






在嵌入式linux内核中,链表是一种常见的重要数据结构,它可以动态地进行存储分配,根据需要开辟内存单元,还可以方便地实现数据的增加和删除。链表中的每个元素都由两部分组成:数据域和指针域。
其中,数据域用于存储数据元素的信息,指针域用于存储该元素的直接后继元素的位置。其整体结构就是用指针相链接起来的线性表,如图1.1所示。

图1.1 链表结构
由图中,大家可以清楚地看到,每个链表都有一个头指针Head,其用于指示链表中第一个节点的存储位置。之后,链表由第一个节点指向第二个节点,依此类推。链表的后一个数据元素由于没有直接后继节点,因此其节点的指针为空(NULL)。本文主要介绍的是单项链表!
1、单链表的组织与存储
单向链表的每个节点中除信息域以外还有一个指针域,用来指向其后续节点,其后一个节点的指针域为空(NULL)。
单向链表由头指针惟一确定,因此单向链表可以用头指针的名字来命名,头指针指向单向链表的第一个节点。
在用C语言实现时,首先说明一个结构类型,在这个结构类型中包含一个(或多个)信息成员以及一个指针成员如下所示:
typedef struct _link_node
{
element_type data; /* element_type为有效数据类型*/
struct _link_node *next;
} link_node;
typedef link_node *link_list;
链表结构中包含指针型的结构成员,类型为指向相同结构类型的指针。根据C语言的语法要求,结构的成员不能是结构自身类型,即结构不能自己定义自己,因为这样将导致一个无穷的递归定义,但结构的成员可以是结构自身的指针类型,通过指针引用自身这种类型的结构。
2、单链表常见操作
(1)节点初始化
由于链表是一种动态分配数据的数据结构,因此单链表中各个节点的初始化通常使用malloc()函数,把节点中的next指针赋为NULL,同时再把数据域的部分初始化为需要的数值,通常使用memset()函数。
int init_link(link_list *list)
{
/*用malloc分配函数分配节点*/
*list = (link_list)malloc(sizeof(link_node));
/*若分配失败,返回*/
if (!list)
{
return -1;
}
/*初始化链表节点的数据域*/
memset(&((*list)->data), 0, sizeof(element_type));
/*初始化链表节点的指针域*/
(*list)->next = NULL;
return 0;
}
(2)数据查询
在操作链表时,通常需要检查在链表中是否存在某种数据,这时,可以通过顺序遍历链表来取得所需要的元素。
int get_element(link_list list, int i, element_type *elem)
{
/* list为带头节点的单链表的头指针 */
/*当第i个元素存在时,其值赋给elem并返回*/
link_list p = NULL;
int j = 0;
/*初始化,指向链表的第一个节点,j为计数器*/
p = list->next;
/* 为防止i过大,通过判断p是否为空来确定是否到达链表的尾部 */
while ((j++ < i) && (p = p->next));
/* 若第i个元素不存在,返回 */
if (!p || (j <= i))
{
return -1;
}
/*取得第i个元素*/
*elem = p->data;
return 0;
}
(3)链表的插入与删除
链表的插入与删除是链表中常见的操作,也是能体现链表灵活性的操作。
在单向链表中插入一个节点要引起插入位置前面节点的指针的变化,如图1.2所示。
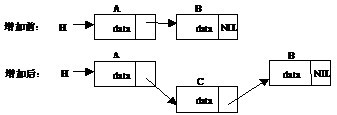
图1.2 链表的节点插入过程
由图中可以看出,在链表中增加一个节点会依次完成如下操作。
●创建新节点C
●使C指向B:C→next = A→next。
●使A指向C:A→next = C。
int link_insert(link_list list, int i, element_type elem)
{
/* list为带头节点的单链表的头指针 */
/* i为要插入的元素位置,elem为要插入的元素*/
link_list p = list, new_node;
int j = 0;
/* 找到第i位 */
while ((j++ < i) && (p = p->next));
if (!p || (j <= i))
{
return 0;
}
/* 初始化链表节点 */
new_node = (link_list)malloc(sizeof(link_node));
new_node->data = elem;
/* 将s插入链表,并修改原先的指针 */
new_node->next = p->next;
p->next = new_node;
return 1;
}
删除的过程也类似,如图1.3所示。
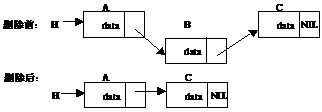
图1.3 链表的节点删除过程
同样,链表中元素的指针会依次有以下变化。
●使A指向C:A→next = B->next。
●使B指向NULL:B->next = NULL 或(若不再需要该节点)释放节点B。
(4)其他操作
将几个单链表合并也是链表操作中的一个常见的操作之一。
下面将两个单链表根据标识符ID顺序合并成一个单链表。在合并的过程中,实际上新建了一个链表,然后将两个链表的元素依次进行比较,并且将ID较小的节点插入到新的链表中。如果其中一个链表的元素已经全部插入,则另一个链表的剩余操作只需顺序将剩余元素插入即可。
该过程如图1.4所示:
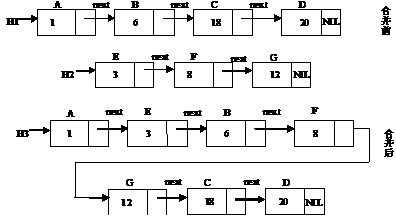
图1.4 链表的合并过程
void merge_list(link_list list_a, link_list list_b, link_list *list_c)
{
/* 合并单链表list_a和list_b到list_c中 */
link_list pa, pb, pc;
/* 初始化pa、pb,指向链表的第一个元素 */
pa = list_a->next;
pb = list_b->next;
*list_c = pc = list_a;
/* 判断两个链表是否到达末尾 */
while (pa && pb)
{
/*若链表list_a的元素小于链表list_b的元素,
则把链表list_a的元素插入到list_c中*/
if (less_equal_list(&pa->data, &pb->data))
{
pc->next = pa;
pc = pa;
pa = pa->next;
}
/* 若链表list_a的元素大于链表list_b的元素,
则把链表list_b的元素插入到list_c中*/
else
{
pc->next = pb;
pc = pb;
pb = pb->next;
}
}
/* 将还未到达末尾的链表连入list_c中,若两个链表都到达末尾,pc->next为NULL*/
pc->next = pa?pa:pb;
}
热点链接:















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









