10门课程的归一化折损累计增益)是我们对模型的评价指标。Hit rate是指训练集是否在推荐的10门课程里,NDCG则是更关注推荐的课程在10门课程当中的具体位置,越是靠前,NDCG越大。
建模
非个性化推荐模型
这个模型是我们的baseline,采用非个性化的方式,也就是说,所有学生会收到一样的课程推荐,在这里,推荐的课程是基于课程的受欢迎程度,我们挑选出最受欢迎的10门课推荐给所有学生。
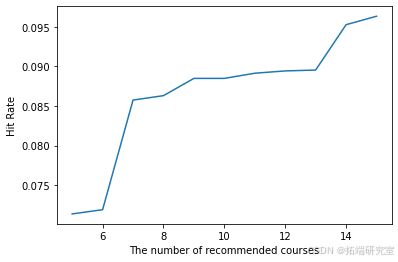
计算并绘制命中率与推荐课程数量的关系
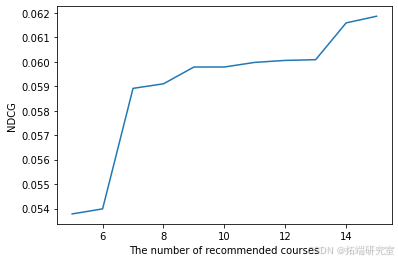
计算并绘制 NDCG 与推荐课程数量的关系
贝叶斯个性化排序推荐模型
在这个算法中,我们将任意学生所选的课进行标记,如果一个用户u在选择j课程之前选择了i课程,我们得到一个三元组<u,i,j>,说明u更喜欢i。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。然后这个算法基于矩阵分解的方式得到用户对于不同课程的排序,选出前10名。
创建稀疏学生-课程交互矩阵
将日期拆分为训练集和测试集
通过删除每个学生的一些交互,将学生与课程交互矩阵拆分为训练集和测试集,并假装我们从未见过它们
构造 BPR 类
贝叶斯个性化排名(BPR)来源于个性化排名,为用户提供排名项目列表的项目推荐。排名项目列表是根据用户的隐式行为计算得出的。BPR 基于矩阵分解。所选课程可以看作是正数据集,而其余课程可以是负值和缺失值的混合体。通常,课程推荐人会输出个性化分数Xin和𝑋你我(u 是学生,我是课程)基于学生对课程的偏好,课程从预测分数中排序。课程推荐器的机器学习模型通过给出对(u、i)来提供训练数据∈∈S 作为正类标签和 (U × I) 中的所有其他组合∖∖S 为负数。在这里,所有负用户-课程对都替换为 0。
基于自注意力的序列推荐模型
利用transformer中的self-attention机制,将其应用到序列推荐模型中。序列推荐聚焦于根据用户t时刻的交互序列进行建模,预测用户t+1时刻的交互。
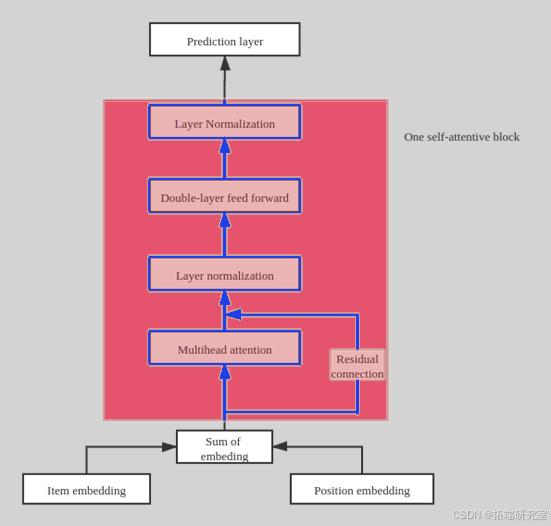
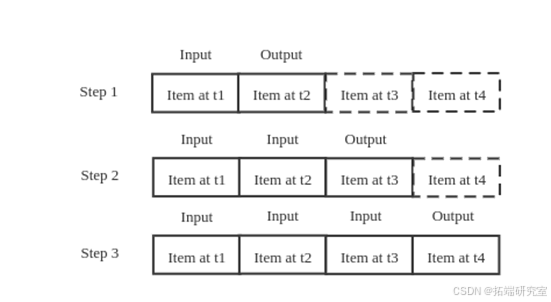
在这个项目中,我们利用神经网络,一步步按照时间往下训练,神经网络的结构如上图所示。训练过程如下图所示
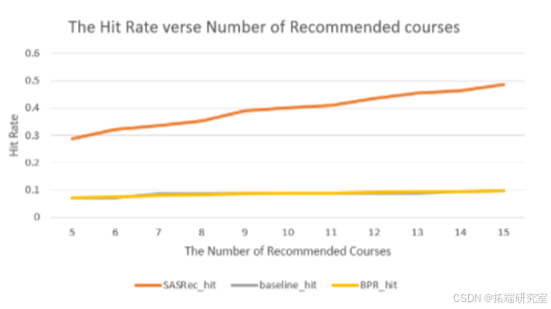
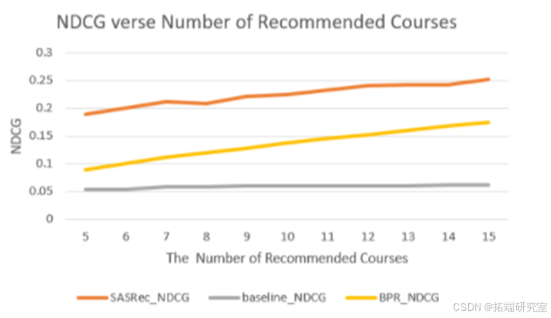
在这个项目中,无论是从hit rate还是NDCG,基于自注意力序列推荐模型的表现最好。在hit rate的比较上,非个性化推荐和贝叶斯个性化排序推荐表现类似,但贝叶斯个性化排序推荐在NDCG这个指标上表现更好一点。贝叶斯个性化排序推荐的这个办法的不足之处在于它不能很好的捕捉到输入中的时间序列信息,我们做过测试,如果不选最后一门作为测试集而是在所有选过的课程中随机选择一门,贝叶斯个性化排序推荐的推荐表现会更好。而自注意力序列推荐模型就是充分利用了输入的时间序列信息,从而才会预测的更好。
关于分析师

在此对Kung Fu对本文所作的贡献表示诚挚感谢,他毕业于洛桑联邦理工学院,专注深度学习领域。擅长Python。
















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









