







简介:JetBrains提供的集成开发环境如IntelliJ IDEA、PHPStorm、WebStorm、PyCharm和CLion等支持强大的正则表达式功能,使开发者能够高效地在代码中执行复杂的查找和替换操作。本资源旨在介绍如何利用正则表达式在JetBrains IDEs中进行高效的文本处理,包括启用正则表达式模式、使用基础匹配和量词、创建分组与引用、运用选择与否定、预查与后顾、边界匹配、转义字符、查找和替换、多行模式、调试与测试、预览和高亮显示匹配项,以及调整正则表达式选项等技巧。熟练掌握这些技术能够帮助开发者提升编码效率,优化代码质量。 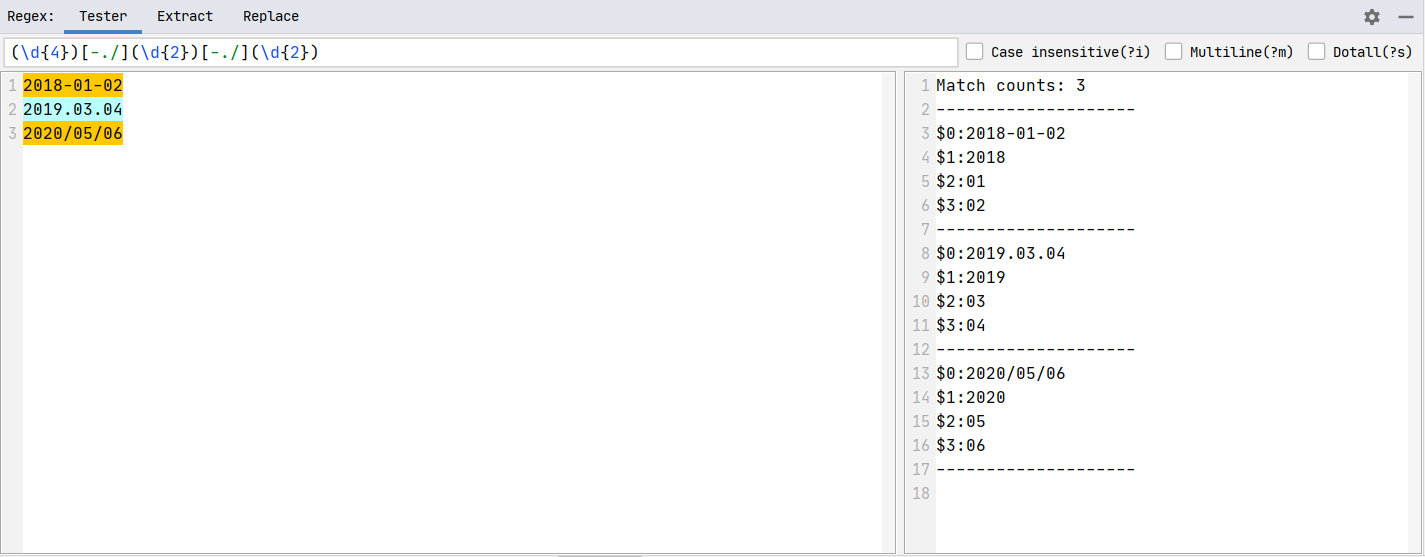
1. JetBrains IDEs正则表达式基础
正则表达式是处理文本和数据的强大工具,它提供了一种灵活的方式来进行字符串的查找、匹配和替换。在JetBrains开发的集成开发环境(IDEs)中,正则表达式被广泛应用于代码审查、重构及自动化文本处理等多个方面。掌握正则表达式的基础知识对于提升开发效率和代码质量至关重要。本章将为读者介绍正则表达式的概念,并逐步引导你理解在JetBrains IDEs中如何启动和使用这一功能。我们将从正则表达式的简单匹配开始,逐步深入到更复杂的模式匹配技巧,以及如何在代码编辑器中运用这些表达式进行高效的文本操作。让我们开始探索这一神奇的世界吧!
2. 启用正则表达式功能与基础匹配技巧
在日常的软件开发、数据分析或文本处理中,正则表达式扮演了至关重要的角色。掌握正则表达式,可以极大地提升处理字符串的效率和灵活性。本章将详细介绍如何在JetBrains IDEs中启用正则表达式功能,并分享一些基础匹配技巧。
2.1 启用正则表达式功能
2.1.1 在不同IDE中启用正则表达式选项
在使用JetBrains系列IDE(如IntelliJ IDEA, PyCharm, WebStorm等)进行代码开发或数据处理时,启用正则表达式选项可以帮助我们快速匹配特定模式的字符串。
步骤如下:
- 打开JetBrains IDE。
- 转到 "Edit" > "Find" > "Find..." (或使用快捷键Ctrl + F),打开查找面板。
- 在查找框下方的选项中找到 "Regex"(或类似的选项)并勾选。
- 此时,你可以输入正则表达式来执行搜索。
通过以上简单的步骤,你就可以在JetBrains IDE中启用正则表达式功能了。值得注意的是,不同的IDE可能会在查找面板的布局和选项名称上有所差异,但基本功能和操作逻辑是类似的。
2.1.2 正则表达式功能的快速访问方法
除了通过查找面板的选项启用正则表达式功能外,JetBrains IDEs还提供了快速访问方式,让你在任何编辑器窗口中快速切换正则表达式的搜索模式。
快捷访问步骤:
- 按住Alt键,然后点击查找框旁边的 ".*" 图标,即可快速切换到正则表达式模式。
- 按住Alt键,然后点击查找框旁边的 ".*" 图标旁边的小三角,可以选择特定的正则表达式选项,如大小写敏感、全字匹配等。
2.2 正则表达式基础匹配技巧
一旦启用了正则表达式功能,便可以利用其强大的匹配能力进行各种文本操作。本节将介绍一些基础的正则表达式语法,为之后的高级技巧打下基础。
2.2.1 常用的正则表达式语法
- 点号(
.): 匹配除换行符之外的任意单个字符。例如,正则表达式c.t可以匹配 "cat", "cot", "czt" 等。 - 星号(
*): 表示前面的字符可以出现零次或多次。例如,正则表达式ca*t可以匹配 "ct", "cat", "caaat" 等。 - 加号(
+): 表示前面的字符可以出现一次或多次。例如,正则表达式ca+t可以匹配 "cat", "caaat",但不能匹配 "ct"。 - 问号(
?): 表示前面的字符可以出现零次或一次。例如,正则表达式colou?r可以匹配 "color" 或 "colour"。 - 方括号(
[]): 用于指定字符集合。例如,正则表达式[abc]可以匹配 "a", "b", "c" 中的任意一个字符。 - 花括号(
{}): 用于指定前面字符的重复次数。例如,正则表达式a{3}匹配 "aaa",而a{1,3}匹配 "a", "aa", "aaa"。
正则表达式的这些基本元素是构建更复杂表达式的基石。熟练掌握它们,对于编写有效和高效的正则表达式至关重要。
2.2.2 特殊字符和转义序列的使用
在正则表达式中,有些字符具有特殊含义,例如点号( . )、星号( * )等。如果要匹配这些字符本身,需要使用反斜杠( \ )进行转义。
转义序列示例:
- 正则表达式
\.\\*可以匹配文本中的 ".*"。 - 使用
\d可以匹配任何单个数字(等同于[0-9])。 - 使用
\w可以匹配任何单词字符(字母、数字及下划线,等同于[A-Za-z0-9_])。 - 使用
\s可以匹配任何空白字符(空格、制表符等)。
理解如何转义这些特殊字符,可以避免在进行匹配时出现意外的结果,并使正则表达式更加精确。
通过本章的介绍,你已经学会了在JetBrains IDEs中启用正则表达式功能的基本操作,并掌握了正则表达式的基础匹配技巧。随着对正则表达式的进一步学习和实践,你将能够更高效地处理复杂的文本问题,并在各种编程和数据处理任务中发挥正则表达式的强大功能。接下来的章节将深入探讨正则表达式的高级技巧与实践,帮助你更加熟练地运用这一工具。
3. 高级正则表达式技巧与实践
3.1 正则表达式量词使用
3.1.1 量词的类型和应用场景
量词在正则表达式中扮演着至关重要的角色,它用来指定某个模式出现的次数。基本的量词包括:
-
*表示零次或多次出现。 -
+表示一次或多次出现。 -
?表示零次或一次出现。 -
{n}表示恰好出现n次。 -
{n,}表示至少出现n次。 -
{n,m}表示至少出现n次,但不超过m次。
量词的使用应根据实际需求,例如,如果我们想要匹配一个或多个数字,可以使用 [0-9]+ 。量词同样可以与其他正则表达式组件结合使用,例如, [a-zA-Z]+ 将会匹配一个或多个字母组成的字符串。
3.1.2 懒惰量词与贪婪量词的区别和选择
在正则表达式中,存在两种主要的量词类型:贪婪量词和懒惰量词。默认情况下,量词是贪婪的,它们尽可能多地匹配字符。例如,正则表达式 .* 在匹配字符串"abc"时,将匹配整个字符串"abc"。
懒惰量词则尽可能少地匹配字符。在量词后添加一个 ? 可以将其变为懒惰模式,如 .*? 。如果在上面的例子中使用 .*? ,则只会匹配到第一个字符"a"。
选择贪婪或懒惰量词取决于具体的应用场景和需求。在处理HTML或XML文件时,贪婪匹配可能会导致错误的结果,此时懒惰匹配则更为合适。
flowchart LR
A[开始] --> B{使用贪婪量词}
B -->|是| C[尽可能多匹配字符]
B -->|否| D[使用懒惰量词]
D --> E[尽可能少匹配字符]
C --> F[完成匹配]
E --> F
3.2 正则表达式分组与引用
3.2.1 捕获组的创建和命名
捕获组是正则表达式中用于将某部分匹配的结果保存起来的特殊构造。通过在括号内编写模式来创建捕获组,例如 (foo) 或 (bar) 。每个捕获组都会被分配一个唯一的编号,从1开始。
命名捕获组提供了一个更好的方式来标识和引用捕获的内容。它们通过 (?<name>pattern) 的形式创建,其中 name 是组的名称, pattern 是你要匹配的模式。例如, (?<year>\d{4}) 会匹配四位数年份并将它命名为 year 。
使用捕获组可以在后续的匹配中引用之前保存的结果,这在处理复杂的字符串匹配时非常有用。
3.2.2 反向引用的使用和注意事项
反向引用允许我们引用之前的捕获组内容。在正则表达式中,反向引用通过 \数字 来实现,其中“数字”是捕获组的编号。例如, (\d+)\s+\1 将会匹配两个相同的数字序列,它们之间由至少一个空白字符分隔。
命名捕获组的反向引用使用 \k<name> 的方式。例如, (?<date>\d{4}-\d{2}-\d{2}) \k<date> 将匹配日期格式,并确保两次匹配的日期相同。
在使用反向引用时,需要注意的是,反向引用只能引用已捕获的组,并且在使用它们时,正则表达式的效率可能会受到一定的影响。
3.3 正则表达式选择与否定
3.3.1 分支选择的使用方法
分支选择允许我们匹配多个可能的模式之一。这是通过竖线 | 字符来实现的,表示“或”关系。例如, (foo|bar) 将会匹配"foo"或者"bar"。
分支选择是构建复杂匹配模式的一个强大工具,特别是在需要匹配多种可能的输入格式时。正确的使用分支选择能够显著提高正则表达式的灵活性。
3.3.2 否定前瞻和否定后顾的深入解析
否定前瞻和否定后顾是正则表达式中用于定义条件匹配的高级特性。否定前瞻使用 (?!(pattern)) 的形式,表示如果接下来的字符不匹配 pattern ,则进行匹配。否定后顾使用 (?<!pattern) 的形式,表示如果前面的字符不匹配 pattern ,则进行匹配。
例如, foo(?!bar) 将会匹配那些后面不紧跟"bar"的"foo";而 (?<!foo)bar 将会匹配那些前面不是"foo"的"bar"。这些特性在需要确保匹配不处于特定上下文中时特别有用。
以上对高级正则表达式技巧的讲解,仅是对这些功能的冰山一角。正确并熟练地运用这些高级技巧,将大大扩展你对字符串模式识别与处理的能力。接下来,我们将深入了解正则表达式的高级应用与优化。
4. 正则表达式的高级应用与优化
随着对正则表达式基础和高级技巧的掌握,我们可以进入正则表达式的高级应用与优化阶段。在这一章中,我们将探讨正则表达式中的预查与后顾、边界匹配以及调试与测试技巧,这些内容能帮助我们更好地理解和运用正则表达式,并有效提高代码编辑的效率。
4.1 正则表达式预查与后顾
正则表达式中的预查(lookahead)和后顾(lookbehind)提供了一种在不消耗字符的情况下检查字符串的方法。预查断言允许我们检查某个模式是否在目标字符串的前方存在,而不会实际从字符串中匹配这个字符。后顾断言则是检查某个模式是否在目标字符串的后方存在。
4.1.1 正向预查和正向后顾的规则
正向预查(positive lookahead)和正向后顾(positive lookbehind)使用 (?=pattern) 和 (?<=pattern) 这样的语法结构。例如,在查找句子中的“is”时,如果我们只想匹配那些位于单词“is”之前的“was”,我们可以使用正向预查 (?<=was )is 。这意味着“is”前面必须是“was”。
(?<=was )is
这将匹配字符串中的“is”,当且仅当“is”前面有“was ”。请注意,预查中的模式不会消耗任何字符,因此匹配结果中不会包含“was”。
正向后顾(positive lookbehind)则是在目标字符串的指定位置检查字符的出现,但不会移动字符串的匹配位置。使用 (?<=pattern) 语法表示正向后顾。例如:
(?<=foo)bar
这表示匹配“bar”,仅当“bar”前面有“foo”。
4.1.2 零宽断言在代码编辑中的应用
零宽断言在代码编辑中非常有用,特别是当你需要在某些条件下查找或替换文本时。例如,如果你正在处理一个日志文件,并想要查找所有在错误级别(ERROR)之后的特定模式,你可以使用正向预查:
ERROR (?=特定模式)
这将匹配所有的“ERROR”,后面紧跟“特定模式”,而不会消耗“特定模式”这个部分。
在代码编辑器或IDE中使用零宽断言时,通常可以通过快捷键或菜单来启用复杂的正则表达式搜索,包括预查和后顾。
4.2 正则表达式边界匹配
边界匹配是正则表达式中的一个重要概念,它能够帮助我们精确地定位匹配位置。边界匹配包括单词边界( \b )、行起始( ^ )和行结束( $ )。
4.2.1 单词边界和行起始/结束的匹配
单词边界 \b 用于确保匹配位于单词的开始或结束位置。它非常有用,当你需要匹配整个单词而不是单词的一部分时。例如:
\bword\b
这将匹配独立的“word”,而不是“sword”或“wordy”。
行起始符 ^ 匹配行的开始位置,而行结束符 $ 匹配行的结束位置。如果你正在搜索以“start”开头的行,你可以使用:
^start
如果你想找到以“end”结尾的行,可以使用:
end$
4.2.2 边界匹配的特殊情况及解决方案
在处理多行文本时,你可能会遇到一个文件中有多个行的场景。在这种情况下,匹配行开始和结束可能不如预期工作,因为正则表达式的多行模式并不是所有环境的默认设置。为了解决这个问题,你可以使用 (?m) 多行模式标志,它会让 ^ 和 $ 匹配每一行的开始和结束位置。
(?m)^start$
这样,无论文本中有多少行,“start”都会正确匹配每一行的开始。
4.3 正则表达式调试与测试技巧
调试正则表达式可能很复杂,特别是当它们变得越来越复杂时。幸运的是,大多数现代IDE和文本编辑器都提供了强大的正则表达式调试工具。
4.3.1 使用IDE内置工具进行正则表达式调试
现代IDE(如IntelliJ IDEA, VSCode等)内置了正则表达式测试面板。这些面板通常具有输入测试字符串、输入正则表达式、执行匹配和查看结果的功能。某些IDE允许你在实际文件上运行正则表达式,并直观地查看哪些字符串被匹配。
例如,在VSCode中,你可以使用“查找”功能,打开“查找”面板(Ctrl+F 或Cmd+F),选择“.*”标签页切换到正则表达式模式,然后输入你的表达式。IDE将自动突出显示匹配项,帮助你理解匹配如何发生。
4.3.2 测试正则表达式的方法和工具
除了IDE,还有许多独立的工具可用于测试正则表达式,比如RegExr和Regex101等。这些在线工具提供了简单的用户界面,允许你输入测试字符串和正则表达式,并实时显示匹配结果。
此外,一些编程语言提供了库和工具用于正则表达式的单元测试。比如Python的 re 模块可以编写测试用例,并通过断言来验证匹配结果是否符合预期。
总之,测试和调试正则表达式是确保它们正确执行的关键步骤,无论是在简单的文本处理还是复杂的代码重构中。通过熟悉和利用IDE内置工具及在线服务,你可以大幅提升正则表达式的使用效果和效率。
5. 正则表达式的高级查找替换功能
5.1 正则表达式查找和替换操作
5.1.1 查找替换界面的介绍
在JetBrains IDEs中,查找替换功能是文本编辑和代码维护中不可或缺的一部分。查找替换界面通常可以通过快捷键 Ctrl + R (在Windows/Linux系统中)或 Cmd + R (在macOS系统中)快速访问。打开的查找替换对话框提供了多个选项,以便进行更精确的搜索和替换操作。
查找替换对话框分为几个主要区域: - 查找 :在这里输入要查找的文本或正则表达式。 - 替换 :在这里输入替换文本或构建正则表达式以定义替换逻辑。 - 搜索范围 :定义搜索将在哪些文件或范围中进行(例如,当前文件、选定文本、项目中的所有文件等)。 - 选项 :允许用户启用正则表达式、区分大小写、全词匹配等选项。
此外,查找替换对话框中还可能包含上下文菜单,允许用户访问更复杂的查找替换选项,如查找和替换下一个/所有匹配项,或者只在选中文本中进行查找替换。
5.1.2 替换操作中的特殊变量和模式
在进行查找替换操作时,可以使用一些特殊的变量和模式来增强替换的灵活性和功能性。以下是一些常用的特殊变量和模式:
-
$1, $2, ..., $9:在替换字段中使用反向引用,其中$1引用第一个捕获组的内容,$2引用第二个捕获组的内容,依此类推。 -
$0:引用与整个匹配相对应的捕获组(即整个匹配的文本)。 -
$$:表示字面上的美元符号($)。 -
$&:表示完整的匹配文本。 - `$``:表示匹配文本前的所有文本(匹配的左侧文本)。
-
$':表示匹配文本后的所有文本(匹配的右侧文本)。 -
$+:表示最后一个分组(即第9个分组)捕获的内容。
举一个简单的例子,在重构代码时,如果你想要将所有出现的变量名 oldVar 替换为 newVar ,你可以使用如下的查找和替换模式:
- 查找内容:
oldVar - 替换内容:
newVar - 启用正则表达式
- 确保区分大小写未被选中,以便替换所有大小写的变量名变体
5.2 正则表达式多行模式应用
5.2.1 多行模式的工作机制
多行模式( m 修饰符)改变了正则表达式引擎对 ^ 和 $ 的处理方式。在没有多行模式的情况下, ^ 匹配字符串的开始,而 $ 匹配字符串的结束。启用多行模式后,这两个锚点分别匹配每一行的开始和结束,而不是整个字符串的开始和结束。
这对于处理多行文本的查找和替换尤其有用。例如,如果你想在每行的开头添加一个注释标记 // ,你可以使用以下正则表达式:
- 查找内容:
^ - 替换内容:
// - 启用正则表达式
- 启用多行模式
这将在每行的开头添加注释,而不管它们是否是原始字符串的第一行。
5.2.2 多行模式下的常见操作案例
一个常见的多行模式操作是在日志文件中提取信息。假设你有一个日志文件,每条日志都以时间戳开始,位于行的开头。如果你想要提取所有时间戳并将其放在单独的文件中,可以使用以下步骤:
- 使用正则表达式
^\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}来查找匹配时间戳的行。 - 在多行模式下,
^将会匹配每行的开始。 - 将匹配到的时间戳复制到新的文件或替换到其他格式中。
5.3 正则表达式选项调整
5.3.1 全局搜索和匹配选项的设置
在进行复杂的查找替换操作时,正确设置搜索和匹配选项至关重要。全局搜索选项通常包括:
- 区分大小写 :此选项控制搜索是否对字母大小写敏感。
- 正则表达式 :启用或禁用正则表达式匹配模式。
- 使用通配符 :允许使用特定的通配符字符进行模式匹配。
- 匹配换行符 :允许
.匹配换行符,通常在启用正则表达式时使用。
匹配选项 ,如 ^ 和 $ ,包括:
- 多行模式 :如前所述,此选项改变
^和$的含义。 - 单行模式 (有时称为
dotall模式):使.匹配包括换行符在内的所有字符。
5.3.2 案例:调整选项优化搜索与替换效率
想象一下,你负责维护一个大型项目,该项目使用了一种旧的命名约定,你需要将其统一为新的命名约定。假设新的命名约定要求变量名以小写字母开头,后跟一个大写字母。例如,变量 MyVariable 应该改为 myVariable 。
使用正则表达式查找和替换功能,你可以:
- 打开查找替换对话框。
- 在查找字段中输入
([a-z])([A-Z]),并启用正则表达式选项。 - 在替换字段中输入
$1$2,这将移除大写字母前的小写字母。 - 启用多行模式和全局搜索,以及在必要时启用区分大小写。
- 执行替换操作。
通过合理设置这些选项,你可以高效且精确地进行复杂的文本替换,确保项目中所有的变量名都符合新的约定。通过这种方法,你不仅提高了代码质量,也减少了手动查找和替换的错误和遗漏。
简介:JetBrains提供的集成开发环境如IntelliJ IDEA、PHPStorm、WebStorm、PyCharm和CLion等支持强大的正则表达式功能,使开发者能够高效地在代码中执行复杂的查找和替换操作。本资源旨在介绍如何利用正则表达式在JetBrains IDEs中进行高效的文本处理,包括启用正则表达式模式、使用基础匹配和量词、创建分组与引用、运用选择与否定、预查与后顾、边界匹配、转义字符、查找和替换、多行模式、调试与测试、预览和高亮显示匹配项,以及调整正则表达式选项等技巧。熟练掌握这些技术能够帮助开发者提升编码效率,优化代码质量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









