






在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件
默认情况下,HiveSQL的底层基于MR程序运行。在分析HiveSQL的操作原理之前,我们首先来看一下实现某些SQL操作的MR程序的基本原理。
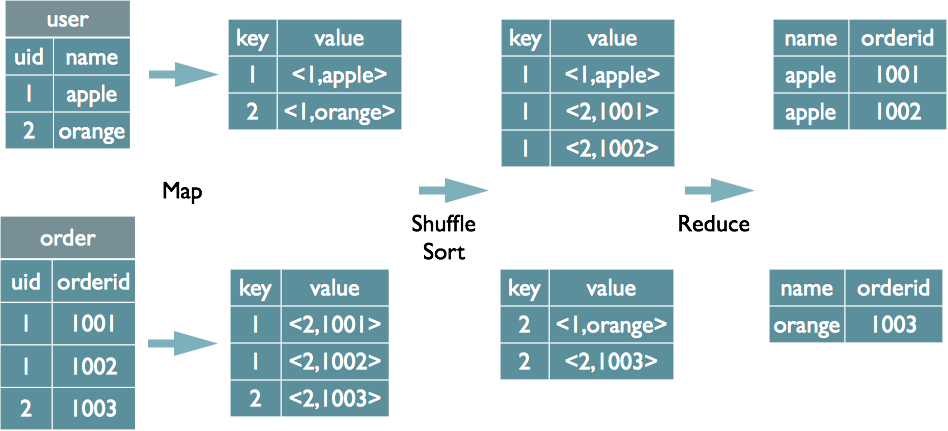
MR中联接的实现原理
从命令中选择u.name,o.orderid o在o.uid = u.uid上加入用户u;
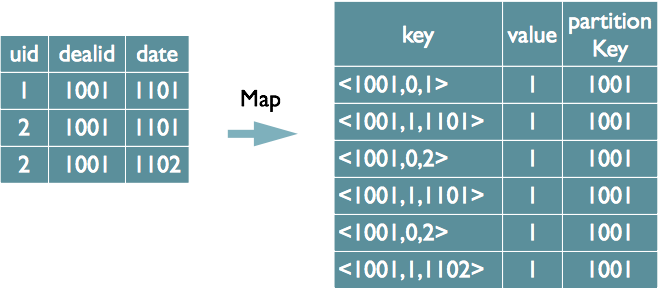
在地图的输出值中标记不同表中的数据,并在还原阶段根据标记确定数据源。 MapReduce的过程如下:
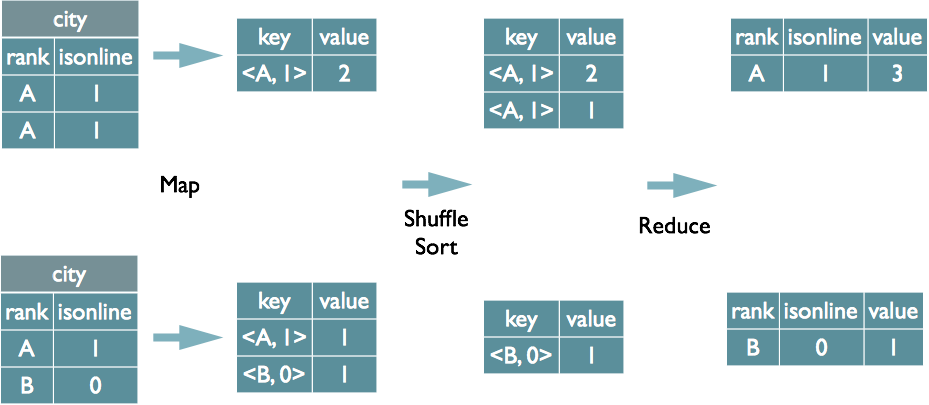
MR中分组依据的实现原理
从等级,等位线城市中选择等级,等位线,计数(*);
将GroupBy字段组合到地图的输出键值中,并使用MapReduce排序在reduce阶段保存LastKey来区分不同的键。 MapReduce的过程如下(当然,这里只是为了说明Reduce方面的非哈希聚合过程):
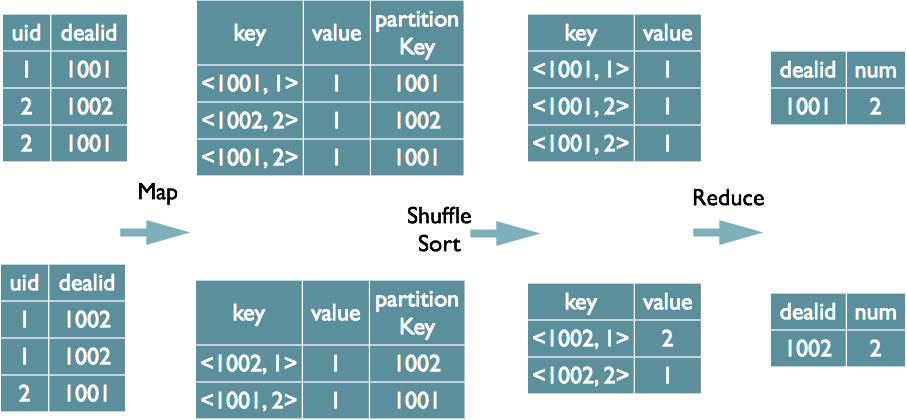
MR中distinct的实现原理
选择交易编号,按交易编号对订单组计数(不同的uid);
当只有一个不同的字段时,如果在Map阶段不考虑Hash GroupBy,则只需将GroupBy字段和Distinct字段组合为地图输出键,请使用mapreduce排序,然后将GroupBy字段用作reduce键,并在reduce阶段中保存LastKey以完成重复数据删除。
 di>
di>
如果存在多个不同的字段,例如以下SQL:
从交易组中按交易编号选择交易编号,计数(不同的uid),计数(不同的日期);
有两种方法可以实现:
1)如果您仍然遵循上面不同字段的方法,即下图所示的实现,则不能根据uid和date分别进行排序,也不能使用LastKey进行重复数据删除。在reduce阶段,您仍然需要在内存中传递Hash。重复数据删除。

2)在第二种实现中,所有不同的字段都可以编号。每行数据生成n行数据,然后将对相同的字段分别进行排序。在这种情况下,只需要在reduce阶段记录LastKey即可删除重复项。
此实现很好地利用了MapReduce排序,在减少阶段节省了重复数据删除的内存消耗,但是缺点是增加了随机数据的数量。
应该注意的是,当生成缩减值时,其他唯一数据行的值字段可以为空,但第一个唯一字段所在的行除外。
将SQL转换为MapReduce的过程
了解了MapReduce实现的SQL的基本操作之后,让我们看一下Hive如何将SQL转换为MapReduce任务。整个编译过程分为六个阶段:
Antlr定义SQL语法规则,完成SQL词法,语法分析,并将SQL转换为抽象语法树AST Tree
遍历AST树以抽象基本查询单元QueryBlock
遍历QueryBlock并将其转换为运算符树
逻辑层优化器执行OperatorTree转换,合并不必要的ReduceSinkOperator,并减少随机数据的数量
遍历OperatorTree并转换为MapReduce任务
物理层优化器转换MapReduce任务并生成最终执行计划
为了详细说明将SQL转换为MapReduce的过程,这里以一个简单的SQL为例,SQL包含一个子查询,最后将数据写入表中
SQL生成AST树
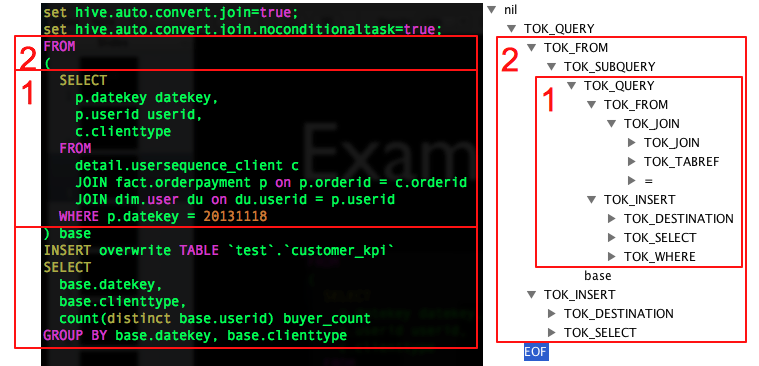
生成的AST树在下图的右侧生成(使用Antlr Works生成,Antlr Works是用于编写Antlr提供的语法文件的编辑器)。该图仅扩展了骨骼的几个节点,但没有完全扩展。
子查询1/2对应于右侧的前两个部分。
 3描述>
3描述>
注意,内部子查询还会生成一个TOK_DESTINATION节点。请参见上面的SelectStatement的语法规则,此节点是在语法重写中专门添加的节点。原因是Hive中的所有查询数据都将存储在临时HDFS文件中,无论是中间子查询还是查询的最终结果,Insert语句最终都会将数据写入HDFS表所在的目录。
Hive使用类似SQL的查询语言HQL(Hive查询语言)。它们的操作语言类似,用于创建表,创建数据库以及添加,删除和修改查询。
除此之外,基本上没有相似之处。
除了hql的相似语法外,内核,存储位置,是否可以更新,是否有索引,执行延迟,可伸缩性和数据大小也有所不同。
Hive专为数据仓库而设计。
存储位置:Hive在Hadoop上; Mysql将数据存储在设备或本地系统中
数据更新:Hive不支持数据的重写和添加,它已经确定何时加载;数据库可以是CRUD
索引:没有索引的配置单元,每次扫描所有数据,底层为MR,并行计算,适合大量数据; MySQL具有索引,适用于在线查询数据
执行:Hive的底层是MapReduce; MySQL的最底层是执行引擎
可扩展性:蜂巢:数据量大,可扩展性好; MySQL:相对较少
因此Mysql可以进行在线业务,而Hive仅可以进行离线分析业务。
参考:https://www.cnblogs.com/csguo/p/7553022.html















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









