









介紹
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。

版本声明
CenOS:7 阿里云服务器 关闭防火墙;
JDK:1.8;
Elasticsearch:7.6.1;
Kibana:7.6.1;
文章推荐
es(Elasticsearch)安装使用(01es安装篇)_少年ing的博客-CSDN博客
es(Elasticsearch)客户端Kibana安装使用(02Kibana安装篇)_少年ing的博客-CSDN博客
es(Elasticsearch)安装使用(03ik分词器安装篇)_少年ing的博客-CSDN博客
es(Elasticsearch)客户端Elasticsearch-head安装使用(04Elasticsearch-head安装篇)_少年ing的博客-CSDN博客
安裝
1.下载
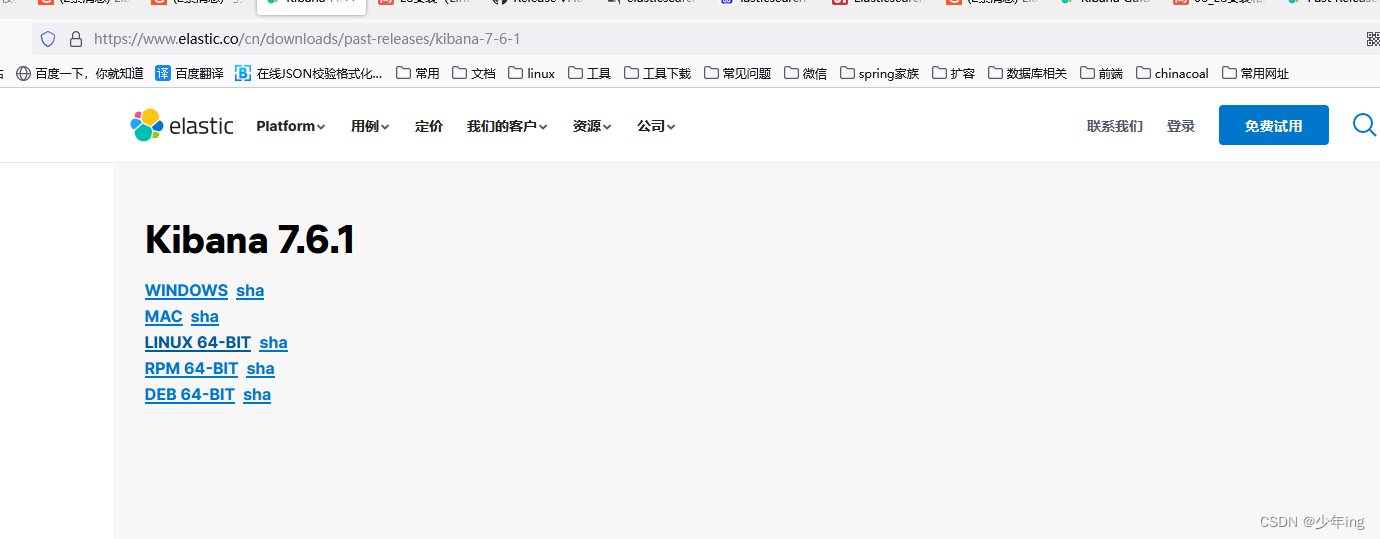
注意:Elasticsearch和Kibana的版本需要对应。
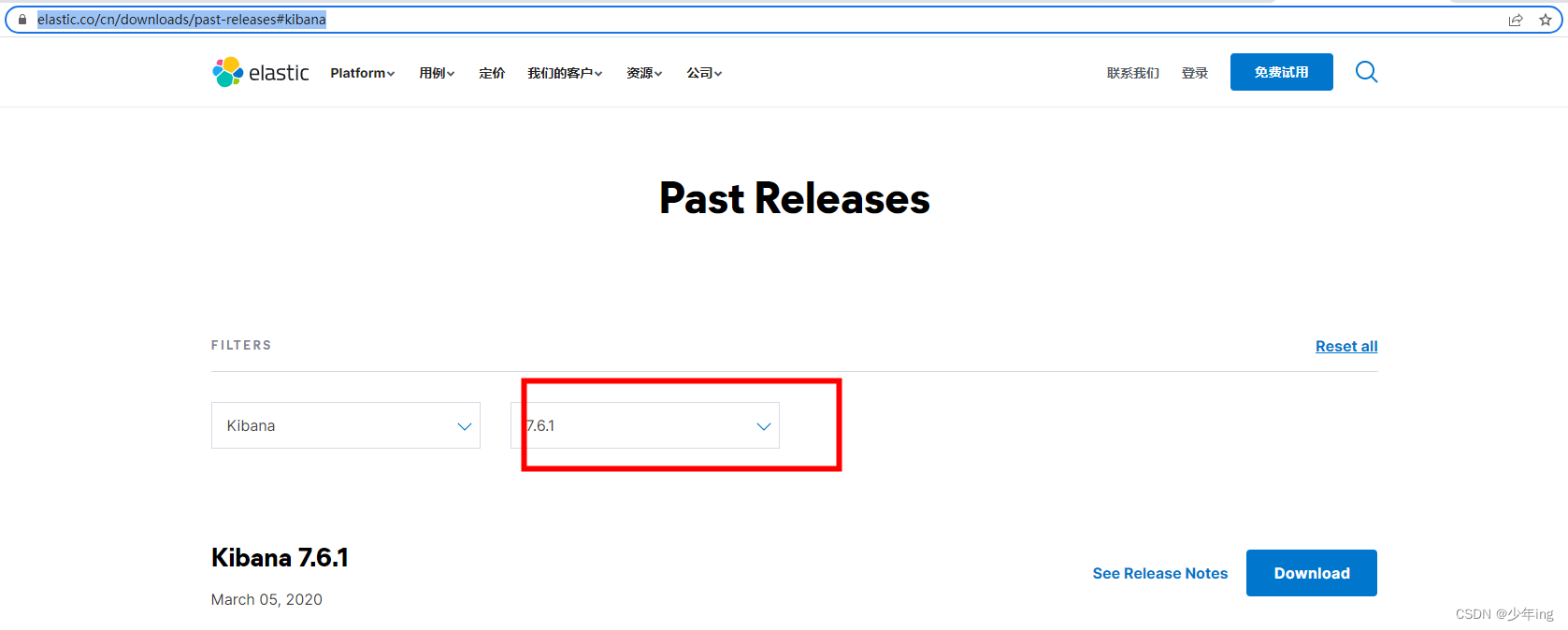
下载地址
https://www.elastic.co/cn/downloads/past-releases#kibana
某云盘下载
链接:https://pan.baidu.com/s/10KlzfDsSTHP_s_p1CtTAvg
提取码:ta4d
2.安装
因再es安装目录 所以用es用户
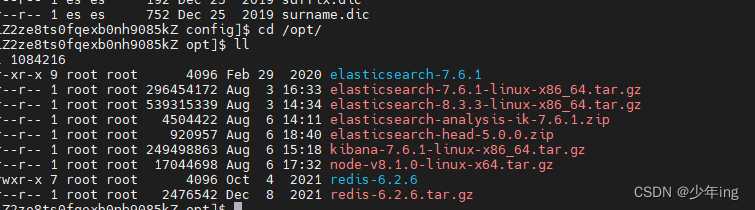
1)下载Kibana放之/opt目录中
2)解压kibana压缩包到es安裝目录:
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz -C /usr/local/elasticsearch-7.6.1/
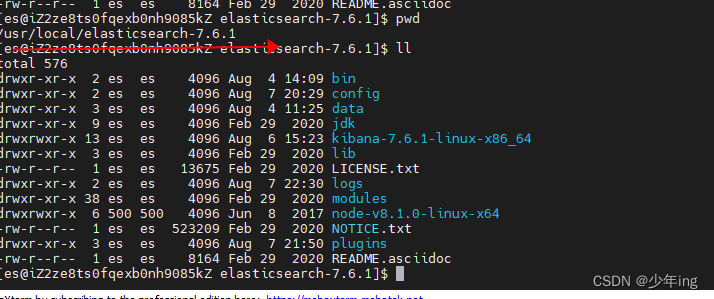
3)进入/usr/local/elasticsearch-7.6.1/kibana-7.6.1-linux-x86_64/config目录
cd config/

4)使用vim编辑器:
vim kibana.yml
server.port: 5601
server.host: "es的ip" # 此处不能写“localhost”,否则访问不了kibana
elasticsearch.hosts: ["http://es的ip:9200"] #这里是elasticsearch的访问地址

# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "0.0.0.0"
# Enables you to specify a path to mount Kibana at if you are running behind a proxy.
# Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath
# from requests it receives, and to prevent a deprecation warning at startup.
# This setting cannot end in a slash.
#server.basePath: ""
# Specifies whether Kibana should rewrite requests that are prefixed with
# `server.basePath` or require that they are rewritten by your reverse proxy.
# This setting was effectively always `false` before Kibana 6.3 and will
# default to `true` starting in Kibana 7.0.
#server.rewriteBasePath: false
# The maximum payload size in bytes for incoming server requests.
#server.maxPayloadBytes: 1048576
# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://esip:9200"]
# When this setting's value is true Kibana uses the hostname specified in the server.host
# setting. When the value of this setting is false, Kibana uses the hostname of the host
# that connects to this Kibana instance.
#elasticsearch.preserveHost: true
# Kibana uses an index in Elasticsearch to store saved searches, visualizations and
# dashboards. Kibana creates a new index if the index doesn't already exist.
kibana.index: ".kibana"
# The default application to load.
#kibana.defaultAppId: "home"
# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
#elasticsearch.username: "kibana"
#elasticsearch.password: "pass"
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key
# Optional settings that provide the paths to the PEM-format SSL certificate and key files.
# These files are used to verify the identity of Kibana to Elasticsearch and are required when
# xpack.security.http.ssl.client_authentication in Elasticsearch is set to required.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key
# Optional setting that enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]
# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full
# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500
# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000
# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ]
# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {}
# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
#elasticsearch.shardTimeout: 30000
# Time in milliseconds to wait for Elasticsearch at Kibana startup before retrying.
#elasticsearch.startupTimeout: 5000
# Logs queries sent to Elasticsearch. Requires logging.verbose set to true.
#elasticsearch.logQueries: false
# Specifies the path where Kibana creates the process ID file.
#pid.file: /var/run/kibana.pid
# Enables you specify a file where Kibana stores log output.
#logging.dest: stdout
# Set the value of this setting to true to suppress all logging output.
#logging.silent: false
# Set the value of this setting to true to suppress all logging output other than error messages.
#logging.quiet: false
# Set the value of this setting to true to log all events, including system usage information
# and all requests.
#logging.verbose: false
# Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to 5000.
#ops.interval: 5000
# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English - en , by default , Chinese - zh-CN .
#i18n.locale: "en"
启动Kibana
1、进入kibana安装 bin目录
cd ./bin/
2、前台启动 (关闭服务 关闭窗口 或者ctrl+c)
./kibana
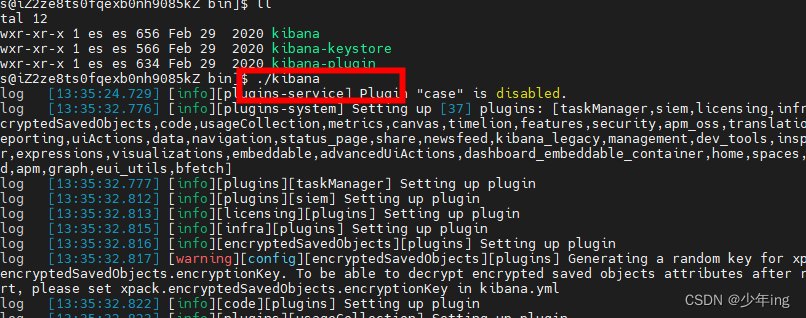
后台启动
1. nohup ./bin/kibana &
关闭服务 根据端口查进行 然后 kill掉
lsof -i:5601 会出多个 kill 第一

后台关闭

页面访问
ip:5601
#查询所有索引
GET /_cat/indices?v#查询健康
GET /_cluster/health
#单机情况下是不需要设置副本分区数。调整副本分区数为0
PUT _settings
{
"index" : {
"number_of_replicas" : 0
}
}#查询原因
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason#返回未分配索引每个分片的详情和未分配的原因,
GET /_cluster/allocation/explain?pretty#查看设置
GET /newsinfo/_settings
#重置分片
PUT /newsinfo/_settings
{"number_of_replicas": 0}
#重新分配
PUT /newsinfo/_settings
{"number_of_replicas": 2}#查看分词器 默认
POST _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
#ik ik_smart 最少切分算法
POST _analyze
{
"analyzer":"ik_smart",
"text":"我是中国人"
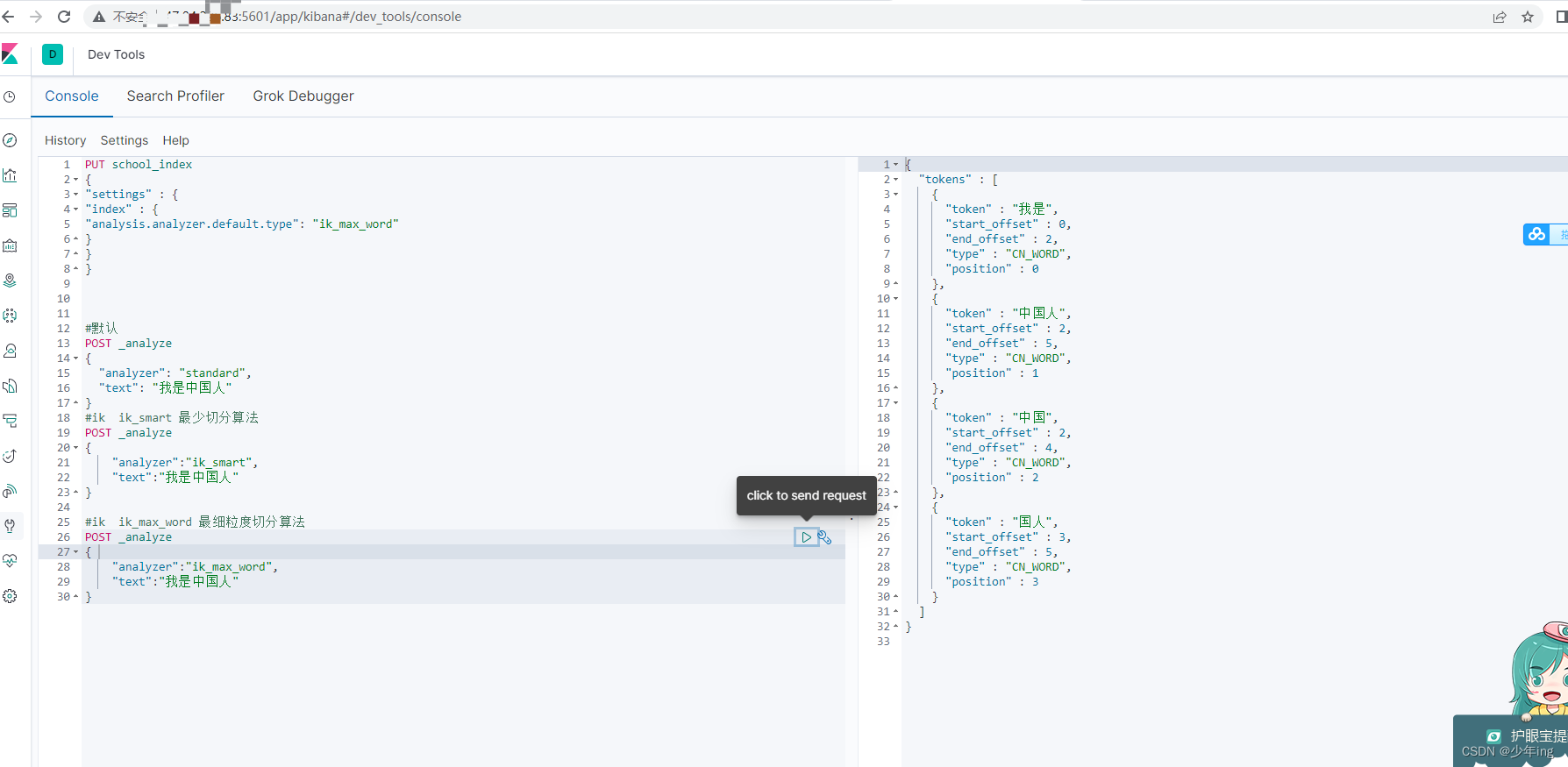
}#ik ik_max_word 最细粒度切分算法
POST _analyze
{
"analyzer":"ik_max_word",
"text":"我是中国人"
}#设置ik分词器
PUT school_index
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
问题
问题1.报错 listen EADDRNOTAVAIL: address not available
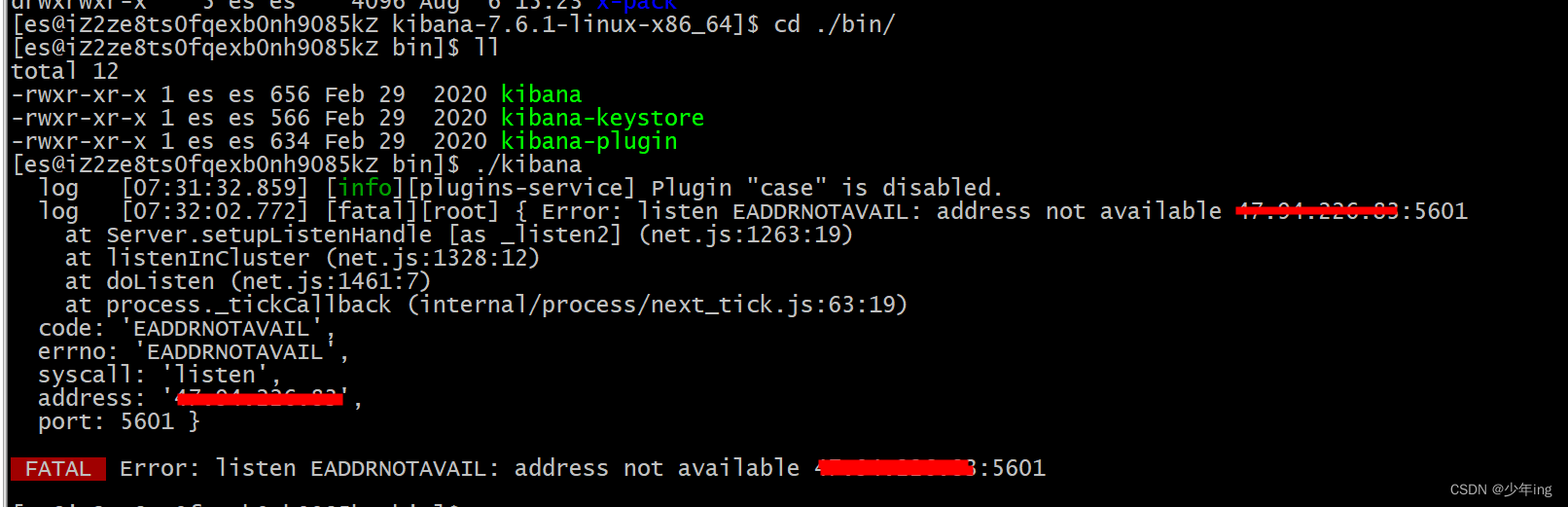
解决 因为是用的阿里运服务器
因为用的是云虚拟机,所以这里的123.57.251.57是外网ip,我们应该用内网ip才行。
但是如果写localhost的话,虽然不会报错,5601端口也是正常启动,但是你访问5601端口会被拒绝。
把server.host改为0.0.0.0就能启动和顺利访问到了。
参照 运行/bin/kibana报错FATAL Error: listen EADDRNOTAVAIL 123.57.251.57:5601 - yjssjm - 博客园
2.外网访问 记得打开 阿里云 安全组
3.重启kibana 会把es服务停止 不知道为啥
kibana使用
包括ik分词器使用
#查询所有索引
GET /_cat/indices?v#创建索引
PUT user
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text"
},
"name2" : {
"type" : "keyword"
},
"name3" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"hobby" : {
"type" : "text"
}
}
}
}#查询索引 类型
GET user/_mapping#查询索引下所有文档
GET user/_search#添加文档
PUT user/_doc/1
{
"age": 18,
"name": "张三风",
"name2": "张三风",
"name3": "张三风",
"hobby": "爱吃饭,爱钓鱼"
}PUT user/_doc/2
{
"age": 18,
"name": "张三",
"name2": "张三",
"name3": "张三",
"hobby": "爱吃饭,爱钓鱼,爱祖国"
}#按条件查询 类型 keyword查询时条件只能全匹配 text全文索引查询,查询时会先分词,然后用分词去匹配查询
#keyword+text类型,一个字段两种类型,可以全匹配,也可以全文索引查询
# keyword
GET user/_search
{
"query": {
"term": {
"name2": {
"value": "张三"
}
}
}
}# text 使用match
GET user/_search
{
"query": {
"match": {
"name": "张三"
}
}
}
#keyword+text查询例子,name3(text+keyword)的查询。
GET user/_search
{
"query": {
"term": {
"name3.keyword": {
"value":"张三"
}
}
}
}
#keyword+text查询例子 当想用全文索引查询时,用match
GET user/_search
{
"query": {
"match": {
"name3": "张三"
}
}
}#查看 默认分词器
POST _analyze
{
"analyzer": "standard",
"text": "爱祖国"
}
#ik ik_smart 最少切分算法
POST _analyze
{
"analyzer":"ik_smart",
"text":"爱祖国"
}#ik ik_max_word 最细粒度切分算法
POST _analyze
{
"analyzer":"ik_max_word",
"text":"爱祖国"
}
#创建索引的时候,text类型如果没指定使用分词器,就会默认内置的分词器,所以使用ik分词器时,创建索引时需要指定。
PUT user2
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer" : "ik_max_word"
},
"name2" : {
"type" : "keyword"
},
"name3" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"hobby" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer" : "ik_max_word"
}
}
}
}#把user的数据复制到user2。
POST _reindex
{
"source":{
"index":"user"
},
"dest":{
"index":"user2"
}
}
#次查询user “爱祖国”,得到2数据 因采用默认分词器。
GET user/_search
{
"query": {
"match": {
"hobby": "爱祖国"
}
}
}
#再次查询user2 “爱祖国”,得到一条想要的数据,没有多余数据。证明ik分词在索引中生效了。
GET user2/_search
{
"query": {
"match": {
"hobby": "爱祖国"
}
}
}
#查询健康
GET /_cluster/health
#单机情况下是不需要设置副本分区数。调整副本分区数为0
PUT _settings
{
"index" : {
"number_of_replicas" : 0
}
}#查询原因
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason#返回未分配索引每个分片的详情和未分配的原因,
GET /_cluster/allocation/explain?pretty#查看设置
GET /newsinfo/_settings
#重置分片
PUT /newsinfo/_settings
{"number_of_replicas": 0}
#重新分配
PUT /newsinfo/_settings
{"number_of_replicas": 2}#查看分词器 默认
POST _analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
#ik ik_smart 最少切分算法
POST _analyze
{
"analyzer":"ik_smart",
"text":"我是中国人"
}#ik ik_max_word 最细粒度切分算法
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}#设置ik分词器
PUT school_index
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
参照
CentOS7下安装ElasticSearch7.6.1详细教程(单机、集群搭建)_@来杯咖啡的博客-CSDN博客_centos7安装elasticsearch
















 4527
4527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









