









距离相关系数用来判断两个变量是否独立,值域为[0,2]
- 值接近0,两个变量正相关
- 值接近1,两个变量无关
- 值接近2,两个变量负相关
距离相关系数可以参考:https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.correlation.html
维基百科解释:https://en.wikipedia.org/wiki/Distance_correlation
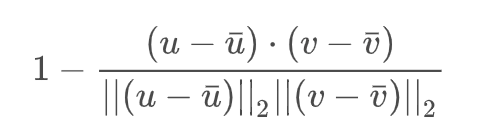
python中的使用也很简单:
from scipy.spatial.distance import correlation
if __name__ == '__main__':
corr_values = correlation(
[1, 2, 3, 4, 5],
[5, 4, 3, 2, 5],
)
print(corr_values)
输出1.242535625036333,说明两个序列负相关
特征筛选的示例代码
import pandas as pd
from sklearn.datasets import make_classification
def distance_corr(x_data: pd.DataFrame, y_data: pd.Series) -> pd.DataFrame:
# 距离相关系数
from scipy.spatial.distance import correlation
dis_series = pd.Series(0.0, index=x_data.columns)
for col_name, values in x_data.iteritems():
dis_series[col_name] = correlation(values, y_data)
return pd.DataFrame(dis_series)
if __name__ == '__main__':
value_x, value_y = make_classification(n_samples=1000, n_classes=4, n_features=10, n_informative=8)
df_x = pd.DataFrame(value_x, columns=['f_1', 'f_2', 'f_3', 'f_4', 'f_5', 'f_6', "f_7", "f_8", "f_9", "f_10"])
df_y = pd.Series(value_y)
# 下面是筛选单变量特征
feature_df = distance_corr(df_x, value_y) # 距离相关系数
for col_index, value in feature_df.iterrows():
print(col_index, ":", value[0])
















 5060
5060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











